




大家好,今天和大家聊聊 REPMGRD 选举机制。
我们本次采用源码分析和动手实验的2种方式才逐步的理解REPMGRD 这个后台的核心进程:
我们直接从github上找到源码的连接: https://github.com/EnterpriseDB/repmgr/blob/master/repmgrd-physical.c
repmgrd-physical.c 中有几个重要函数:
主要驻留进程:
monitor_streaming_primary: 主节点启动repmgrd 后台驻留进程
monitor_streaming_standby : 从节点启动repmgrd 后台驻留进程
monitor_streaming_witness : witness节点启动repmgrd 后台驻留进程
主要功能性函数:
do_primary_failover(void): standby 节点上failover 切换触发函数方法
do_upstream_standby_failover(): cascade standby 节点上切换触发函数方法
do_election : 描述了具体的选举的机制
promote_self(void): 提升主库的函数,这个函数中会调用大家熟悉的repmgr.conf中的参数 promote_command
follow_new_primary: 从节点attach 新的主库,这个函数中会调用大家熟悉的repmgr.conf中的参数 follow_command
我们先来看看repmgrd 这个每个角色是如何运行的:
当我们执行repmgrd -f repmgr.conf 的时候,会进入到 rpmgrd.c的主函数main:
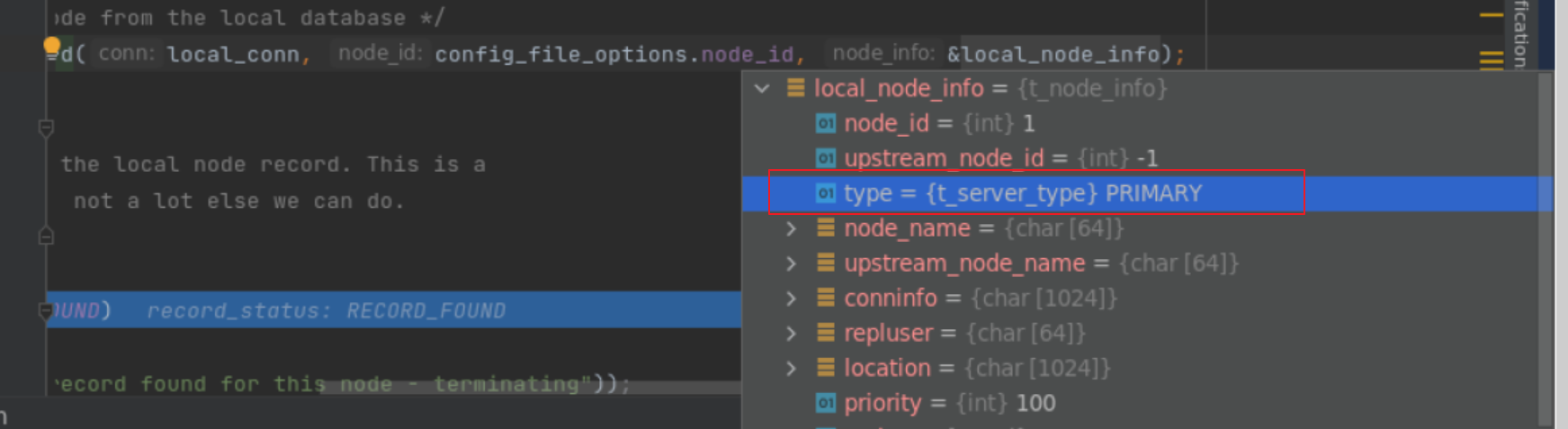
获得local 节点的信息:

很重要的一个信息是数据库的角色获取, PRIMARY OR STANDBY ? 我们是在主库上启动的 repmgrd, 获取到的local_node_info = PRIMARY:
启动监控程序: 调用函数start_monitoring:
状态机处理: 根据之前我们从数据库中获得的local_node_info.type来判断进入到不同的分支函数.
