




点击上方蓝字关注我们
全文共2168字,建议阅读用时7分钟。

简介
对于 Redis,我们的第一反应是用做缓存服务,但是 Redis 的另外两种用途就比较少人了解了,Redis 官网首页对 Redis 的介绍如下:
“Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.”
Redis 不仅仅是作为缓存服务,它还可以作为正儿八经的消息队列和数据库来使用。本篇文章重点谈谈 Redis 做为消息队列使用的方法、原理和场景。
Stream 的结构
Redis Stream 是2018年发布 Redis 5.0 中最显著的新增特性,相比原来不支持持久化的 PubSub (发布和订阅),它提供了强大的一对多的可持久化的消息队列,并且也引入了类似 Kafka 的 Consumer Group 的概念,支持同一个 Group 内的多个消费者负载消费同一条消息队列中的消息。
由于 Redis 是基于内存的消息队列,因此相比 Kafka,它有着一些完全不同的特性:比如 Redis Stream 支持在整个消息队列上随机读取和删除,而Kafka 不支持删除历史消息,对频繁的读取历史消息的效率也非常低;又比如 Redis Stream 对消息队列(Topic)的数量是没有限制的,即使同时读写大量的消息队列,整体的性能也不会有重大影响,而 Kafka 由于基于磁盘的连续文件读写特性,对于同时读写大量的消息队列会导致整体性能明显的下降。
因此 Redis Stream 作为一个消息队列新方案,值得我们去研究一下,看看在哪些场景下可以作为主力消息队列使用。
Redis Stream 的结构如下图所示,每条 Stream 都有唯一的名称,它就是 Redis 的 key,它的内部结构是一条消息链表,新消息持续追加到链表的尾部,每一个消息有一个唯一的 ID 和对应的内容。
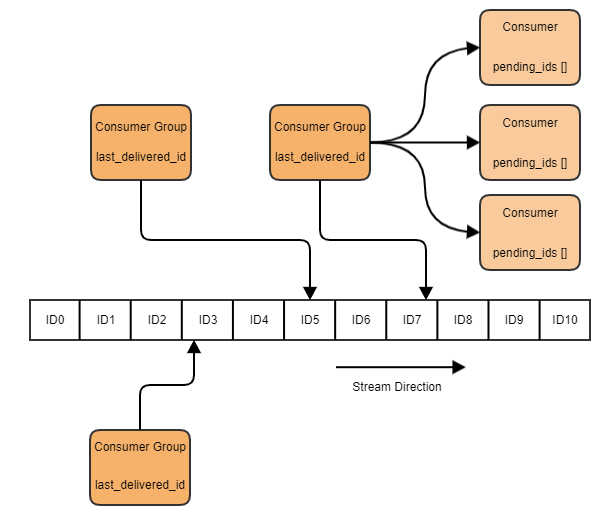
每一个 Stream 上可以挂多个 Consumer Group,Group 之间相互独立,Group 内保存着一个 last_delivered_id 的指针,指向消息队列中当前消费组最新的消费位置。
每一个 Consumer Group 内包含多个 Consumer,这些 Consumer 竞争消费队列中的消息,任何 Consumer 取出消息都会让 Group 的 last_delivered_id 向前移动。取出的消息的 ID 都会保存在消费者的 pending_ids 列表中,消息 Ack 后就会从这个 pending_ids 中移除。
对比 Kafka 的结构,Redis Stream 有两个明显的区别:
Redis Stream 中没有 Partition 的概念,一个 key 就是一条消息队列,而 Kafka 是一个 Topic 内有多个 Partition,每个 Partition 都是一条消息队列。
Redis Stream 允许 Group 内多个 Consumer 同时读取一条消息队列,而 Kafka 每个 Partition 只允许一个 Group 内的一个 Consumer 读取。
由于存在着上述的区别,当需要保证消息被有序处理时,Redis Stream 就需要在应用层额外多做一些事情,保证每个 Stream 只能被唯一的消费者处理。
命令实操
Redis Stream 提供的命令有点多,为了方便理解可以大致分为如下四组:
1、增删
XADD:在消息队列尾部追加消息。
XDEL:删除消息队列中指定ID的消息。
2、随机读
XRANGE:从队列前往后获取范围内的消息。
XREVRANGE:从队列后往前获取范围内的消息。
XREAD:读取一条或者多条队列的新增消息,支持堵塞读取,直到有新增消息到来后返回。
3、分组读取
XGROUP:创建一个消费组。
XREADGROUP:Group内读取一条或者多条队列的消息,Group内消费者不会读取到重复的消息。
XACK:Ack消息。
XPENDING:查询Group内,被消费者取走但还没有Ack的消息(pending message)。
XCLAIM:改变 pending message 的所属消费者。
4、队列管理
XLEN:查看队列长度
XTRIM:将队列长度缩减到设定的长度
下面我们将用这些命令做实际操练一遍。我们将创建一个 Stream,在 Stream 内创建一个 Group,Group 内启动两个 Consumer,然后测试消息的发布,接收和 Ack。
创建一个 Stream teststream,同时创建一个名字为 testgroup 的分组, $ 参数表示指定这个分组从最新的消息开始消费,类似 kafka 的 auto.offset.reset 设置为 latest,如果设置 0 的话就相当于 earliest,MKSTREAM 参数表示,如果 Stream 不存在则创建一条新的 Stream。
命令:
XGROUP CREATE teststream testgroup $ MKSTREAM
返回结果:
OK
启动两个属于 testgroup 组的 Consumer,名字分为为 consumer-1,consumer-2,BlOCK 0 的含义是 0 毫秒超时,也就是永远不超时,直到有消息到来命令才从堵塞中返回,STREAMS 参数后面可以指定多个 Stream,这里指向我们刚才创建的 teststream,命令最后的箭头 “>” 表示只消费新的消息,如果设置为一个具体的 ID,这表示可以消费到当前消费者没有 Ack 过的历史消息。
