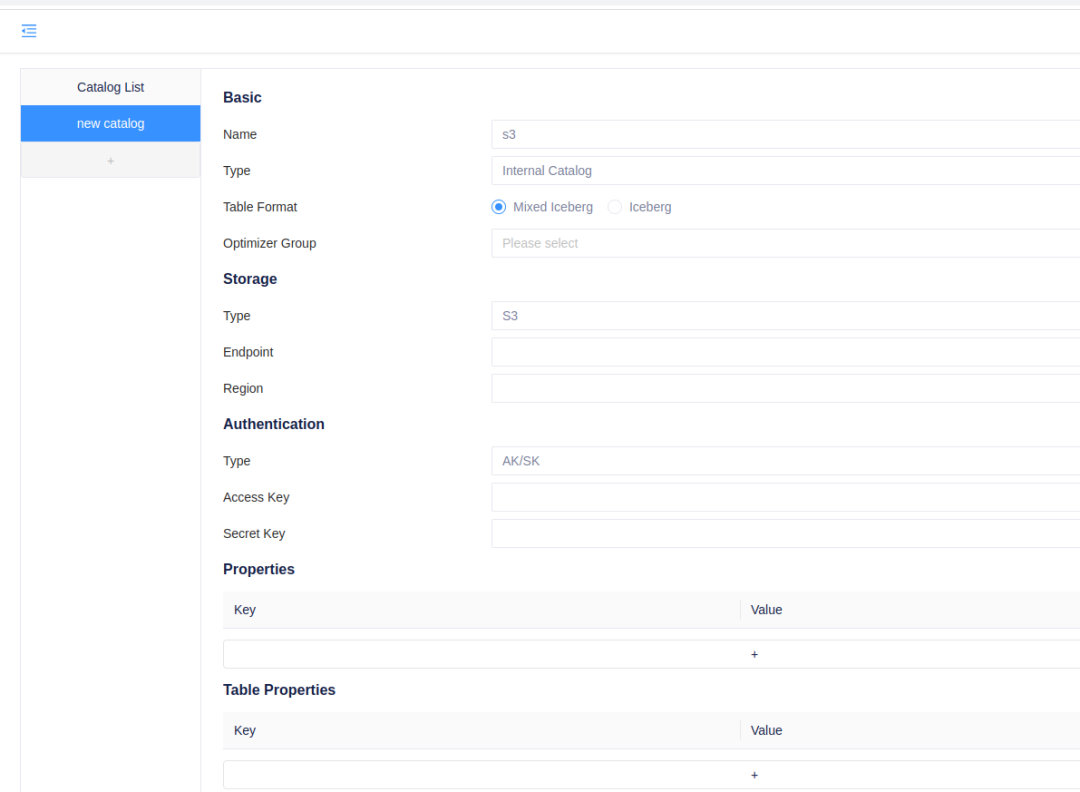
Amoro 是一个构建在 Apache Iceberg 等开放数据湖表格之上的湖仓管理系统,提供了一套可插拔的数据自优化机制和管理服务,旨在为用户带来开箱即用的湖仓使用体验。
对接云上 AWS Glue + Iceberg + S3 方案,为云上湖仓提供管理与自动优化能力。
对接 Hive Metastore + Iceberg + S3 方案, 为基于 Hive Metastore 的云原生湖仓提供管理与自动优化能力。
使用 AMS 作为 Iceberg 元数据中心,直接对接 S3 或 Hadoop 数据湖,构建与云厂商无关的云原生湖仓。
containers:- name: flinkContainercontainer-impl: com.netease.arctic.server.manager.FlinkOptimizerContainerproperties:flink-home: opt/flink/ #flink install hometarget: kubernetes-application #flink run as native kubernetesjob-uri: "local:///opt/flink/usrlib/optimizer-job.jar" #optimizer job location in imageams-optimizing-uri: thrift://ams.amoro.service.local:1261 #AMS optimizing uriexport.FLINK_CONF_DIR: opt/flink/conf/ #flink config dirflink-conf.kubernetes.container.image: "arctic163/optimizer-flink:latest" #image refflink-conf.kubernetes.service-account: flink #kubernetes service account
从 0.6.0 版本开始,可以直接在 Optimizer Group 中配置独立的 Regiester URI ,除了在 Kubernetes 环境下,在一些其他生产场景中也十分有用。比如在跨 region 调动 Optimizer 资源的情况下,从其他 region 访问 AMS 可能需要使用网关的 IP 地址和端口。
## 正式推出官方镜像
2. 基础镜像已经被 Deprecated ,Openjdk 镜像官方已经不再维护,并不建议在生产中继续使用。
版本tag:如 arcitc163/amoro:0.6.0 、 arctic163/amoro:0.6.0-rc1 ,版本 tag 与 git tag 保持一致,使用默认的 profile 编译。
Hadoop 版本 tag:非默认的 Hadoop 版本编译出来的将使用 -hadoop{version} 后缀标识。比如 arctic163/amoro:0.6.0-hadoop2 表示这个镜像使用 -Dhadoop=v2 参数编译。
master-snapshot tag:每天会自动拉取 master 分支最新代码构建镜像,如想尝试最新的 feature,可以使用该 tag 获取最新的代码构建镜像。使用方式为 arctic163/amoro:master-snapshot 。master-snapshot 镜像只提供默认的 hadoop 版本编译。
