




背景
在日常工作中,经常会遇到一些明明创建了对应的索引,但实际的SQL执行并未使用该索引。原因有很多的可能,记录一下最常见的几种可能。
情况1:B*Tree 索引,谓词没有使用索引的最前列:
- 表为空表:走索引
– 测试环境复现生产问题需要数据量基本相同。
create table t (x varchar(100),y varchar(100));
create index ind_x_y on t(x,y);
SQL> set autotrace trace
SQL> select * from t where y='a';
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 268342853
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 104 | 1 (0)| 00:00:01 |
|* 1 | INDEX FULL SCAN | IND_X_Y | 1 | 104 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("Y"='a')
filter("Y"='a')
复制- 插入数据:走全表
–因为谓词中没有用到X列
SQL> insert into t select rownum,rownum from dual connect by level < 1000000;
999999 rows created.
SQL> commit;
Commit complete.
SQL> set autotrace trace
SQL> select * from t where y='a';
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 28 | 2912 | 714 (2)| 00:00:09 |
|* 1 | TABLE ACCESS FULL| T | 28 | 2912 | 714 (2)| 00:00:09 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("Y"='a')
复制- 跳跃式索引扫描(index skip scan)
– 当索引前置列值重复率高时会走跳跃索引扫描
SQL> create table t as
2 select decode(mod(rownum,2),0,'M','F') gender,all_objects.* from all_objects;
SQL> create index t_id on t(gender,object_id);
SQL> exec dbms_stats.gather_table_stats(user,'T');
SQL> set autotrace traceonly explain;
SQL> select * from t where object_id=42;
复制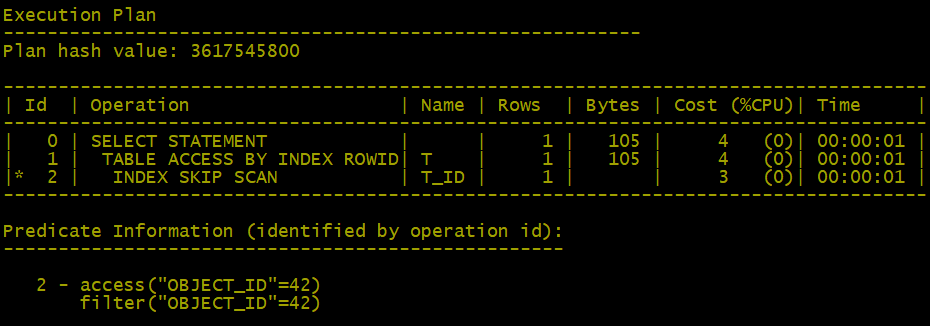
– 它会跳跃扫描索引,并将期看成是两个索引:一个对应值M,另一个对应值F。
select * from t where object_id=42;
-- 相当于:
select * from t where gender='F' and object_id=42;
union all
select * from t where gender='M' and object_id=42;
复制– 降低GENDER 的重复值,那么Oracle 很可能就不再认为跳跃扫描是一个可行的计划:
-- 增加一下列的长度
SQL>alter table t modify gender varchar2(10);
-- 更新值:1256 个重复值,如果oracle 走跳跃索引扫描的话,需要跳1256 次。因此Oracle 觉得全表扫描更为合适。
SQL>update t set gender=chr(mod(rownum,1256));
101030 rows updated.
SQL>exec dbms_stats.gather_table_stats(user,'T');
SQL> set autotrace traceonly explain
SQL> select * from t where object_id=42;
复制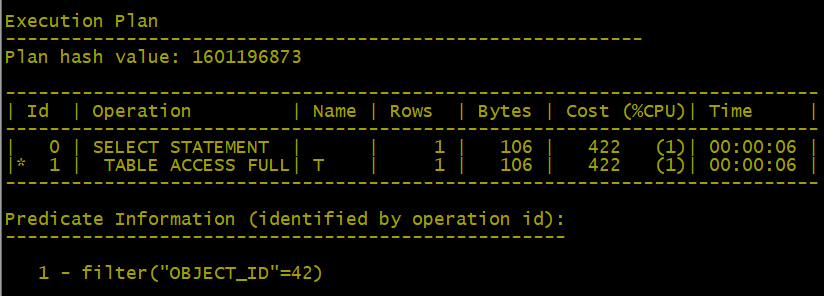
情况2:
我们的查询类似于select count() from T,表T上有个BTree 索引。尽管索引要比表小很多,但针对这个查询,优化器给出的执行计划并不是去索引中统计有多少个索引条目,而是对表进行全表扫描。
在这个案例中,索引列值可以全部都是null,表上没做任何约束。由于某行数据的索引列全部为null时,索引中就不会为这行数据建立索引条目,所以索引可能跟表中的行数并不一致。这里优化器的选择是对的,使用索引来统计行数很可能会得到错误的答案。
-- 重建T表
SQL> drop table t purge;
SQL> create table t as
2 select 'a' gender,all_objects.* from all_objects;
SQL> update t set gender=null;
101030 rows updated.
SQL> create index t_id on t(gender);
SQL> exec dbms_stats.gather_table_stats(user,'T');
SQL> select count(*) from t;
复制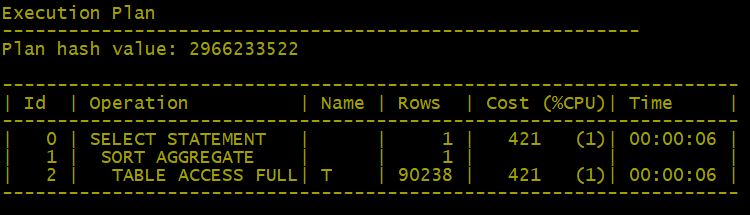
情况3:
我们给一列加了索引,但是下面这个SQL动没用到索引
select * from t where f(indexed_column) = value
复制 原因是这个列上使用了函数。我们的索引是针对index_column,而不是F(indexed_column)的值而建立的,所以数据库在这里用不到这个索引。解决方案是再建个基于函数的索引。
这种情况很好理解,就不再列举示例了。
- 未完待续
- Oracle 总结:为什么不走索引(二)
最后修改时间:2023-11-06 09:19:19
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
文章被以下合辑收录
评论
杜伟