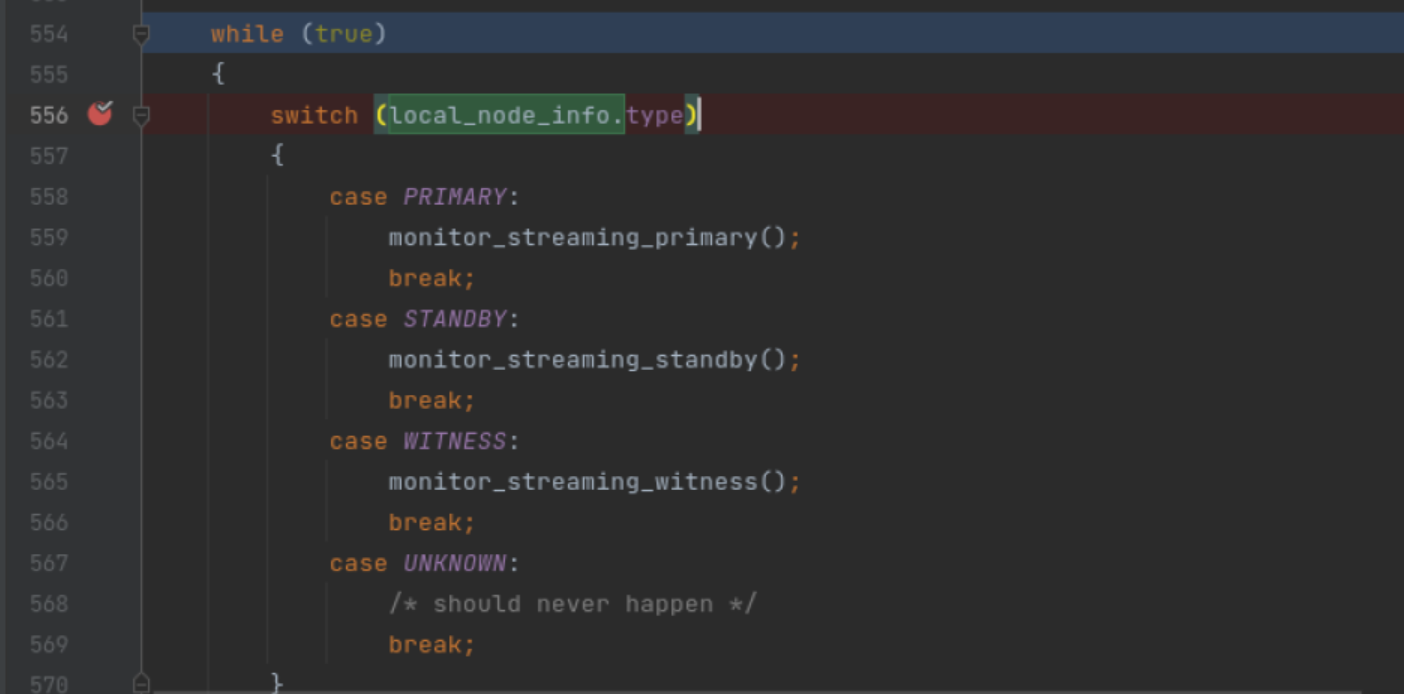
这3个函数monitor_streaming_primary,monitor_streaming_standby,monitor_streaming_witness 又是3个infinity loop 函数
只有当数据库角色发生切换的时候,才会重新返回这个switch 的代码块,进入不同角色的监控函数里面。
例如: monitor_streaming_primary 函数中会判断, 如果降级成为standby 的话, 会退出 函数monitor_streaming_primary

重新又回到switch 分支中:
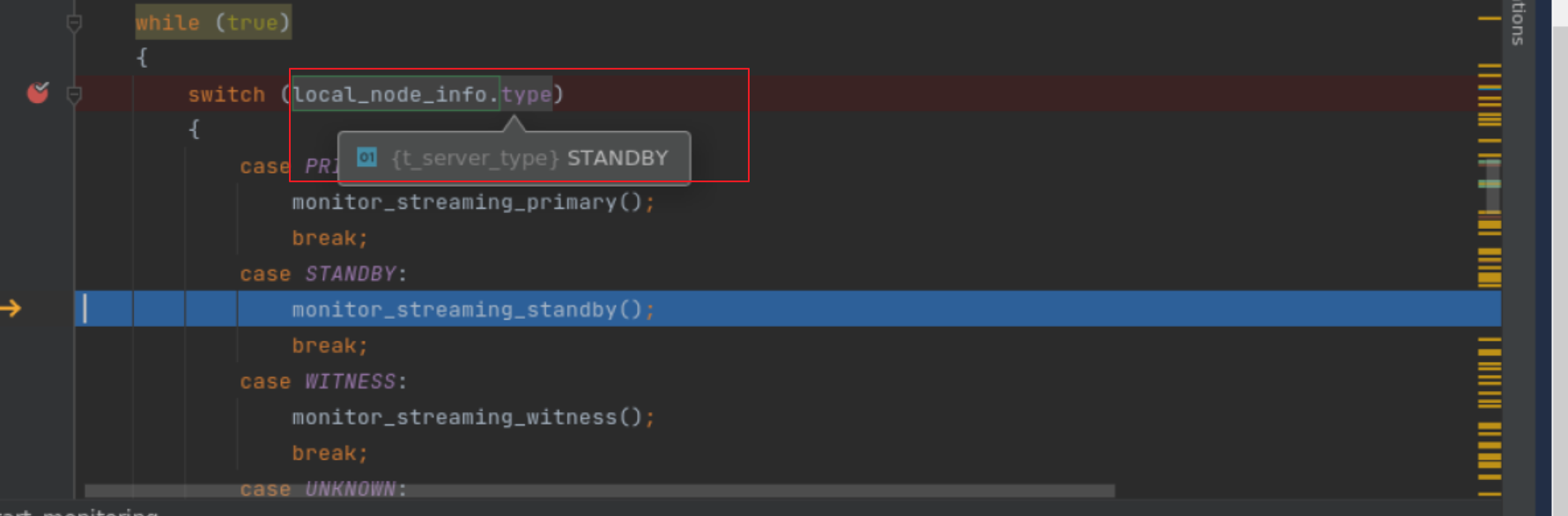
这个时候,日志中也会得到一些角色监控切换的日志信息: 这些日志信息对日后的trouble shotting 是有价值的。
[2023-09-10 17:37:30] [NOTICE] reconnected to node after 147 seconds, node is now a standby, switching to standby monitoring [2023-09-10 17:37:30] [NOTICE] former primary has been restored as standby after 147 seconds, updating node record and resuming monitoring
接下来,我们分别看看3个角色正常情况下, 在自己的监控函数里面不停的 loop 什么的逻辑
状态机为Primary: monitor_streaming_primary的程序分为2部分
初始化流程图:
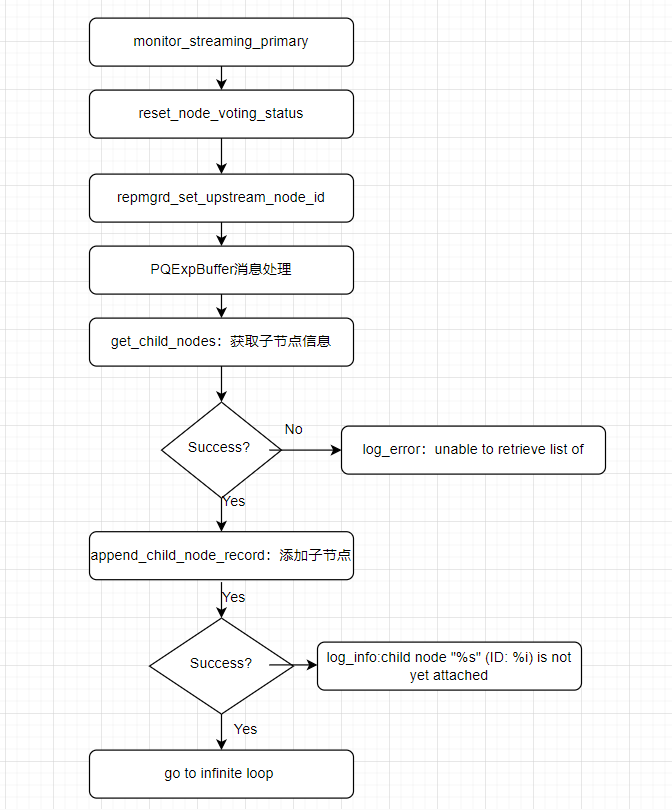
死循环驻留程序:
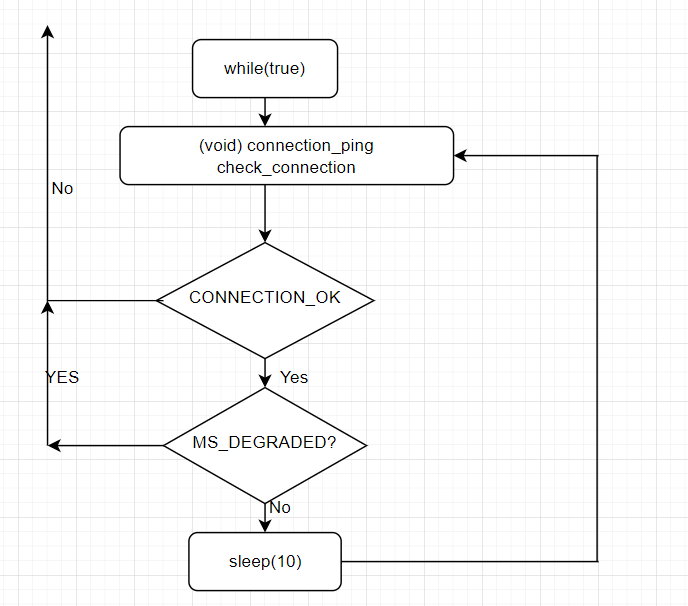
我们来简单的描述一下primary 节点上函数monitor_streaming_primary 执行了如下的步骤:
核心代码片段:
1)重置投票的信息 reset_voting_status
const char *sqlquery = "SELECT repmgr.reset_voting_status()";
reset_voting_status 函数是 更新状态锁shared_state的操作
LWLockAcquire(shared_state->lock, LW_SHARED);
/* only do something if local_node_id is initialised */
if (shared_state->local_node_id != UNKNOWN_NODE_ID)
{
LWLockRelease(shared_state->lock);
LWLockAcquire(shared_state->lock, LW_EXCLUSIVE);
shared_state->voting_status = VS_NO_VOTE;
shared_state->candidate_node_id = UNKNOWN_NODE_ID;
shared_state->follow_new_primary = false;
}
2)重置upstream node的ID 为 NO_UPSTREAM_NODE, 因为是主库不需要follow up 任何节点
repmgrd_set_upstream_node_id(local_conn, NO_UPSTREAM_NODE);
3)事件记录 主库morning 程序开启:
PQExpBufferData 是repmgrd中一个字符串处理的通用结构体