除了 amoro 镜像外,还额外提供了 arctic163/optimizer-flink 镜像,作为 Flink Optimizer 的官方镜像。其 tag 维护方式为 ${amoro-version}-flink${flink-version} ,比如:arctic163/optimizer-flink:0.6.0-flink1.15
此外 quickdemo 的镜像会维护和 amoro 镜像一致的 Tag。
## 支持通过 Helm 在 Kubernetes 上部署 AMS 与 Flink Optimizer
Kubernetes 部署涉及多种 Kubernetes 资源的管理,在 0.6.0 版本之前 Kubernetes 的部署需要用户手动维护这些资源的 yaml 文件,而在 0.6.0 版本中,我们提供了 Helm 部署的 Charts ,可以通过 Helm 在 Kubernetes 一键部署、管理 AMS 服务。
Helm 是一个 Kubernetes 包管理器,它允许你定义、安装和升级 Kubernetes 应用程序。Helm 允许你将 Kubernetes 应用程序打包成称为 Helm Chart 的可重用组件,并将其共享到 Chart 存储库中以供其他人使用。Helm Chart 包含了一组 Kubernetes 资源定义和值文件,可以配置这些资源定义的参数。使用 Helm,你可以轻松地部署、升级和管理 Kubernetes 应用程序。更多关于 Helm 的信息以及安装方式可以查看 Helm 官方文档 https://helm.sh/docs/ 。
在安装了 Helm3 客户端后,通过以下命令添加并查看 Amoro 的 Helm Repo。
$ helm repo add amoro https://netease.github.io/amoro/charts$ helm repo listNAME URLamoro https://netease.github.io/amoro/charts
通过以下命令搜索 amoro charts,出现以下结果表明添加成功。
$ helm search repo amoroNAME CHART VERSION APP VERSION DESCRIPTIONamoro/amoro 0.1.0 master-snapshot A Helm chart for Amoro
在本文的后续章节,将演示如何通过 Helm Charts 在 Kubernetes 安装 Amoro 实例。
03 新功能演示:Amoro 与 Kubernetes 集成
在本章节,将演示如何通过 Helm 部署 Amoro ,并配置 Flink optimizer 和使用新的 Catalog 注册页面等 Amoro 0.6.0 新功能。
## 前置环境准备
为了完成演示,需要完成以下环境准备:
一个 Kubernetes 集群:可以是基于云服务的比如AWS EKS 集群,也可以是基于物理机部署的生产标准的 K8S 集群,或在基于 minikube 在开发机上搭建的 develop 集群。基于 minikube 搭建 Kubernetes 测试集群可以参考这里 https://minikube.sigs.k8s.io/docs/start/
Helm3 客户端:Helm 是 Kubernetes 的包管理器,通过 Helm 脚本可以轻易的将一组 Kubernetes 底层资源组织为应用服务。Helm 的安装可以参考这里 https://helm.sh/docs/intro/install/
