




本文翻译自
https://medium.com/neo4j/langchain-library-adds-full-support-for-neo4j-vector-index-fa94b8eab334
代码可以在GitHub上找到:
https://github.com/tomasonjo/blogs/blob/master/llm/official_langchain_neo4jvector.ipynb
8月22日 Neo4j 在5.11版本中将向量搜索功能完全集成到 Neo4j AuraDB 和 Neo4j 图数据库中。随后对 Neo4j 向量检索的全面支持也被集成到了 LangChain 库中。
Neo4j 向量检索已成为检索增强生成 (RAG) 应用程序领域的关键工具,特别是在处理结构化和非结构化数据方面。LangChain 库是构建大型语言模型 (LLM) 应用程序的重要框架。
这种集成有助于将数据有效地摄取到 Neo4j Vector Index 中,简化了 RAG 应用程序中的数据摄取和查询,并能够构建有效的 RAG 应用程序,通过利用结构化和非结构化数据提供实时、准确且与上下文相关的答案。它支持数据摄取和读取工作流程,对于使用 RAG 架构开发问答聊天机器人特别有用。
这篇文章将演示如何利用 LangChain 将数据有效摄取到 Neo4j 向量索引中,然后构建一个简单而有效的 RAG 应用程序。
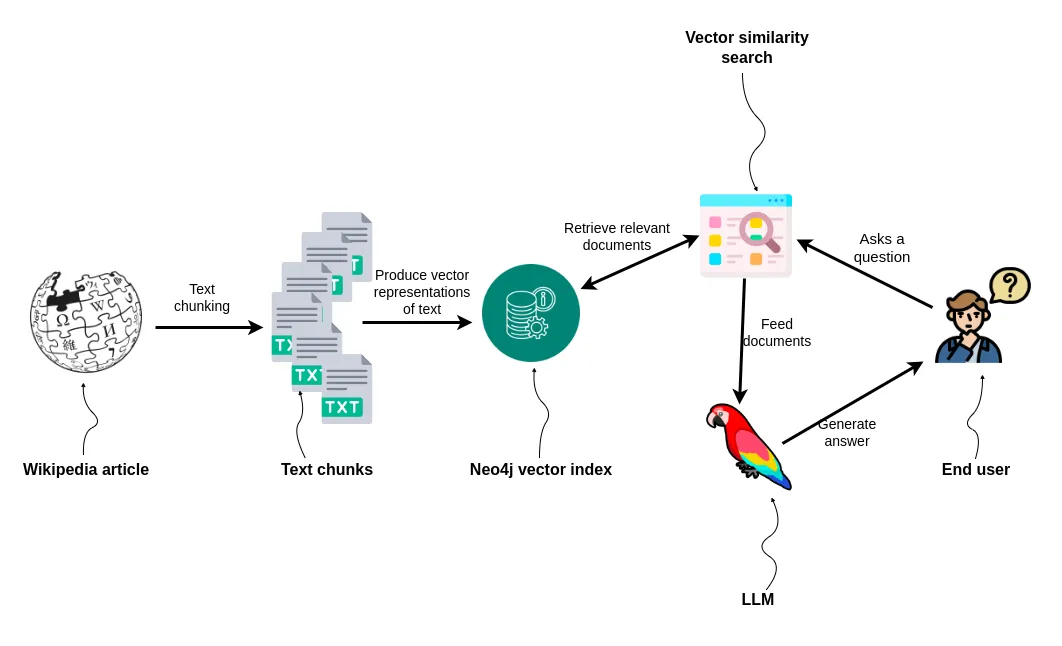
本教程将包含以下步骤:
使用 LangChain 文档阅读器阅读维基百科文章
将文本分块
将文本存储在 Neo4j 中并使用新添加的向量索引对其进行索引
实施问答工作流程以支持 RAG 应用程序。
01
Neo4j 环境设置
✦
我们需要设置 Neo4j 5.11 或更高版本才能完成本文章中的示例。最简单的方法是在 Neo4j Aura 上启动一个免费实例,它提供 Neo4j 数据库的云实例。或者,我们还可以通过下载 Neo4j Desktop 应用程序并创建本地数据库实例来设置 Neo4j 数据库的本地实例。
首先安装 langchain openai wikipedia tiktoken neo4j 包
pip install langchain openai wikipedia tiktoken neo4j
然后导入配置
import osfrom langchain.vectorstores.neo4j_vector import Neo4jVectorfrom langchain.document_loaders import WikipediaLoaderfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.text_splitter import CharacterTextSplitteros.environ['OPENAI_API_KEY'] = "API_KEY"
02
阅读和分块维基百科文章
✦
我们将从阅读和分块维基百科文章开始。这个过程非常简单,因为 LangChain 集成了维基百科文档加载器以及文本分块模块。
from langchain.document_loaders import WikipediaLoaderfrom langchain.text_splitter import CharacterTextSplitter# Read the wikipedia articleraw_documents = WikipediaLoader(query="Leonhard Euler").load()# Define chunking strategytext_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=20)# Chunk the documentdocuments = text_splitter.split_documents(raw_documents)# Remove summary from metadatafor d in documents:del d.metadata['summary']
由于 Neo4j 是一个图形数据库,使用有关 Leonhard Euler 的维基百科文章作为示例是比较合适的。接下来,我们使用 tiktoken 文本分块模块,该模块使用 OpenAI 制作的分词器,将文章分成具有1000个标记的块。我们可以在本文中了解有关文本分块策略的更多信息。
LangChain WikipediaLoader 默认为每个块添加一个摘要。我认为添加的摘要有点多余。例如,如果我们使用向量相似性搜索来检索前三个结果,则摘要将重复三次。因此,我决定将其从数据集中删除。
03
使用 Neo4j 存储文本并为其建立索引
✦
LangChain 可以轻松地将文档导入 Neo4j 并使用新添加的向量索引对其进行索引,官方尽可能地使其用户友好,这意味着我们无需了解有关 Neo4j 或图形的任何知识即可使用它。另一方面,官方为更有经验的用户提供了几个自定义选项,这些选项官方都会出单独的文章进行介绍。
Neo4j 向量索引被包装为 LangChain 向量存储,因此遵循用于与其他向量数据库交互的语法。
from langchain.vectorstores import Neo4jVectorfrom langchain.embeddings.openai import OpenAIEmbeddings# Neo4j Aura credentialsurl="neo4j+s://.databases.neo4j.io"username="neo4j"password="<insert password>"# Instantiate Neo4j vector from documentsneo4j_vector = Neo4jVector.from_documents(documents,OpenAIEmbeddings(),url=url,username=username,password=password)
该 from_documents 方法连接到 Neo4j 数据库,导入并嵌入文档,并创建向量索引。默认情况下,数据将表示为“Chunk”节点。如前所述,我们可以自定义数据的存储方式以及返回哪些数据。不过,这将在下面的文章中讨论。
如果我们已有包含填充数据的现有向量索引,则可以使用该 from_existing_index 方法。
04
向量相似度搜索
✦
我们将从简单的向量相似性搜索开始,以验证一切是否按预期工作。
query = "Where did Euler grow up?"results = neo4j_vector.similarity_search(query, k=1)print(results[0].page_content)
结果如下:

