





大家好,今天和大家聊聊 vacuum freeze的4种模式。
众所周知,由于 txid 是 unsign 32 bit 的长度限制问题, PG 需要定期的冻结一些老的TXID, 从而防止这些老的TXID阻碍 transaction id 的 warp-around.
下面我们看看 PG freeze txid 的 4 种模式:
1.懒惰模式(Lazy mode): vacuum_freeze_min_age
2.饥渴模式(Eager mode): vacuum_freeze_table_age
3.强制模式 (Forced mode): autovacuum_freeze_max_age
4.安全保护模式(Failsafe mode): vacuum_failsafe_age
(上面的中文翻译是我自己起的名字,并不是官方名称, 英文的名字Lazy和Eager 是来自于JP作家的internals那本著作,Forced和Failsafe 来自于俄罗斯的PG14 internals的那本著作)
| 冻结模式 | 触发参数 | 默认数值 | 表级别参数设置 |
|---|---|---|---|
| 懒惰模式(Lazy mode) | vacuum_freeze_min_age | 50000000 | autovacuum_freeze_min_age and toast.autovacuum_freeze_min_age |
| 饥渴(侵略)模式(Eager mode) | vacuum_freeze_table_age | 150000000 | autovacuum_freeze_table_age and toast.autovacuum_freeze_table_age |
| 强制模式 (Forced mode) | autovacuum_freeze_max_age | 200000000 | autovacuum_freeze_max_age and toast.autovacuum_freeze_max_age |
| 安全保护模式(Failsafe mode) | vacuum_failsafe_age(PG14开始支持) | 1600000000 | NA |
我们可以看到 触发的参数从 5千万->1.5亿->2亿->16亿 逐步递增。
我们先来看看 Lazy mode 的触发条件和限制:
freezeLimit_txid =(OldestXmin−vacuum_freeze_min_age)
这里的OldestXmin 指的是元祖上最老的年龄(当前current_txid- xmin), vacuum_freeze_min_age 是系统参数默认是 50000000
freezeLimit_txid 是表上的元祖的最老的年龄-系统参数vacuum_freeze_min_age 得到的限制冻结的TXID的值。
freezeLimit_txid 这个值作为基准值,对于年龄比这个freezeLimit_txid 大的元祖进行freeze的操作。
这里值得注意的是 Lazy mode并不会对所有的 age > freezeLimit_txid 元祖进行freeze, lazy模式会跳过没有死元祖的page(通过visibility map),
所以 Lazy_mode的freeze 并不彻底,存在 tuple age > freezeLimit_txid 并不会freeze的情况,这可能也是叫懒惰模式的原因吧
我们来借用JP作家的图描述一下:
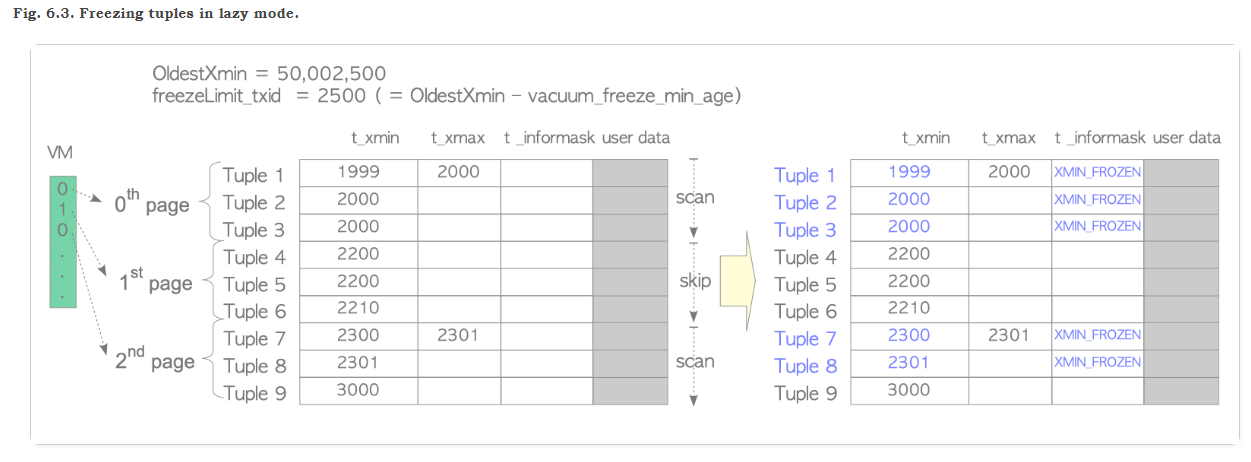
当vacuum或者autovacuum process 触发的时候, 当前表T有3个page, 每个page中有3条记录,假设表的年龄为 50002500, 系统参数vacuum_freeze_min_age 是系统参数默认是 50000000
我们根据公式 50002500 - 50000000 = 2500, 这个2500即为 freeLimit_txid的值.