PQExpBufferData holds information about an extensible string.
create_event_notification 是 repmgrd中的时间通知创建函数,对应事件信息插入到数据库表repmgr.events
appendPQExpBufferStr(&query,
" INSERT INTO repmgr.events ( "
" node_id, "
" event, "
" successful, "
" details "
" ) "
" VALUES ($1, $2, $3, $4) "
" RETURNING event_timestamp ");
4)获得复制流子节点的信息
bool success = get_child_nodes(local_conn, config_file_options.node_id, &db_child_node_records);
SQL语句:
appendPQExpBuffer(&query,
" SELECT n.node_id, n.type, n.upstream_node_id, n.node_name, n.conninfo, n.repluser, "
" n.slot_name, n.location, n.priority, n.active, n.config_file, "
" '' AS upstream_node_name, "
" CASE WHEN sr.application_name IS NULL THEN FALSE ELSE TRUE END AS attached "
" FROM repmgr.nodes n "
" LEFT JOIN pg_catalog.pg_stat_replication sr "
" ON sr.application_name = n.node_name "
" WHERE n.upstream_node_id = %i ",
node_id);
5)更新子节点的链表信息:
(void) append_child_node_record(&local_child_nodes, cell->node_info->node_id, cell->node_info->node_name, cell->node_info->type, cell->node_info->attached == NODE_ATTACHED ? NODE_ATTACHED : NODE_ATTACHED_UNKNOWN);
6)进入while(true)循环中,执行 connection_ping , check_connection
PGresult *res = PQexec(conn, "SELECT TRUE");
7)如果step 6 发现local 节点down了,会进行二次尝试连接 try_reconnect
8)检查monitoring_state == MS_DEGRADED, False的话,继续进入到下一轮的循环中。 TRUE的话,check_primary_status 判断是否需要切换成standby 的监控模式。
/*
* If monitoring a primary, it's possible that after an outage of the local node
* (due to e.g. a switchover), the node has come back as a standby. We therefore
* need to verify its status and if everything looks OK, restart monitoring in
* standby mode.