需要为 Kubernetes 集群准备好 StorageClass 和 IngressClass:如果使用 minikube 部署,默认安装了基于 HostPath 的 StorageClass ,可以通过命令 minikube addons enable ingress 安装基于 Nginx 的 IngressClass, 更多使用方法参考文档 https://kubernetes.io/zh-cn/docs/tasks/access-application-cluster/ingress-minikube/ 这里不过多赘述。
数据湖存储服务:可以是基于 Helm 部署的 minio 集群,或是云厂商提供的兼容的 S3 协议的存储服务。
可以通过以下命令从 Amoro 官方仓库获取稳定版本的 Helm charts 。
# 添加 Amoro 官方 Repo$ helm repo add amoro https://netease.github.io/amoro/charts$ helm repo listNAME URLamoro https://netease.github.io/amoro/charts# 搜索 Amoro charts$ helm search repo amoroNAME CHART VERSION APP VERSION DESCRIPTIONamoro/amoro 0.1.0 master-snapshot A Helm chart for Amoro# 获取 Amoro charts 到本地$ helm pull amoro/amoro$ tar zxvf amoro-*.tgz
也可以直接从项目源码直接编译 charts.
$ git clone https://github.com/NetEase/amoro.git$ cd amoro/charts$ helm dependency build ./amoro
## 配置 Amoro 应用
Amoro Helm Charts 的配置入口是 amoro/values.yaml文件。编辑该文件并修改以下配置:
$ vim ./amoro/values.yaml# 修改 image,默认拉取 latest 镜像,这里编辑tag为 "master-snapshot" 以使用 master 分支的构建镜像image:repository: arctic163/amoropullPolicy: IfNotPresenttag: "master-snapshot"# 修改 metastore database 配置,默认配置为 derby 会在容器重启后丢失数据,# 生产环境建议改成 MySQL database,并配置正确的连接方式amoroConf:database:type: mysqldriver: com.mysql.cj.jdbc.Driverurl: <jdbc-uri>username: <mysql-user>password: <mysql-password># optimizer 部分会配置可用的 optimizer container. 