




首发个人公众号 spark技术分享 , 同步个人网站 coolplayer.net ,未经本人同意,禁止一切转载
我们有一部分的数据处理流程是
数据 -> kafka -> spark streaming -> es -> kibana
外部数据先落入kafka队列做缓冲, spark streaming 微批处理后把指标打到 es, 然后 es 里面做二次聚合展示在 kibana 上
首先本人不是很精通 elasticsearch, 但是在很长的运维实际中多少也积累了一点经验,这次碰到的问题,是从今天早上 9点开始发现监控数据没有了, 定位了一些 root cause, 发现是es集群使用的 一个 磁盘 坏掉了,
然后找运维更换磁盘, 我们es 集群是使用 ansible 部署的, 机器配置是
32core,150G memory, 12 块 4T sata 盘
我们每台机器上部署 四个 es 实例, 第一个实例作为协调节点,其余三个实例作为mdi(master/data/ingest)节点。
现在是其中一台机器的 /disk7 坏掉了, 通过es 的 monitoring 发现那个实例的 status 已经变成了 offline,
我这边先手动把 那台实例 停掉, 让运维先进行换盘, 看了下 spark streaming job 的状态,发现已经开始报错
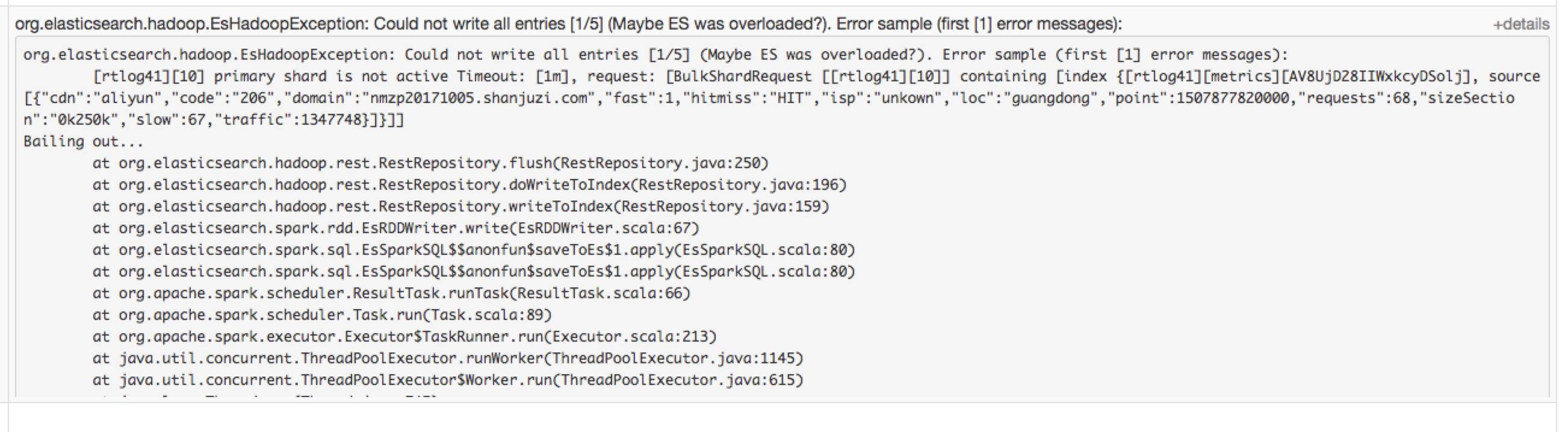
org.elasticsearch.hadoop.EsHadoopException: [xxx][15] primary shard is not active Timeout
对应的index 的分片, 就被分配在那台下掉的实例上
等到 运维换过盘, 重新启动 es 实例,发现es 的数据都没有了,因为是监控数据, 丢掉倒也无妨,启动es实例后发现 spark streaming job 还在报错。
查看了下 index 的分片状态
GET _cat/shards/rtlog41
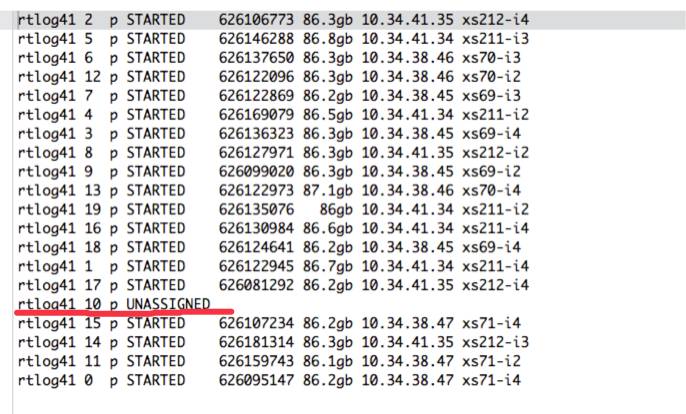