*
* Returns "true" to indicate repmgrd should continue monitoring the node as
* a primary; "false" indicates repmgrd should start monitoring the node as
* a standby.
*/
bool
check_primary_status(int degraded_monitoring_elapsed)
我们再来看看 repmgrd 如何在 standby节点上运行的:这次我们忽略掉进入函数 monitor_streaming_standby 初始化设置部分,直接进入到 while(true) 部分
主要流程图:
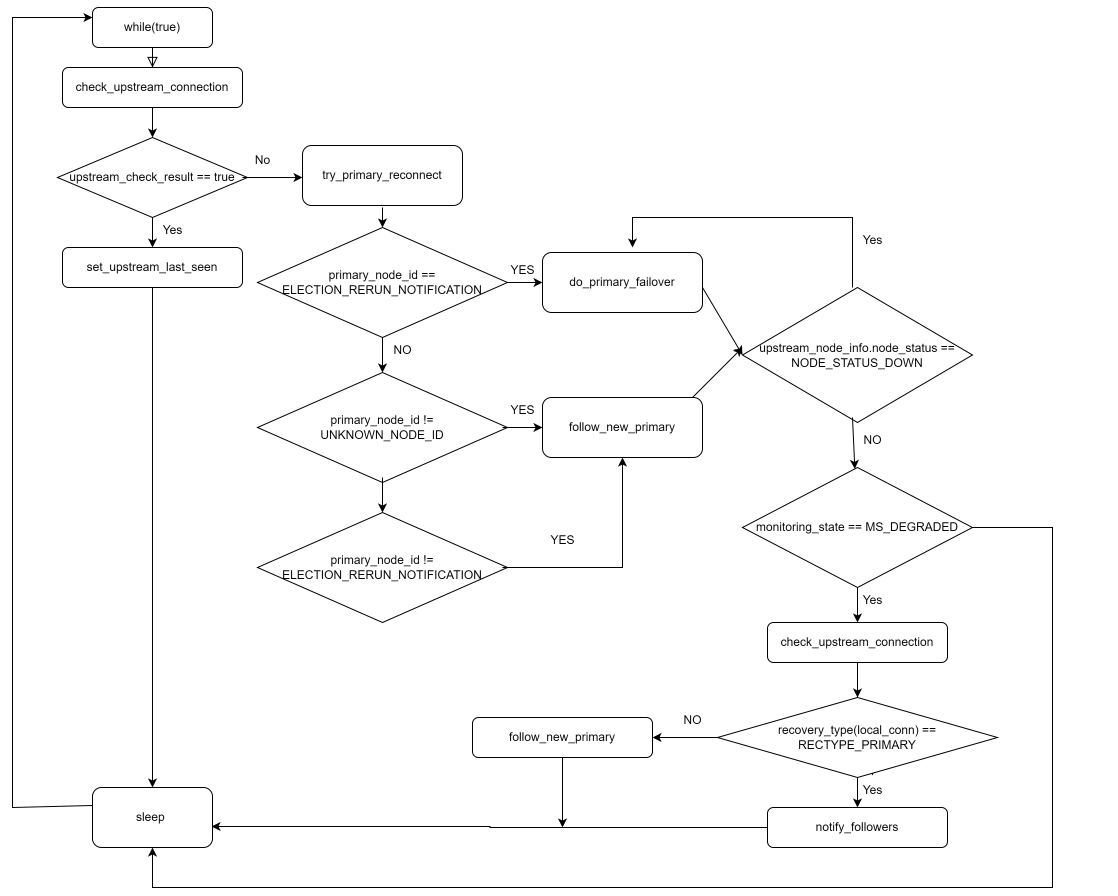
核心代码片段以及解释:
1)首先执行check_upstream_connection函数,判断replication的源库的联通性,如果一切okay的话,更新最后一次可见的时间
appendPQExpBuffer(&query,
"SELECT repmgr.set_upstream_last_seen(%i)",
upstream_node_id);
更新状态对象的shared_state的信息
shared_state->upstream_last_seen = GetCurrentTimestamp(); shared_state->upstream_node_id = upstream_node_id;
- 如果check_upstream_connection执行之后,发现upstream节点联通性出现问题,再次尝试连接操作try_primary_reconnect ,
如果获得primary_node_id 是ELECTION_RERUN_NOTIFICATION,则执行 do_primary_failover, 这个函数里面会执行选举的动作
/* attempt to initiate voting process */
election_result = do_election(&sibling_nodes, &new_primary_id);
具体选举的细节和 failover_state的状态机处理会在后面的篇幅详细处理。
3)如果step 2中 获得primary_node_id 不是UNKNOWN_NODE_ID , 不是ELECTION_RERUN_NOTIFICATION,证明不需要触发选举行为,此时主库可能发生了变动,需要
触发函数follow_new_primary:调用用户自定的参数follow_command里面配置的shell脚本
/*
* replace %n in "config_file_options.follow_command" with ID of primary
* to follow.