这里开启 FlinkOptimizer 的配置optimizer:flink:enabled: true## AMS 页面展示的 Optimizer Container Name,这里默认值将会展示为 flinkname: ~## Flink Optimizer 使用的 Image 相关配置,这里使用官方镜像 arctic163/optimizer-flinkimage:repository: arctic163/optimizer-flink## tag 默认值与 amoro 镜像 tag 一致tag: ~jobUri: "local:///opt/flink/usrlib/optimizer-job.jar"# optimizer properties 相关配置,这里推荐将 tm 的堆外内存配置为 32mb# 具体配置请参考 https://amoro.netease.com/docs/latest/managing-optimizers/#flink-containerproperties: {"flink-conf.taskmanager.memory.managed.size": "32mb","flink-conf.taskmanager.memory.netwrok.max": "32mb","flink-conf.taskmanager.memory.netwrok.nin": "32mb"}# 配置 Ingress,使得可以从集群外部访问 AMS Dashboard.ingress:enabled: true# ingressClassName,取决于Kubernetes集群安装的 IngressClass,如果有默认实现,可以不配置ingressClassName: ""# 集群外访问该 Ingress 的域名.hostname: amoro.ingress.cluster.local
注:如果使用的是 minikube 并且配置的 nginx-ingress,需要将 ingress hostname 配置的域名配置到 /etc/hosts, IP 地址为本机地址。
## 安装 Amoro 实例
完成上述配置后,执行以下命令安装 Amoro
$ helm install amoro-instance ./amoroNAME: amoro-instanceLAST DEPLOYED: Tue Oct 17 19:39:51 2023NAMESPACE: defaultSTATUS: deployedREVISION: 1TEST SUITE: NoneNOTES:The Amoro Helm chart has been installed!If you want to go ams web ui,you can use this cmd forward to local:http://amoro.ingress.cluster.local/Additional Resources Docs================================================================================================================* Documentation: https://amoro.netease.com/docs/0.6.0/* Version build Info : https://github.com/NetEase/amoro/releases/tag/v0.6.0================================================================================================================
执行完成后,可以通过 kubectl 命令观察 kubernetes 资源