发现有个分片还是 unassingned 状态, 因为我对 es 也属于小白状态,有点懵了, 按照常理,现在应该已经恢复了, 就深入研究了下 es 的 recovery 机制, recovery 流程是
如果某个shard主片在,副片所在结点挂了,那么选择另外一个可用结点,将副片分配(allocate)上去,然后进行主从片的复制。
如果某个shard的主片所在结点挂了,副片还在,那么将副片升级为主片,然后做主副复制。
如果某个shard的主副片所在结点都挂了,则暂时无法恢复,等待持有相关数据的结点重新加入集群后,从结点上恢复主分片,再选择某个结点分配复制片,并从主分片同步数据。
我查看了下之前在es建index的命令,发现设置的 number_of_replicas 都是 1, 也就是每个分片都只有一个副本,
那么现在因为换盘整个, 磁盘里面主分片的数据都没有了,还恢复个毛啊,
我现在决定要把 这个 unassingned 的分片进行手动分配,查了下, 还可以通过 ES 的 reroute 接口,可以手动完成对分片的分配选择的控制。
看了下官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-reroute.html
里面有几种命令
移动(move) 把分片从一节点移动到另一个节点。可以指定索引名和分片号。
取消(cancel) 取消分配一个分片。可以指定索引名和分片号。node参数可以指定在那个节点取消正在分配的分片。allow_primary参数支持取消分配主分片。
分配(allocate) 分配一个未分配的分片到指定节点。可以指定索引名和分片号。node参数指定分配到那个节点。allow_primary参数可以强制分配主分片,不过这样可能导致数据丢失。
现在又多了两个命令可以把 primary shard 分配到一个节点上,
allocate_stale_primary 表示准备分配到的节点上可能有老版本的历史数据,运行时请提前确认一下是哪个节点上保留有这个分片的实际目录,且目录大小最大。然后手动分配到这个节点上。以此减少数据丢失。
