




Connector是Flink与外部存储连接的桥梁,Flink在对接外部存储和数据格式上
对于一个外部存储系统的库表来说,需要处理三方面的定义:
connector: 定义了流、批、读、写的实现
Format: 定义了数据的解析
Schema: 定义了表的字段信息
Flink使用Java SPI机制实现插件,方便扩展和管理。Flink更专注于计算,
而各种不同的Connector专注于实现批量读写、流式读写、数据一致性协议、分区、offset和时间戳生成等逻辑
本文主要介绍Flink Connector插件机制
Java SPI
(Service provider interface,服务提供者接口),是Java提供的一套实现扩展的API。
Java SPI是符合接口隔离原则的设计,实现调用者和实现者的解耦,不同的实现方实现了可插拔:
接口定义了交互的"协议"
根据不同的实现方案,定义该接口的不同实现类
调用者根据实际的使用需要,启用、扩展或者替换框架的实现策略
常见的SPI的例子:
数据库驱动加载: JDBC加载不同类型的数据库的驱动
日志门面实现类的加载: Slf4J加载不同提供商的日志实现类
使用介绍:
服务提供者提供接口的实现类,实现类必须含义不带参数的改造方法
在Jar包的
META-INF/services
目录下创建一个以“接口全限定名”为命名的文件,内容为实现类的全限定名;将接口的实现类所在的Jar包放在
classpath
中java.util.ServiceLoder
通过扫描META-INF/services
目录下的配置文件找到实现类,加载类到JVM
ServiceLoader
ServiceLoader
可以跨越jar包获取META-INF下的配置文件通过反射方法Class.forName()加载类对象,并用instance()方法将类实例化
把实例化后的类缓存到providers对象中,(
LinkedHashMap<String,S>
类型)然后返回实例对象
性能损失
延迟加载,需要遍历全部和加载全部实现类
非线程安全
TableFactory的定义
flink-table-common模块中定义了TableFactory的接口、调用者和工具类,
TableFactory
package org.apache.flink.table.factories;
/**
用于从基于字符串的属性中创建与表相关的不同实例的一个工厂。该工厂使用Java的服务提供商接口(SPI)做服务发现,使用一组描述所需配置的规范化属性来调用工厂。工厂允许匹配给定的属性集。
将实现此接口的类添加到要找到的当前类路径中的JAR文件的"META_INF/services/org.apache.flink.table.factories.TableFactory"文件中
*/
public interface TableFactory {
/**
指定为此工厂实现的Context。该框架保证仅在满足指定的属性和值集的情况下才与此工厂匹配。
典型的属性可能是:
-connector.type
-format.type
指定的属性版本允许框架在字符串格式更改的情况下提供向后兼容的属性:
-connector.property
-version-format.property-version
空上下文意味着工厂匹配所有请求。
*/
Map<String, String> requiredContext();
/**
返回该工厂可以处理的属性键列表。此方法将用于验证。如果传递了该工厂无法处理的属性,则将引发异常。该列表不得包含上下文指定的键。
示例属性可能是:
- schema.#.type
- schema.#.name
- connector.topic
- format.line-delimiter
- format.ignore-parse-errors
- format.fields.#.type
- format.fields.#.name
注意:使用“#”表示值的数组,其中“#”表示一个或多个数字。诸如“ format.property-version”之类的属性版本不得成为受支持属性的一部分。
在某些情况下,将通配符声明为“ *”可能会很有用。通配符只能在属性键的末尾声明。
例如,如果应支持任意格式:
- format.*
注意:应谨慎使用通配符,因为它们会吞下不受支持的属性,从而可能导致不良行为
*/
List<String> supportedProperties();
}
以flink-hbase为例, 在META-INF/services/
中定义了文件org.apache.flink.table.factories.TableFactory
文件的内容为:
org.apache.flink.addons.hbase.HBaseTableFactory这个类就是TableFactory的实现
TableFactory查找
Flink 在 Connector的实现上,也是采用SPI机制
 入口方法:
入口方法: org.apache.flink.table.factories.TableFactoryService#find(java.lang.Class<T>, java.util.Map<java.lang.String,java.lang.String>)
调用样例:
TableFactoryService.find(classOf[TableFactory[_]],sinkProperties)最终调用查找方法
private static <T extends TableFactory> T findSingleInternal(