当进行vacuum的时候,根据VM的位图的标记:
1.会跳过没有死元组的page1,不会进行任何freezed的操作
2.扫描page0的时候,发现元组 tuple1,tuple2,tuple3 的xmin分别是1999,2000,2000, 全部小于 freeLimit_txid, 则3条记录全部标记为 xmin_frozen的状态
3.扫描page2的之后,tuple7和tuple8的xmin为2300,2301 均小于 freeLimit_txid =2500,这2条记录的状态标记为 xmin_frozen的状态。而tuple9的xmin为3000,大于 freeLimit_txid, 保持状态不变,
由于Lazy mode 并不能保证所有达到freezeLimit_txid 的元祖freeze, 才引入了饥渴模式的freeze,这个模式也叫侵略模式aggressive mode
从名字上也可以看出饥渴模式是有侵入性的,会读取扫描目标表相关所有的page, 不再会参考 visibility map. 这里指的是PG9.6之前的版本。
对于9.6之后的版本,会根据VM位图中的 all_frozen 的标记位跳过之前已经完全被freeze的page,从而减小了IO的读取,达到了优化的目的。
我们来看一下触发 Eager mode的条件:
pg_database.datfrozenxid < (OldestXmin − vacuum_freeze_table_age)
这里pg_database.datfrozenxid是数据库最早冻结的xid(也就是这个数据库中年龄最大的表中的xmin)
我们还是借助于JP作家的图来描述一下:
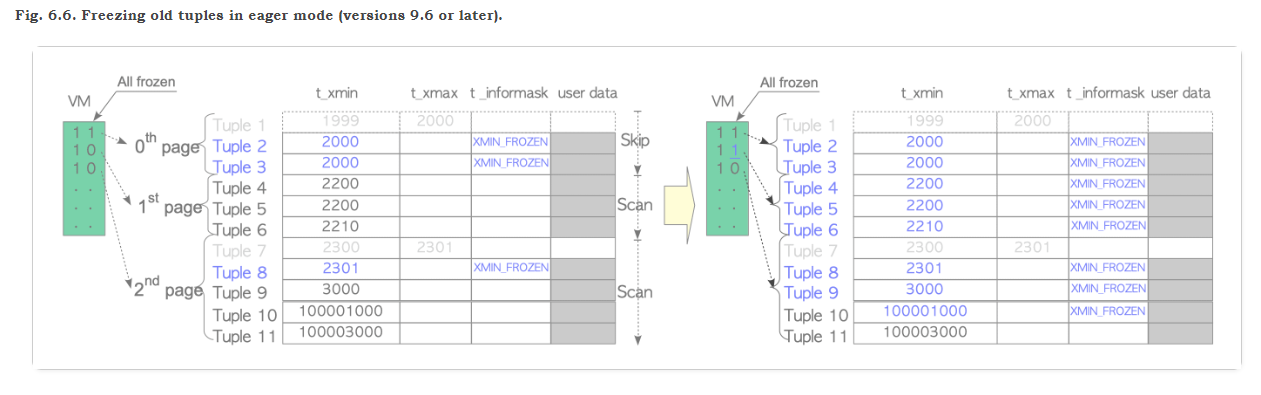
当vacuum和autovacuum运行的时候: 当前表T有3个page, 每个page中的tuple分布如上图,假设表T的xmin 为2200 ,当前的txid 是150002500,vacuum_freeze_table_age 系统参数默认为 150000000
那么表T的年龄 150002500 - 2200 = 150000300 > vacuum_freeze_table_age (vacuum_freeze_table_age ) 触发Eager mode freeze:
此时同样需要根据 freezeLimit_txid =(150002500−50000000)=100002500,来作为冻结的阈值 ,即为小于100002500 全部冻结
1.同样根据VM 来判断,page0在VM的位图中标记为 all_frozen为1,直接跳过page0
2.扫描page1, tuple 4, tuple5, tuple6的xmin 全部小于 freezeLimit_txid(100002500),则全部标识为冻结,并且更新VM标记page1的 all frozen为1
3.继续扫描page 2, tuple 9和tuple 10 的 xmin 全部小于 freezeLimit_txid(100002500), 进行freeze操作, 而tuple11的xmin 为100003000 大于freezeLimit_txid(100002500),则保持状态不变。
VM 中page2的 all frozen 则保持为0不变
我们简单动手最一个例子加深对Lazy mode和 Eager mode的理解:
1.创建一张表 t_freeze , fillfactor = 10 保留90%的空间,设置autovacuum_freeze_min_age=200: 下调lazy mode freeze 的门槛到200
postgres=# CREATE TABLE t_freeze(
postgres(# id integer,
postgres(# name char(300)
postgres(# )
postgres-# WITH (fillfactor = 10,autovacuum_freeze_min_age=200);
CREATE TABLE
2.手动插入100条数据:
postgres=# INSERT INTO t_freeze(id, name)
postgres-# SELECT id, 'JASON'||id FROM generate_series(1,100) id;
INSERT 0 100
3.查看表的年龄: 这个时候表的年龄 233 大于我们设置的表级别的lazy mode freeze的参数 autovacuum_freeze_min_age=200
postgres=# SELECT
postgres-# c.oid::regclass as table_name,
postgres-# pg_size_pretty(pg_total_relation_size(c.oid::regclass)) as table_size,
postgres-# least(c.relfrozenxid::text::int,t.relfrozenxid::text::int) as relfrozenxid,
postgres-# greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age
postgres-# FROM pg_class c
postgres-# LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
postgres-# WHERE c.relkind IN ('r', 'm') and c.oid::regclass::text = 't_freeze';
table_name | table_size | relfrozenxid | age
------------+------------+--------------+-----
t_freeze | 424 kB | 8554153 | 233
(1 row)
4.这个时候我们手动执行 vacuum table:
postgres=# vacuum t_freeze;
VACUUM
理论上这个时候会触发 lazy mode 的free: 但是由于VM 的存在, freeze 跳过了这些 page:
all_visible 都是 T, 即为可见,
all_frozen 都是 F, 全部没有冻结
postgres=# select count(1),all_visible,all_frozen from pg_visibility('t_freeze') group by all_visible,all_frozen ;
count | all_visible | all_frozen