*/
parse_follow_command(parsed_follow_command, config_file_options.follow_command, new_primary_id);
4)如果step2,3都执行完成,发现upstream_connection依然存在问题,则会再次触发 do_primary_failover,符合条件的情况下再一次进行选举。
5)判断监控状态是否降级,如果是MS_DEGRADED的情况,会进行再次判断,如果check_upstream_connection 一切正常,更新监控状态为MS_NORMAL
如果 check_upstream_connection 失败,判断自己promote成了主库,主库的话,调用notify_followers
void
notify_follow_primary(PGconn *conn, int primary_node_id)
{
PQExpBufferData query;
PGresult *res = NULL;
initPQExpBuffer(&query);
appendPQExpBuffer(&query,
"SELECT repmgr.notify_follow_primary(%i)",
primary_node_id);
更新状态锁shared_state
/* Explicitly set the primary node id */
shared_state->candidate_node_id = primary_node_id;
shared_state->follow_new_primary = true;
如果 check_upstream_connection 失败,判断自己不是主库的话,则会再次触发 do_primary_failover,符合条件的情况下再一次进行选举。
最后我们看看witness 对应的后台函数: monitor_streaming_witness
简单的说,作为目击者,本身不参与promote self 的行为,作用就是在standby节点选举过程中作为目击证人,与candidate候选节点打成共识: 同一个location 内,至少还有目击证人活着,证明没有发生网络脑裂。
如果候选者连witness节点都ping不通的话,候选者节点直接返回 election_cancel.
驻留程序循环流程图:
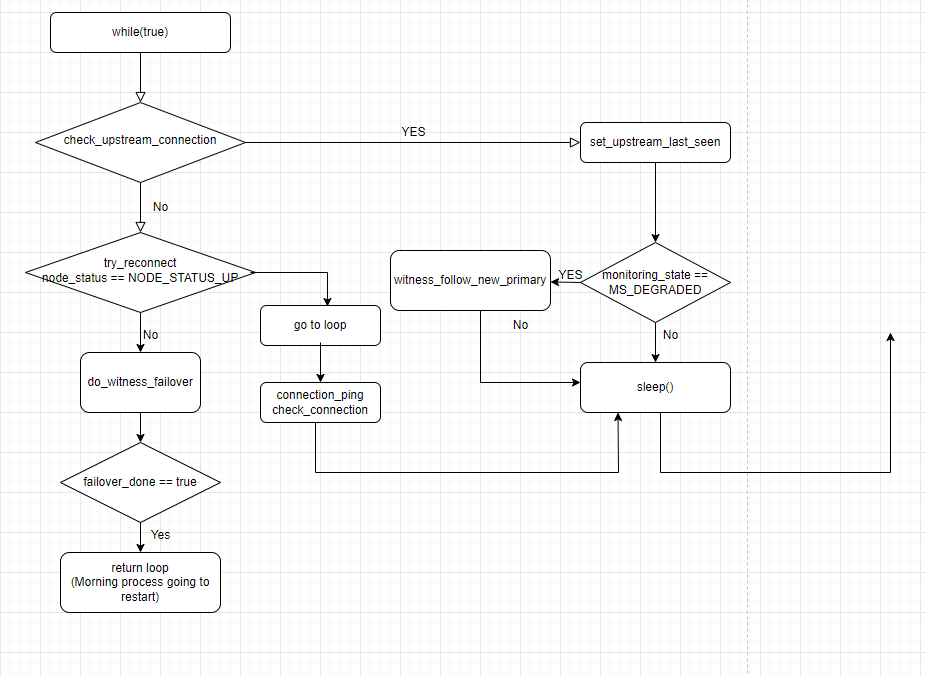
我们简单的描述一下witness后台进程的工作原理:
1)检查一下upstream 节点即为集群的主节点的联通性
2)如果可以连通,更新一下最后主库可见性的时间戳,如果可以主库不能够连通,判断是否出现降级,降级的话调用witness_follow_new_primary,否则会进入sleep然后重新循环
witness_follow_new_primary和normal standby 的最大区别就是 witness_follow_new_primary 不支持调用自动的脚本参数 config_file_options.follow_command
witness 节点会自动attach到新的primary 节点上, witness_copy_node_records 重新注册 witness节点
/* set new upstream node ID on primary */
update_node_record_set_upstream(upstream_conn, local_node_info.node_id, new_primary_id);
witness_copy_node_records(upstream_conn, local_conn);
3)如果step 1 出现主库联通失败的情况,会尝试retry_connection 重新连接,依然连接不上的话执行do_witness_failover
/*
* "failover" for the witness node; the witness has no part in the election
* other than being reachable, so just needs to await notification from the
* new primary
*/
static
bool do_witness_failover(void)
从代码的注解中也可以看到,do_witness_failover的作用只是等待新的主库出现,不会参与选举过程(只是作为目击证人)。
核心代码:wait_primary_notification 等待新主库的出现,出现的话执行 witness_follow_new_primary
if (wait_primary_notification(&new_primary_id) == true)
{
/* if primary has reappeared, no action needed */
if (new_primary_id == upstream_node_info.node_id)
{
failover_state = FAILOVER_STATE_FOLLOWING_ORIGINAL_PRIMARY;
}
else
{
failover_state = witness_follow_new_primary(new_primary_id);
}
}
我们再来看看repmgrd 是如何进行选举的?