命令:
XREADGROUP GROUP testgroup consumer-1 COUNT 1 BLOCK 0 STREAMS teststream >
XREADGROUP GROUP testgroup consumer-2 COUNT 1 BLOCK 0 STREAMS teststream >
下面我们将用这些命令做实际操练一遍。我们将创建一个 Stream,在 Stream 内创建一个 Group,Group 内启动两个 Consumer,然后测试消息的发布,接收和 Ack。
往 teststream 内发布两条消息,中间的 * 号表示消息的 ID 由 Redis 自动生成 ID,也可以自己指定消息 ID。
命令:
XADD teststream * testfield testvalue1
XADD teststream * testfield testvalue2
两条消息分别被组内的两个消费者接收了。
命令:
XREADGROUP GROUP testgroup consumer-1 COUNT 1 BLOCK 0 STREAMS teststream >
返回结果:
1) 1) "teststream"
2) 1) 1) "1576221281367-0"
2) 1) "testfield"
2) "testvalue1"
命令:
XREADGROUP GROUP testgroup consumer-2 COUNT 1 BLOCK 0 STREAMS teststream >
返回结果:
1) 1) "teststream"
2) 1) 1) "1576221286740-0"
2) 1) "testfield"
2) "testvalue2"
查看 Group 内的没有 Ack 的消息,可以看到有两条消息没有 Ack。
命令:
XPENDING teststream testgroup
返回结果:
1) (integer) 2
2) "1576221281367-0"
3) "1576221286740-0"
4) 1) 1) "consumer-1"
2) "1"
2) 1) "consumer-2"
2) "1"
Ack 消息,Ack 指令没有要求一定要消费者自己 Ack,我们可以同时 Ack 这两条消息。
命令:
XACK teststream testgroup 1576221281367-0 1576221286740-0
再次查看 Group 内 Pending 的消息,已经变成空的了。
命令:
XPENDING teststream testgroup
返回结果:
1) (integer) 0
2) (nil)
3) (nil)
4) (nil)
性能
官方提供了关于 Stream 的一组性能测试数据,测试的场景场景如下:Redis 运行在一个 2 核 PC 上,发送端以每秒 10K 的流量发布消息,在另外多台机器上,有 10 个消费从这个流内消费和 Ack 消息。
结果如下:
Processed between 0 and 1 ms -> 74.11%
Processed between 1 and 2 ms -> 25.80%
Processed between 2 and 3 ms -> 0.06%
Processed between 3 and 4 ms -> 0.01%
Processed between 4 and 5 ms -> 0.02%
99.9%的消息延时 <= 2 毫秒,可以看出 Stream 的性能还是很快的,然后官方没有提供消息的大小,根据经验这些消息应该小于 1KB。
高可用,分片和持久化
Redis Stream 在这些方面和其他的数据结构一样,因此 HA 方案依然是 Master-Slaver 方案,分片使用 Cluster 或 Twemproxy 等方案。
关于持久化,由于 slaver 追踪 master 的数据写入是存在滞后的,因此在 failover 后会有一小段数据丢失,因此使用 Redis 作为消息队列时要小心,仔细考虑这些丢失是否对应用场景来说是否足够安全。
公有云支持情况
公有云 | 是否支持Stream |
AWS ElastiCache | YES |
AZURE Cache | NO |
ALIYUN 云数据库Redis | YES |
三大公有云厂商中 AWS 和 ALIYUN 支持 Redis 5.0 以上版本,AZURE 只支持到 Redis 4 版本,因此也不支持 Stream 数据结构。
总结
Redis Stream 作为消息队列方案中一个新的选择,值得我们去尝试。
总的来说使用 Redis Stream 的理由有:
使用简单,需要资源少。
高性能低延时。
另外一方面,不用 Redis Stream 的理由有:
Failover可能会丢一些消息。
消息有序处理要做额外的工作。
参考文档
https://redis.io/topics/streams-intro
https://blog.csdn.net/enmotech/article/details/81230531
https://blog.logrocket.com/why-are-we-getting-streams-in-redis-8c36498aaac5/
https://www.linkedin.com/pulse/redis-vs-rabbitmq-message-broker-vishnu-kiran-k-v