$ kubectl get allNAME READY STATUS RESTARTS AGEpod/amoro-instance-6bc7fcf866-qdvvg 1/1 Running 0 50sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/amoro-instance-optimizing ClusterIP 10.104.58.41 <none> 1261/TCP 50sservice/amoro-instance-rest ClusterIP 10.100.197.15 <none> 1630/TCP 50sservice/amoro-instance-table ClusterIP 10.105.33.126 <none> 1260/TCP 50sNAME READY UP-TO-DATE AVAILABLE AGEdeployment.apps/amoro-instance 1/1 1 1 50sNAME DESIRED CURRENT READY AGEreplicaset.apps/amoro-instance-6bc7fcf866 1 1 1 50s# 查看 ingress 状态$ kubectl get ingressNAME CLASS HOSTS ADDRESS PORTS AGEamoro-instance nginx amoro.ingress.cluster.local 192.168.49.2 80 114s
待 pod 进入running 状态后,访问 ingress 配置的域名,即可查看 Amoro Dashboard 页面。
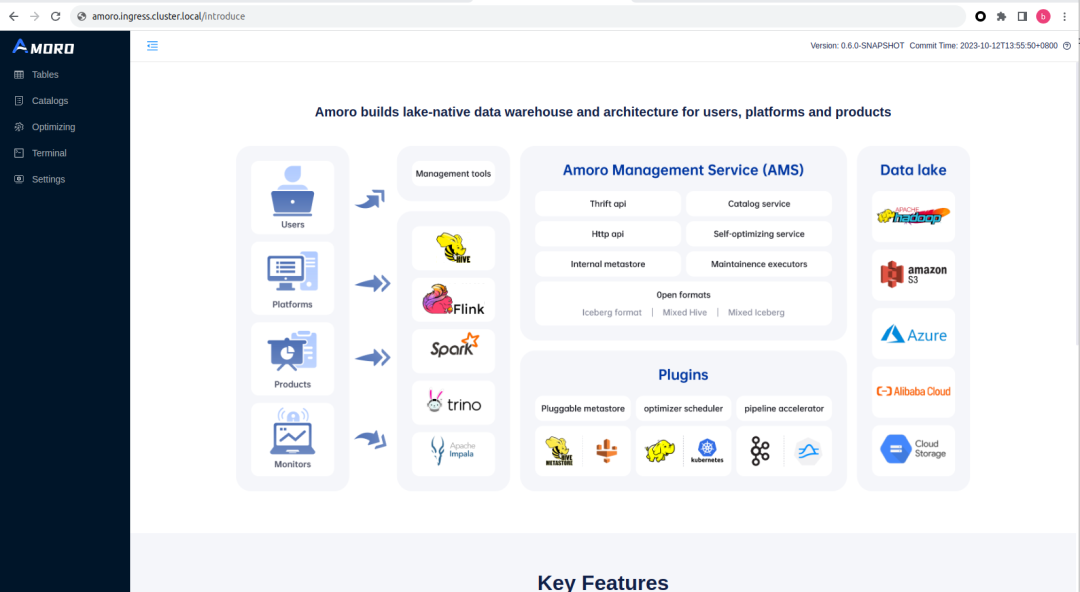
## 添加 Flink Optimizer
进入 Optimizing -> Optimizer Groups 管理页面,点击 Add Group 创建一个新的 Optimizer Group , 在 Container 的下拉框中可以看到 Helm Charts 已经部署好了 Flink Container。这里新增一个 Group 名字为 default。
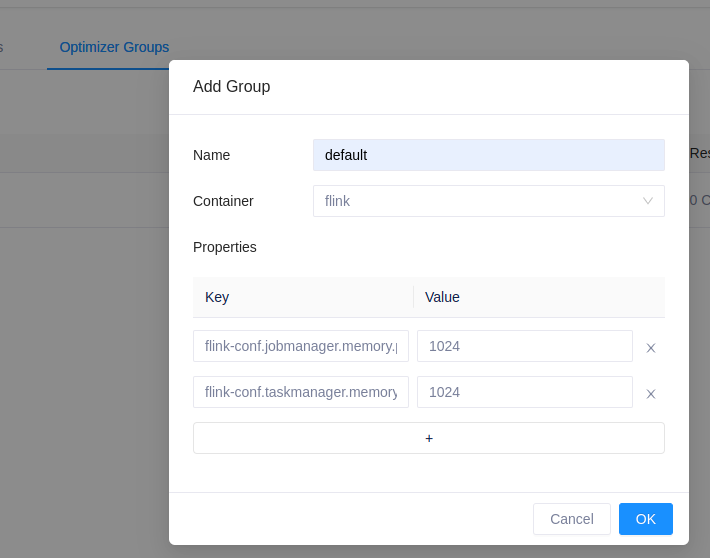
在新增的 Optimizer Group 中,通过 flink-conf 前缀的 Properties 配置 Flink Optimizer 相关的参数。所有 Flink native Kubernetes 相关参数均可以通过此方式配置,具体支持的参数列表请参考:
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/config/#kubernetes
这里通过 flink-conf.jobmanager.memory.process.size 和 flink-conf.taskmanager.memory.process.size 限制 JM 内存和 TM 上每个并发内存大小不超过 1GB 。
添加Group 成功后,点击 Scala-out 扩容,设置并发为2,然后通过 kubectl 客户端观察 Kubernetes 上资源。