主要的函数来自于文件 repmgrd-physical.c中的do_primary_failover: 下面罗列了一些比较重要的函数
check_connection -- 再次检查本地连接的联通性
do_election -- 进行选举流程
do_election 这个函数中:
get_active_sibling_node_records :-- 从数据库表repmgr.nodes 得到兄弟节点列表,列表里面排除了自己
execute_failover_validation_command: --执行repmgr.conf中的参数failover_validation_command的命令
选举的结果的枚举类型:
ELECTION_NOT_CANDIDATE : 无候选者
ELECTION_WON:节点选举获胜
ELECTION_LOST:节点选举失败
ELECTION_CANCELLED:节点选举取消
ELECTION_RERUN:节点重新选举
typedef enum { ELECTION_NOT_CANDIDATE = -1, ELECTION_WON, ELECTION_LOST, ELECTION_CANCELLED, ELECTION_RERUN } ElectionResult;
我们来看一下选举的流程图:
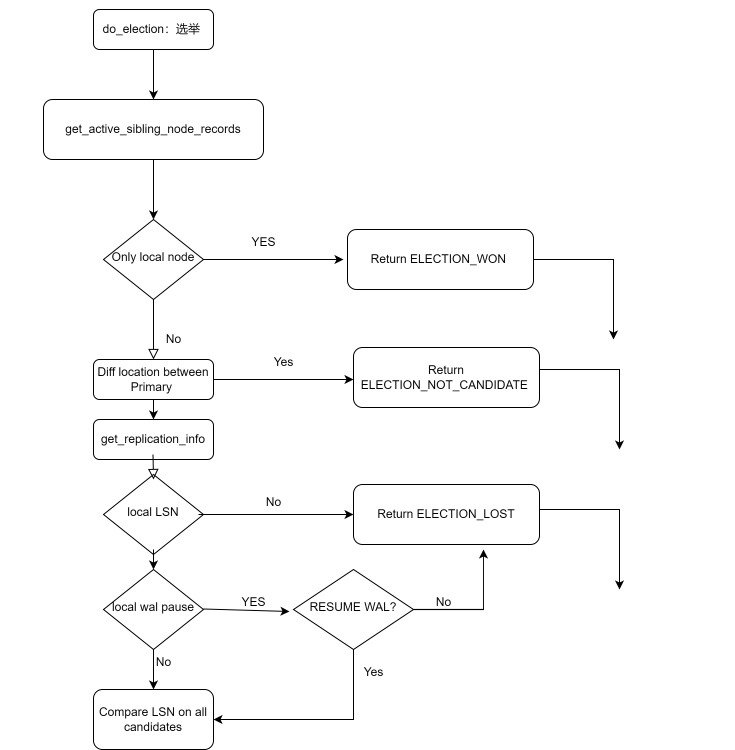
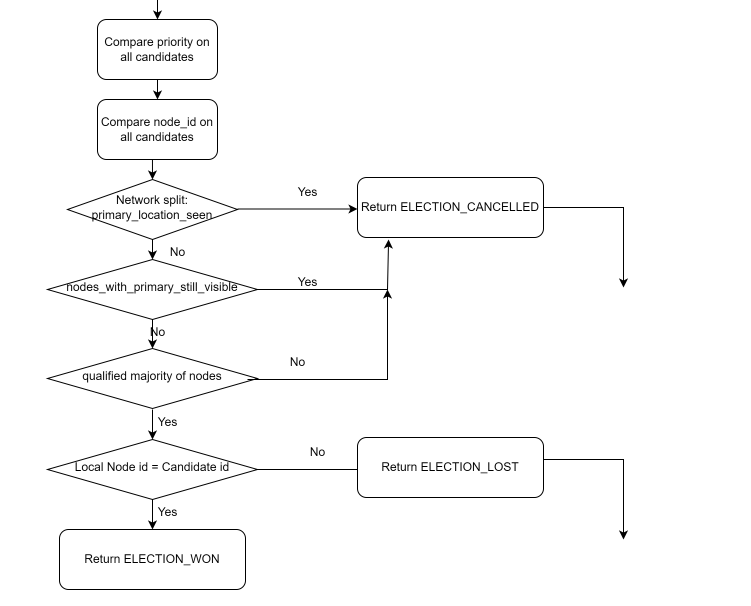
我们简单的描述一下选举过程:
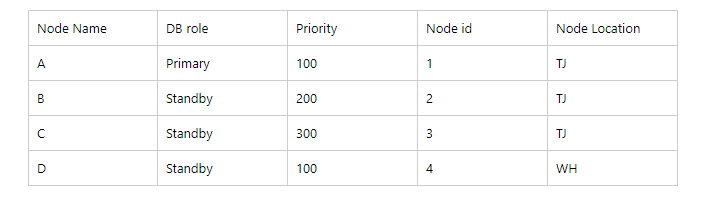
1)很不幸,由于某种原因主库 A 节点 down掉了
2)B,C,D 尝试等待重连主库A节点: checking state of node 1, N of 6 attempts…
3)连接超时后,BCD会各自进入选举的过程:
由于D的location 和 A 节点的location 是不一样的,直接返回 =》 ELECTION_NOT_CANDIDATE
4)B和 C 节点会执行获取last lsn的操作:
appendPQExpBufferStr(&query,
" SELECT ts, "
" in_recovery, "
" last_wal_receive_lsn, "
" last_wal_replay_lsn, "
" last_xact_replay_timestamp, "
" CASE WHEN (last_wal_receive_lsn = last_wal_replay_lsn) "
" THEN 0::INT "
" ELSE "
" CASE WHEN last_xact_replay_timestamp IS NULL "
" THEN 0::INT "
" ELSE "
" EXTRACT(epoch FROM (pg_catalog.clock_timestamp() - last_xact_replay_timestamp))::INT "
" END "
" END AS replication_lag_time, "
" last_wal_receive_lsn >= last_wal_replay_lsn AS receiving_streamed_wal, "
" wal_replay_paused, "
" upstream_last_seen, "
" upstream_node_id "
" FROM ( "
" SELECT CURRENT_TIMESTAMP AS ts, "
" pg_catalog.pg_is_in_recovery() AS in_recovery, "
" pg_catalog.pg_last_xact_replay_timestamp() AS last_xact_replay_timestamp, ");
如果无法获取LSN的值,直接返回 =》 ELECTION_LOST
5)如果发现WAL的日志应用的停止的,则尝试resume wal log的应用, 如果尝试resume_wal_replay 失败, 直接返回 =》 ELECTION_LOST
6)候选者B和C来进行如下的比较:
/* compare LSN /
/ LSN is same - tiebreak on priority, then node_id */
/* get node's last receive LSN - if "higher" than current winner, current node is candidate */
cell->node_info->last_wal_receive_lsn = sibling_replication_info.last_wal_receive_lsn;
/* compare LSN */
if (cell->node_info->last_wal_receive_lsn > candidate_node->last_wal_receive_lsn)
/* LSN is same - tiebreak on priority, then node_id */
else if (cell->node_info->last_wal_receive_lsn == candidate_node->last_wal_receive_lsn)
if (cell->node_info->priority > candidate_node->priority)
else if (cell->node_info->priority == candidate_node->priority)
if (cell->node_info->node_id < candidate_node->node_id)
经过一系列的比较,我们B和C之间的 LSN是一样的, 但是 B的 priority 200 小于 C的 priority 300.