allocate_empty_primary 分配一个空的主分片到一个 节点上,
我查看了下机器的负载情况,找了一台相对比较空闲的 es 实例。
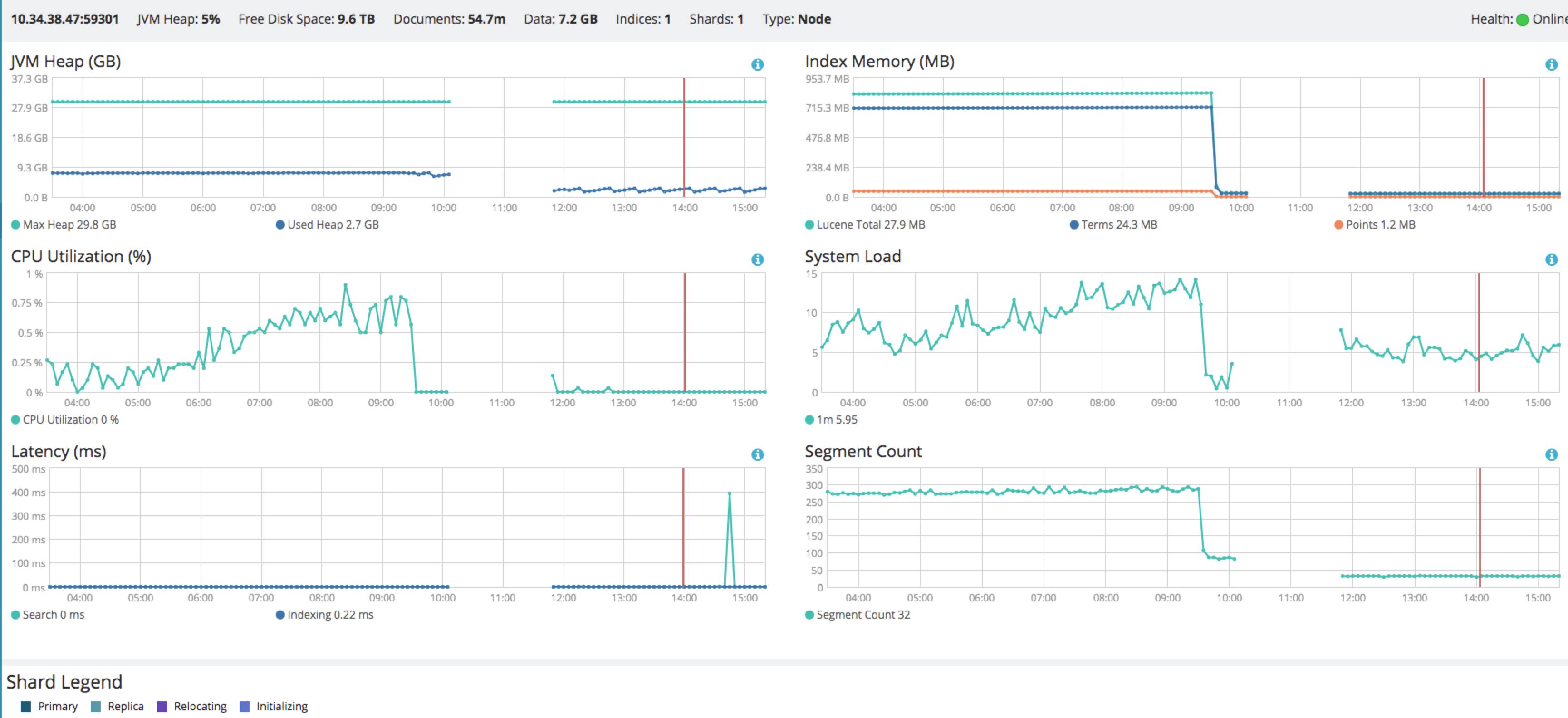
一开始我也没太搞清楚这几种操作的区别, 我先使用了 allocate_stale_primary 命令
POST _cluster/reroute { "commands" : [ { "allocate_empty_primary" : { "index" : "xxx", "shard" : 10, "node" : "xxx", "accept_data_loss" : true } } ] }
命令返回 400, 看了下 es 集群服务器的日志
org.elasticsearch.indices.recovery.RecoveryFailedException: [xxx][10]: Recovery failed on Caused by: org.elasticsearch.index.shard.IndexShardRecoveryException: shard allocated for local recovery (post api), should exist, but doesn't, current files: [] Caused by: org.apache.lucene.index.IndexNotFoundException: no segments* file found in store(mmapfs(/xxx)): files: []
意思就是没有找到 recover 需要的老数据
后面我就使用 allocate_empty_primary 命令, 执行成功了, 然后再查询 index 的分片情况, 所有的分片都已经恢复, index 的 状态 也 从red 变为了 green 了。
spark streaming 的报错也恢复了,大工搞成,
得到的经验教训就是 不能因为想打es速度快一些,就把分片副本数设置为 1, 会导致集群可用性下降,需要再权衡一下
欢迎关注 spark技术分享