Class<T> factoryClass,
Map<String, String> properties,
Optional<ClassLoader> classLoader) {
// 查找Factory
List<TableFactory> tableFactories = discoverFactories(classLoader);
// 过滤Factory
List<T> filtered = filter(tableFactories, factoryClass, properties);
if (filtered.size() > 1) {
// 查找到超过1个,抛出异常
throw new AmbiguousTableFactoryException(
filtered,
factoryClass,
tableFactories,
properties);
} else {
return filtered.get(0);
}
}
查找实现类
private static List<TableFactory> discoverFactories(Optional<ClassLoader> classLoader) {
try {
List<TableFactory> result = new LinkedList<>();
ClassLoader cl = classLoader.orElse(Thread.currentThread().getContextClassLoader());
ServiceLoader
.load(TableFactory.class, cl)
.iterator()
.forEachRemaining(result::add);
return result;
} catch (ServiceConfigurationError e) {
LOG.error("Could not load service provider for table factories.", e);
throw new TableException("Could not load service provider for table factories.", e);
}
}
过滤
有三层过滤:
filterByFactoryClass: 判断是否为TableFactory的实现类
filterByContext: 判断必要属性是否匹配: 来源于TableFactory.requiredContext
filterBySupportedProperties: 判断属性是否支持:来源于TableFactory.supportedProperties
TableFactory的分类
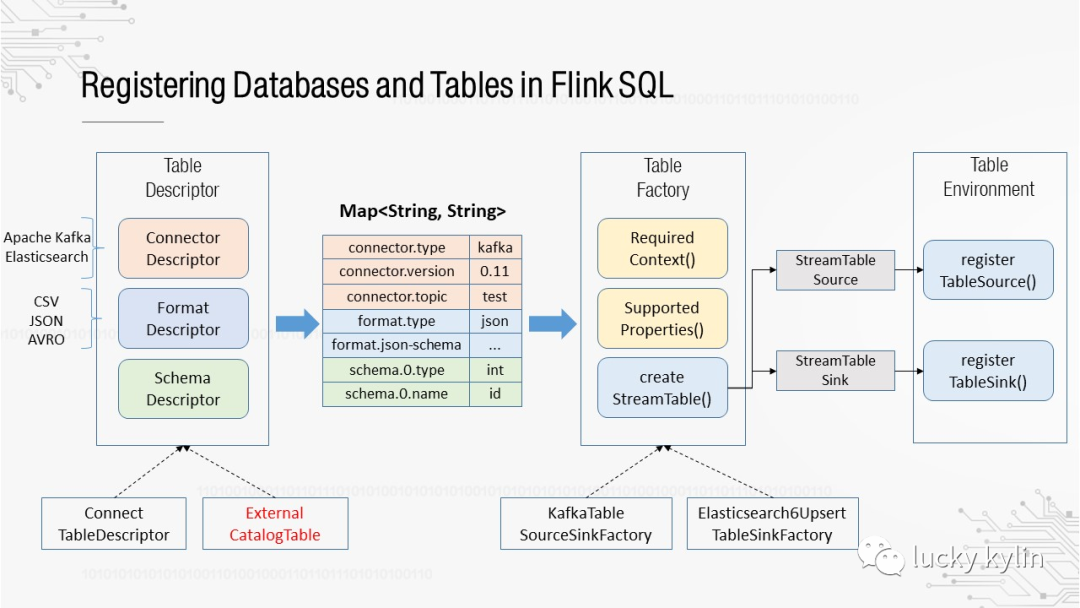
对于一个外部存储系统的库表来说,需要处理三方面的定义:
connector: 定义了流、批、读、写的实现
Format: 定义了数据的解析
Schema: 定义了表的字段信息
Schema信息可以在注册库表的时候直接增加,connector、format信息通过TableFactory实现可插拔

TableFactory可以分为:
StreamTableSourceFactory
StreamTableSinkFactory
BatchTableSourceFactory
BatchTableSinkFactory
TableFormatFactory
常见的Connector样例
援引一张1.10的优化设计图
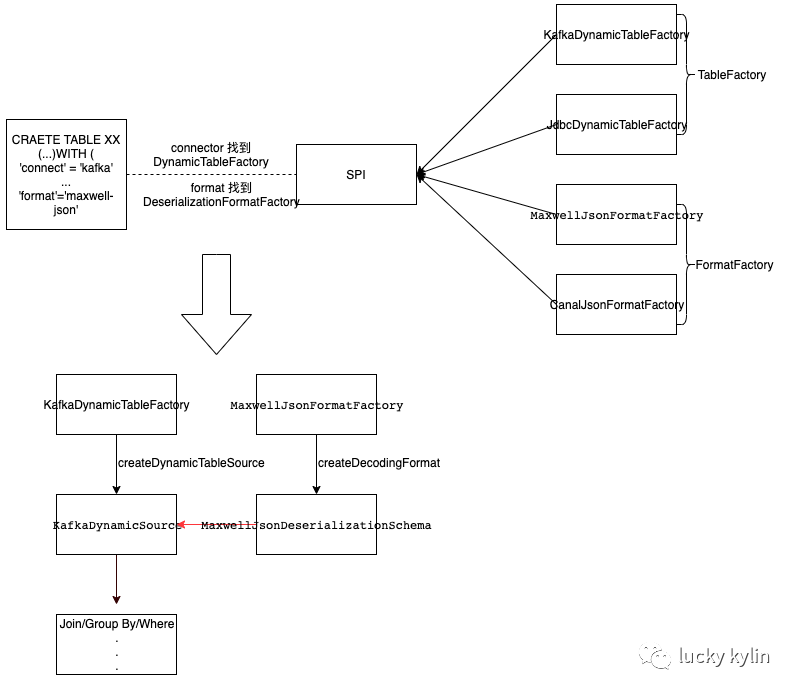
kafka-DDL定义
CREATE TABLE orders_kafka (
...
etime timestamp(3),
watermark for etime as etime - interval '5' second
) WITH (
'connector.type' = 'kafka', -- connector信息
'connector.version' = 'universal',
'connector.topic' = 'kafka-2-mysql-window',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.group.id' = 'order-streaming-test',
'connector.startup-mode' = 'earliest-offset',
'update-mode' = 'append',
'format.type' = 'json', -- format信息
'format.derive-schema' = 'true'
)
MySQL-DDL定义
CREATE TABLE agg_result (
...
time_id STRING
) WITH (
'connector.type' = 'jdbc',
'connector.driver' = 'com.mysql.cj.jdbc.Driver',
'connector.url' = 'jdbc:mysql://localhost:3306/fdata',
'connector.table' = 't_agg_result',
'connector.username' = 'root',
'connector.password' = '---'
)
参考文献
Flink深入浅出:JDBC Connector源码分析