这个时候C节点为理想的candidate.
7)进行防治网络脑裂的检测: 检查在主节点所在的location, 是否还有存活的节点,如果不存在,则视为网络脑裂,直接返回 =》 ELECTION_CANCELLED
/*
* Check if at least one server in the primary's location is visible; if
* not we'll assume a network split between this node and the primary
* location, and not promote any standby.
*
* NOTE: this function is only ever called by standbys attached to the
* current (unreachable) primary, so "upstream_node_info" will always
* contain the primary node record.
*/
bool primary_location_seen = false;
8)老的主库是否依旧存活 nodes_with_primary_still_visible > 0 ? , 如果是由于某些网络原因,造成主库的连接不稳定, 主库恢复之后, 直接返回 =》 ELECTION_CANCELLED
9)同一个location中是否存在大多数节点存活判断: 存活节点如果小于等于 3/2.0 = 1.5 的话 直接返回 =》 ELECTION_CANCELLED
if (stats.visible_nodes <= (stats.shared_upstream_nodes / 2.0)) { log_notice(_("unable to reach a qualified majority of nodes")); log_detail(_("node will enter degraded monitoring state waiting for reconnect"));
10)判断候选的ID是否和本地的ID是一致的。
目前candidate是 C节点, C节点上的 do_election 直接返回选举获胜 ELECTION_WON
B节点,直接返回 ELECTION_LOST
11)至此,C 节点成为选举的winner
接下来我们正式进入到failover 流程:
typedef enum { FAILOVER_STATE_UNKNOWN = -1, FAILOVER_STATE_NONE, FAILOVER_STATE_PROMOTED, FAILOVER_STATE_PROMOTION_FAILED, FAILOVER_STATE_PRIMARY_REAPPEARED, FAILOVER_STATE_LOCAL_NODE_FAILURE, FAILOVER_STATE_WAITING_NEW_PRIMARY, FAILOVER_STATE_FOLLOW_NEW_PRIMARY, FAILOVER_STATE_REQUIRES_MANUAL_FAILOVER, FAILOVER_STATE_FOLLOWED_NEW_PRIMARY, FAILOVER_STATE_FOLLOWING_ORIGINAL_PRIMARY, FAILOVER_STATE_NO_NEW_PRIMARY, FAILOVER_STATE_FOLLOW_FAIL, FAILOVER_STATE_NODE_NOTIFICATION_ERROR, FAILOVER_STATE_ELECTION_RERUN } FailoverState;
根据选举的结果来设置failover的状态: failover_state
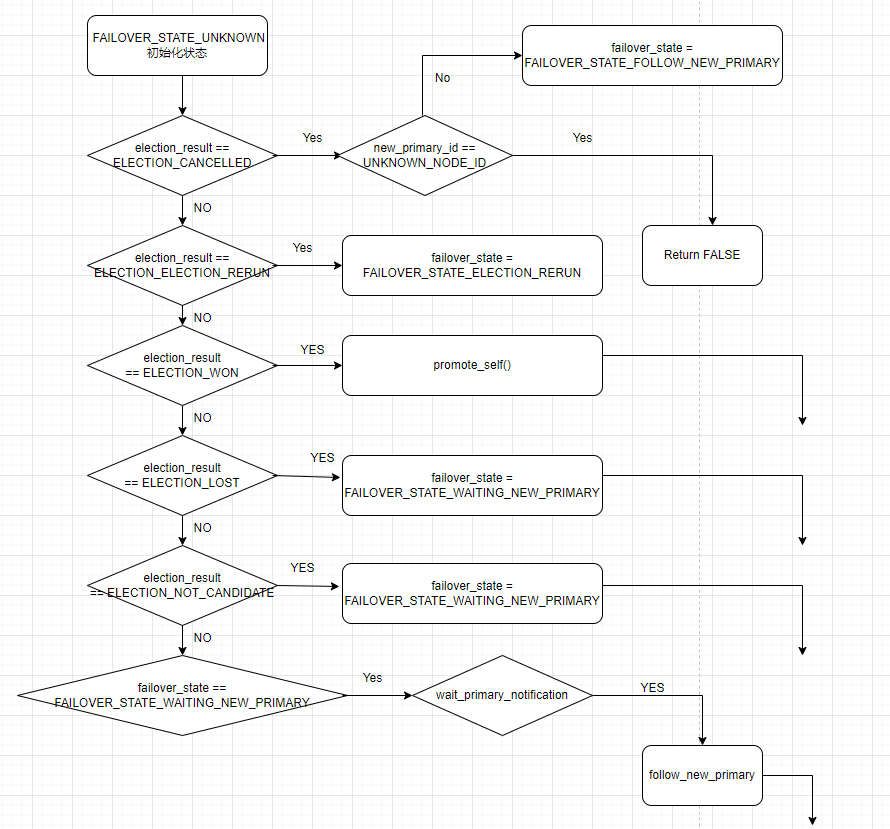
我们继续按照上面的例子:
1)节点C的返回状态是 ELECTION_WON 会直接调用函数:promote_self(), 执行promote_command 参数设置的脚本
/*
* This promotes the local node using the "promote_command" configuration
* parameter, which must be either "repmgr standby promote" or a script which
* at some point executes "repmgr standby promote".
*
* TODO: make "promote_command" and execute the same code used by
* "repmgr standby promote".
*/
static FailoverState
promote_self(void)
C节点promote 成功后,会向数据库repmgr的表event中插入条通知记录:
create_event_notification_extended(local_conn, &config_file_options, local_node_info.node_id, "repmgrd_failover_promote", true, event_details.data, &event_info);
并返回failover的状态为 FAILOVER_STATE_PROMOTED
2)节点B的选举返回状态是 ELECTION_LOST, 设置成failover 的状态为 FAILOVER_STATE_WAITING_NEW_PRIMARY
/*
* node has decided it is a follower, so will await notification from the
* candidate that it has promoted itself and can be followed