0年前
评论
 0
0 在日常工作中,经常会遇到一些明明创建了对应的索引,但实际的SQL执行并未使用该索引。原因有很多的可能
0年前
点赞 评论
잘생긴 오빠😎

1年前
评论
0很详细,学习了。
1年前
点赞 评论
相关阅读
Oracle RAC 一键安装翻车?手把手教你如何排错!
Lucifer三思而后行
565次阅读
2025-04-15 17:24:06
【纯干货】Oracle 19C RU 19.27 发布,如何快速升级和安装?
Lucifer三思而后行
494次阅读
2025-04-18 14:18:38
Oracle SQL 执行计划分析与优化指南
Digital Observer
465次阅读
2025-04-01 11:08:44
XTTS跨版本迁移升级方案(11g to 19c RAC for Linux)
zwtian
456次阅读
2025-04-08 09:12:48
墨天轮个人数说知识点合集
JiekeXu
456次阅读
2025-04-01 15:56:03
【ORACLE】记录一些ORACLE的merge into语句的BUG
DarkAthena
443次阅读
2025-04-22 00:20:37
Oracle数据库一键巡检并生成HTML结果,免费脚本速来下载!
陈举超
431次阅读
2025-04-20 10:07:02
【ORACLE】你以为的真的是你以为的么?--ORA-38104: Columns referenced in the ON Clause cannot be updated
DarkAthena
418次阅读
2025-04-22 00:13:51
Oracle 19c RAC更换IP实战,运维必看!
szrsu
404次阅读
2025-04-08 23:57:08
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
375次阅读
2025-04-17 17:02:24