LangChain 模块使用指定的嵌入函数(本例中为 OpenAI)嵌入问题,然后通过比较用户问题和索引文档之间的余弦相似度来找到最相似的文档。
Neo4j 向量索引还支持欧几里得相似度度量以及余弦相似度。
05
LangChain 问答工作流程
✦
LangChain 的好处是它支持仅使用一两行代码的问答工作流程。例如,如果我们想要创建一个问答系统,根据提供的上下文生成答案,同时还提供它用作上下文的文档,我们可以使用以下代码。
from langchain.chat_models import ChatOpenAIfrom langchain.chains import RetrievalQAWithSourcesChainchain = RetrievalQAWithSourcesChain.from_chain_type(ChatOpenAI(temperature=0),chain_type="stuff",retriever=neo4j_vector.as_retriever())query = "What is Euler credited for popularizing?"chain({"question": query},return_only_outputs=True,)
结果如下:

正如我们所看到的,LLM 根据提供的维基百科文章构建了准确的答案,但也返回了它使用的源文档。我们只需要一行代码就可以实现这一点。
在测试代码时,我注意到并不总是返回源代码。这里的问题不是 Neo4j Vector 实现,而是 GPT-3.5-turbo。有时,它不听指令返回源文档。但是,如果我们使用 GPT-4,问题就会消失。
最后,为了复制 ChatGPT 界面,我们可以添加一个内存模块,该模块还为 LLM 提供对话历史记录,以便我们可以提出后续问题。同样,我们只需要两行代码。
from langchain.chains import ConversationalRetrievalChainfrom langchain.memory import ConversationBufferMemorymemory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0), neo4j_vector.as_retriever(), memory=memory)
现在我们来测试一下。
print(qa({"question": "What is Euler credited for popularizing?"})["answer"])
结果如下:

现在是一个后续问题。
print(qa({"question": "Where did he grow up?"})["answer"])
结果如下:

— 总结 —
向量索引是 Neo4j 的一个重要补充,使其成为处理 RAG 应用程序的结构化和非结构化数据的出色解决方案。希望 LangChain 集成能够简化将向量索引集成到现有或新的 RAG 应用程序中的过程,这样我们就不必担心细节。请记住,LangChain 已经支持生成 Cypher 语句并使用它们来检索上下文,因此我们现在可以使用它来检索结构化和非结构化信息。
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