$ kubectl get allNAME READY STATUS RESTARTS AGEpod/amoro-instance-6bc7fcf866-qdvvg 1/1 Running 0 16mpod/amoro-optimizer-1nul8hvg269h5qqt83rfkt4c00-6476fbbf5f-hszjt 1/1 Running 0 30spod/amoro-optimizer-1nul8hvg269h5qqt83rfkt4c00-taskmanager-1-1 1/1 Running 0 17spod/amoro-optimizer-1nul8hvg269h5qqt83rfkt4c00-taskmanager-1-2 1/1 Running 0 17sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/amoro-instance-optimizing ClusterIP 10.104.58.41 <none> 1261/TCP 16mservice/amoro-instance-rest ClusterIP 10.100.197.15 <none> 1630/TCP 16mservice/amoro-instance-table ClusterIP 10.105.33.126 <none> 1260/TCP 16mservice/amoro-optimizer-1nul8hvg269h5qqt83rfkt4c00 ClusterIP None <none> 6123/TCP,6124/TCP 30sservice/amoro-optimizer-1nul8hvg269h5qqt83rfkt4c00-rest LoadBalancer 10.103.247.238 <pending> 8081:30909/TCP 30sNAME READY UP-TO-DATE AVAILABLE AGEdeployment.apps/amoro-instance 1/1 1 1 16mdeployment.apps/amoro-optimizer-1nul8hvg269h5qqt83rfkt4c00 1/1 1 1 30sNAME DESIRED CURRENT READY AGEreplicaset.apps/amoro-instance-6bc7fcf866 1 1 1 16mreplicaset.apps/amoro-optimizer-1nul8hvg269h5qqt83rfkt4c00-6476fbbf5f 1 1 1 30s
可以看到 Amoro 通过 Flink native kubernetes 的方式提交了一个任务,flink-cluster-id 为 amoro-optimizer-${optimizer-id} , 该 Flink Application 包括一个 JM 和 2个 TM 。等待 optimizer 向 AMS 注册成功,即可在 Amoro Dashboard 页面 Optimizing -> Optimizers 子页面查看刚启动的 Optimizer 信息。
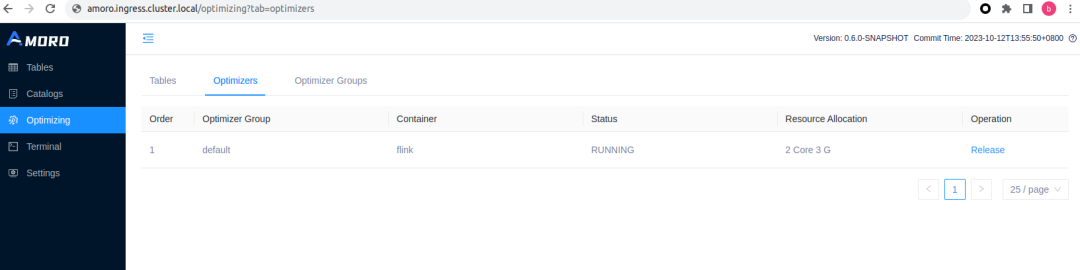
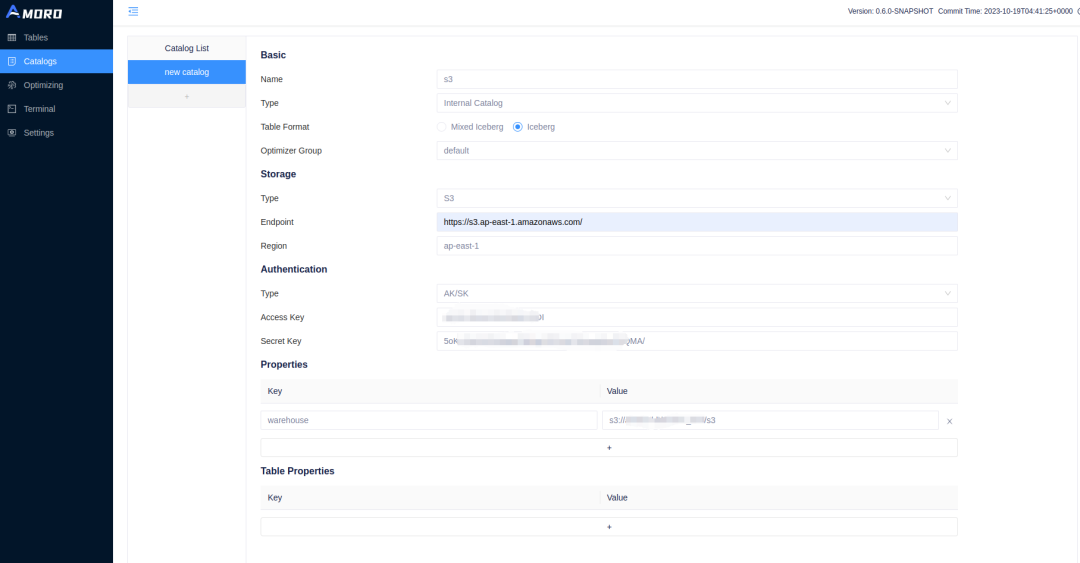
## 注册 Catalog
直接基于 S3 使用 Iceberg 使用 AMS 作为元数据中心
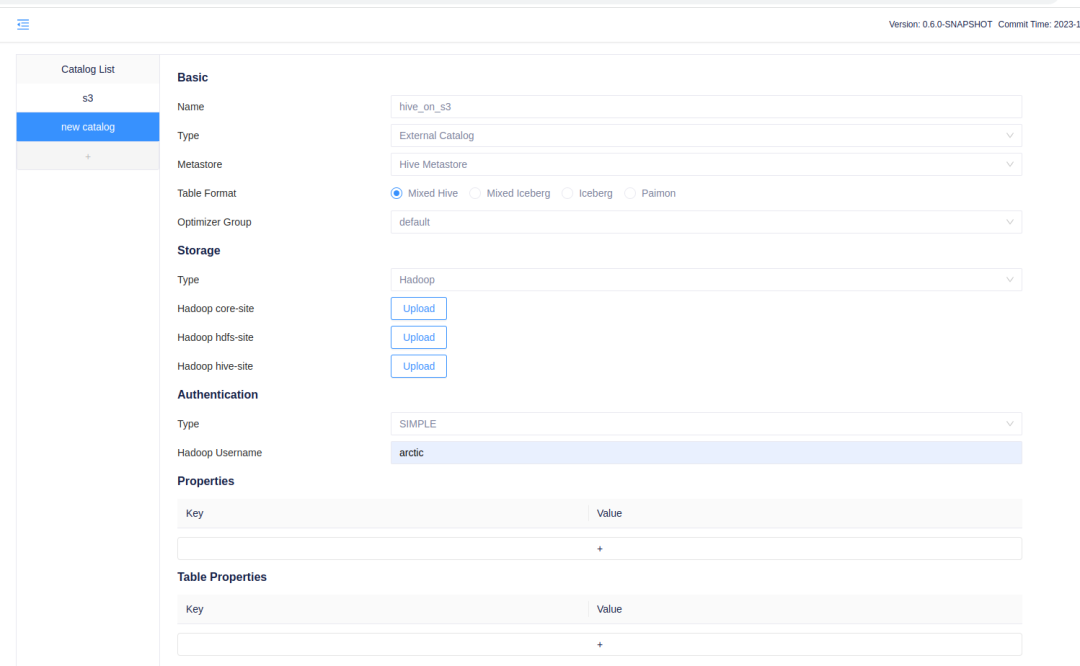
使用 Iceberg + Hive Metastore 通过 s3a 协议使用 S3 存储
在使用 Hive Metastore 做元数据中心时,可以通过 s3a 协议访问 S3 存储系统。关于 s3a 协议的信息可以参考: https://hadoop.apache.org/docs/stable/hadoop-aws/tools/hadoop-aws/index.html
