




聚集函数
在GaussDB数据库中,数据库聚集函数是指用于对数据库中的数据进行聚合计算的函数。这些函数通常用于处理大量数据,例如表中的行数据。
以下是一些常见的数据库聚集函数:
--sum(expression)
--描述:所有输入行的expression总和。
--返回类型: 通常情况下输入数据类型和输出数据类型是相同的,但以下情况会发生类型转换:
--对于SMALLINT或INT输入,输出类型为BIGINT。
--对于BIGINT输入,输出类型为NUMBER 。
--对于浮点数输入,输出类型为DOUBLE PRECISION。
--max(expression)、min(expression)
--描述:所有输入行中expression的最大值、最小值。
--参数类型:任意数组、数值、字符串、日期/时间类型。
--返回类型:与参数数据类型相同
--avg(expression)
--描述:所有输入值的均值(算术平均)。
--返回类型:对于任何整数类型输入,结果都是NUMBER类型。对于任何浮点输入,结果都是DOUBLE PRECISION类型。否则和输入数据类型相同。
--count(expression) 描述:返回表中满足expression不为NULL的行数。 count(*) 描述:返回表中的记录行数。
--返回类型:BIGINT
select sum(column1),max(column1),min(column1),avg(column1),count(column1),count(*) from test1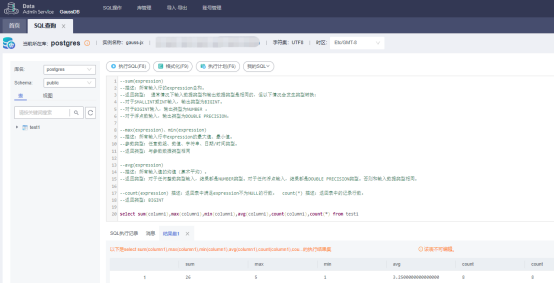
--array_agg(expression)
--描述:将所有输入值(包括空)连接成一个数组。
--返回类型:参数类型的数组
--string_agg(expression, delimiter)
--描述:将输入值连接成为一个字符串,用分隔符分开。
--返回类型:和参数数据类型相同。
select array_agg(column1),string_agg(column1,'|') from test1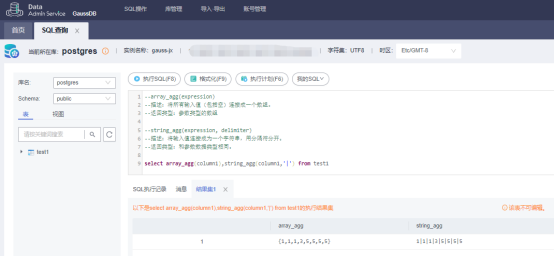
--listagg(expression [, delimiter]) WITHIN GROUP(ORDER BY order-list)
--描述:将聚集列数据按WITHIN GROUP指定的排序方式排列,并用delimiter指定的分隔符拼接成一个字符串。
--expression:必选。指定聚集列名或基于列的有效表达式,不支持DISTINCT关键字和VARIADIC参数。
--delimiter:可选。指定分隔符,可以是字符串常数或基于分组列的确定性表达式,缺省时表示分隔符为空。
--order-list:必选。指定分组内的排序方式。
--返回类型:text
select column1,listagg(column2,'|') within group(order by column1) from test1 group by column1;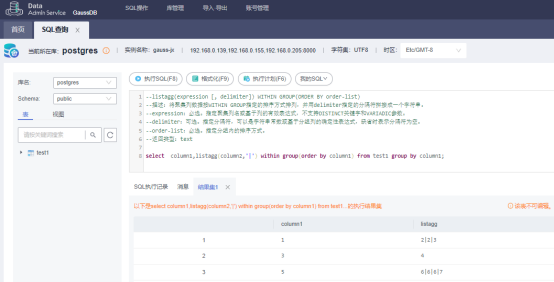
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
