




1.建立连接
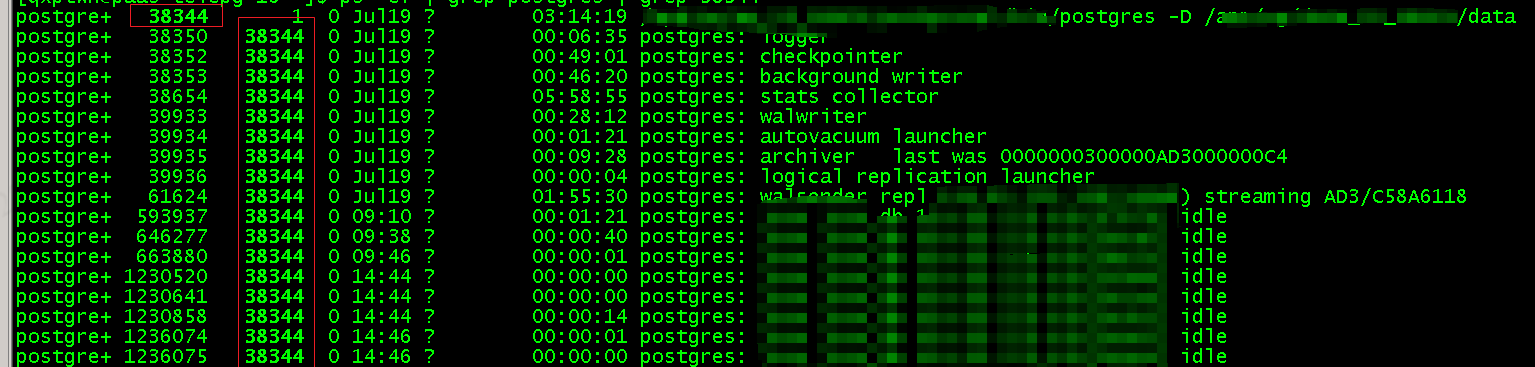
众所周知postgresql是一个进程类型的数据库,启动数据库时就会产生一个postgres主进程和几个保障数据库正常运行子进程后面会单独展开。当一个客户端连接到一个数据库时主进程就会创建一个子进程并且每一个连接都会产生独立的子进程。没有查询任务该子进程就会显示idle状态,如果前端不主动断开这个连接这个连接就会一直存在下去。当然了也可以主动清理,一般建立写一个清理长连接的shell,因为即使是idle的长连接也会占用内存。如果长连接过多并且时间过长会造成内存不够用。
2.查询的执行过程
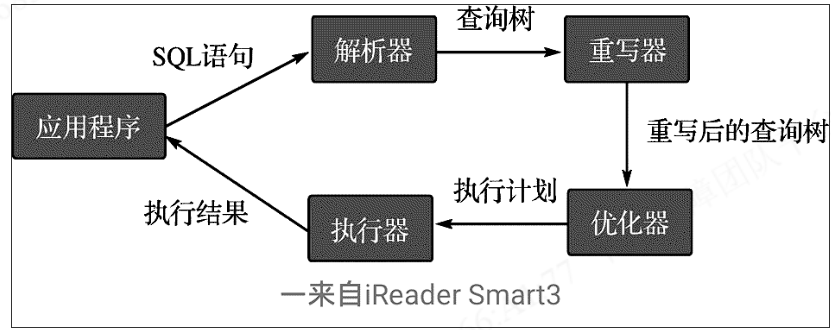
如图,查询会经历四个过程。
2.1 解析器
解析器负责检查接收到的sql文本是否符合规则,如果不符合规则会直接返回语法报错,符合规则会生成一个解析树。该功能主要由词法分析器和语法分析器实现。
词法分析器:负责识别sql文本中的标识符,sql关键词。生成标记输出给语法分析器。
语法分析器:将接收到的标记组合成符合SQL语法的结构。
解析器检测语法错误,比如如果有字段或者表名写错解析器不会报错,此类错误由分析器检查。
2.2 重写器(查询重写)
个人理解并非每个sql语句都会经历重写,这个功能似乎多用于使用了视图的sql,在pg中有一张pg_rewrite的系统表用于存储查询重写规则。
比如当创建一个查询员工表所有数据的视图,可以再创建一个规则系统用来限制用户使用这个视图时只显示部分数据,数据库会根据规则系统自动重写视图中实际的查询树。
2.3 规划器(优化器)
一个解析树的执行顺序可以有很多种,而规划器负责计算出执行速度最快的那个。但是实际生产中一个sql可能会关联许多表如果再使用类似穷举的方式,一个个的排列组合会造成巨大的资源消耗。
为了解决这个问题pg数据库使用了“遗传查询优化器”。通过geqo_threshold参数用来限制,当解析树中连接的表超过12个(参数的默认值)则使用遗传优化器来规划解析树的查询方式。
2.4 执行器
执行器负责将优化后的查询计划转化为实际的物理操作,按照顺序逐个执行每个节点的操作,从底层节点开始,向上层节点传递结果集,直到达到根节点,返回最终的结果集给客户端。