在这种方式下,需要在 Hadoop 配置文件中配置 S3 相关的信息。
core-site.xml 文件中需要添加如下配置:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>fs.s3a.access.key</name><value> ${access-key} </value></property><property><name>fs.s3a.secret.key</name><value>${secret-key}</value></property><property><name>fs.s3a.path.style.access</name><value>true</value></property><property><name>fs.s3a.endpoint</name><value>https://${s3-api-host}:${s3-api-port}</value></property><property><name>fs.s3a.impl</name><value>org.apache.hadoop.fs.s3a.S3AFileSystem</value></property><property><name>fs.s3a.endpoint.region</name><value>${region}</value></property><property><name>fs.defaultFS</name><value>s3a://${s3-bucket}/</value></property></configuration>
在 hive-site.xml 中需要通过 S3A 协议配置 Warehouse 地址
<property><name>hive.metastore.warehouse.dir</name><value>s3a://${s3-bucket}/user/hive/warehouse</value></property>
并且需要将 hadoop-aws.jar 和 aws-java-sdk-bundle.jar 放置到 HADOOP_HOME/share/hadoop/common/lib/ 目录下。这两个依赖的下载地址为:
aws-java-sdk-bundle.jar : https://repo.maven.apache.org/maven2/com/amazonaws/aws-java-sdk-bundle/
hadoop-aws.jar : https://repo.maven.apache.org/maven2/org/apache/hadoop/hadoop-aws/
其中 hadoop-aws.jar 注意下载与你 Hadoop 版本相匹配的版本。
在注册 Catalog 时,Catalog Type 选择 ExternalCatalog ,在 Metastore 中选择 HiveMetastore,Storage Type 选择 Hadoop,上传上述配置了 S3A 协议的 site.xml 文件即可。
04 致谢
0.6.0 版本的开发过程离不开社区同学的支持,尤其是 Kubernetes 和 S3 相关的功能基本均来自社区开发者的贡献。在此感谢以下同学对 Amoro 云原生功能的贡献。

END
看到这里记得关注、点赞、转发 一键三连哦~

精彩回顾:
Amoro Mixed Format 上海钢联的构建实时湖仓实践