*/
else if (failover_state == FAILOVER_STATE_WAITING_NEW_PRIMARY)
{
/* TODO: rerun election if new primary doesn't appear after timeout */
/* either follow, self-promote or time out; either way resume monitoring */
if (wait_primary_notification(&new_primary_id) == true)
wait_primary_notification这个函数里面: 会循环等待新的主库是否ready
wait_primary_notification(int *new_primary_id) { int i; for (i = 0; i < config_file_options.primary_notification_timeout; i++) { if (get_new_primary(local_conn, new_primary_id) == true) { log_debug("new primary is %i; elapsed: %i seconds", *new_primary_id, i); return true; } log_verbose(LOG_DEBUG, "waiting for new primary notification, %i of max %i seconds (\"primary_notification_timeout\")", i, config_file_options.primary_notification_timeout); sleep(1); }
主库 ready 之后, 调用函数follow_new_primary(new_primary_id) : 调用参数 follow_command 设置的shell 命令
代码片段:
/*
* replace %n in "config_file_options.follow_command" with ID of primary
* to follow.
*/
parse_follow_command(parsed_follow_command, config_file_options.follow_command, new_primary_id);
log_debug(_("standby follow command is:\n \"%s\""),
parsed_follow_command);
/* execute the follow command */
r = system(parsed_follow_command);
failover_state 的状态机代码:返回最终final_result 的布尔值
switch (failover_state)
{
case FAILOVER_STATE_PROMOTED:
/* notify former siblings that they should now follow this node */
notify_followers(&sibling_nodes, local_node_info.node_id);
/* pass control back down to start_monitoring() */
log_info(_("switching to primary monitoring mode"));
failover_state = FAILOVER_STATE_NONE;
final_result = true;
break;
case FAILOVER_STATE_ELECTION_RERUN:
/* we no longer care about our former siblings */
clear_node_info_list(&sibling_nodes);
log_notice(_("rerunning election after %i seconds (\"election_rerun_interval\")"),
config_file_options.election_rerun_interval);
sleep(config_file_options.election_rerun_interval);
log_info(_("election rerun will now commence"));
/*
* mark the upstream node as "up" so another election is triggered
* after we fall back to monitoring
*/
upstream_node_info.node_status = NODE_STATUS_UP;
failover_state = FAILOVER_STATE_NONE;
final_result = false;
break;
最后我们总结一下:学习源码的目的是为了理内部运行原理,为日后的 trouble shooting 提供清晰的思路。
1)Repmgrd 根据节点角色的不同, 在不同角色的节点上, 后代运行着不同的函数,
2)在进行选举的时候,采用了防止网络脑裂的判断(primary_location_seen,同一个location,至少要有一个以上的存活节点),以及检查是否大多数节点都存话的判断(stats.visible_nodes <= (stats.shared_upstream_nodes / 2.0)),极大程度上避免了出现数据库双主脑裂的情况
3)跨DC,建议配置不同的location, 如果同一个location是跨DC的,最增加选举时候的复杂性判断。
Have a fun 🙂 !