-------+-------------+------------
50 | t | f
(1 row)
5.我们尝试删除一些记录,造成一些空的page,目的是使这些page在VM中像是为F , 即为不可见,这样LAZY mode才回去冻结这些page
再删除9条记录之后
postgres=# delete from t_freeze where id < 10;
DELETE 9
postgres=# select count(1),all_visible,all_frozen from pg_visibility('t_freeze') group by all_visible,all_frozen ;
count | all_visible | all_frozen
-------+-------------+------------
5 | f | f
45 | t | f
(2 rows)
6.我们再次查询表的年龄,由于上次VM的原因,没有被冻结,表的年龄一直往上涨
postgres=# SELECT
postgres-# c.oid::regclass as table_name,
postgres-# pg_size_pretty(pg_total_relation_size(c.oid::regclass)) as table_size,
postgres-# least(c.relfrozenxid::text::int,t.relfrozenxid::text::int) as relfrozenxid,
postgres-# greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age
postgres-# FROM pg_class c
postgres-# LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
postgres-# WHERE c.relkind IN ('r', 'm') and c.oid::regclass::text = 't_freeze';
table_name | table_size | relfrozenxid | age
------------+------------+--------------+------
t_freeze | 432 kB | 8554326 | 1350
(1 row)
手动触发 vacuum table: 这个时候,我们可以观察到LAZY mode 的冻结方式生效了:
4个page 的 all_frozen 已经标记为 all_frozen =f , 由于vacuum同时也删除了死元祖,所以之前删除涉及到的4个page 的all_visible 也全部修改为t
另外的46个page, 由于VM中标记为可见,所以再次被skip过
postgres=# vacuum t_freeze;
VACUUM
postgres=# select count(1),all_visible,all_frozen from pg_visibility('t_freeze') group by all_visible,all_frozen ;
count | all_visible | all_frozen
-------+-------------+------------
4 | t | t
46 | t | f
(2 rows)
接下来,我们再动的模拟一下 Eager模式的冻结: 直接执行命令 vacuum freeze 命令, 目的是把剩余46可page也冻结掉。
这个时候,我们看到50个page全部可见,全部为冻结状态
postgres=# vacuum freeze t_freeze;
VACUUM
postgres=# select count(1),all_visible,all_frozen from pg_visibility('t_freeze') group by all_visible,all_frozen ;
count | all_visible | all_frozen
-------+-------------+------------
50 | t | t
(1 row)
我们再次查看表的年龄,已经下降到了86 (之前年龄是1350)
postgres=# SELECT
postgres-# c.oid::regclass as table_name,
postgres-# pg_size_pretty(pg_total_relation_size(c.oid::regclass)) as table_size,
postgres-# least(c.relfrozenxid::text::int,t.relfrozenxid::text::int) as relfrozenxid,
postgres-# greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age
postgres-# FROM pg_class c
postgres-# LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
postgres-# WHERE c.relkind IN ('r', 'm') and c.oid::regclass::text = 't_freeze';
table_name | table_size | relfrozenxid | age
------------+------------+--------------+-----
t_freeze | 432 kB | 8556214 | 86
(1 row)
我们接下来看一下,强制模式(Forced mode): 2亿是 2的31次方的1/10的大小.
Forced mode主要发生如下的情况
1.Autovacuum 参数关闭了,或者在表级别进行了关闭(WITH (autovacuum_enabled = off),导致 前面2种模式(Lazy和Eager)没有触发。
2.Template0 模板数据库
如果上述2种freeze模式运行正常的话(这里假设也不存在long time transaction的情况),理论上是不会有database中的表的age 大于 vacuum_freeze_table_age(默认即为150000000)长时间存在的情况,这里有一个例外是 template0这个数据库,
template0是在initdb的时候生产的静态库,并且是不允许登录的,所以这个库并不会触发autovacuum,也就不会触发到2种冻结模式了
在生产的巡检中我发现有一个生产库的template0的age 远远大于 vacuum_freeze_table_age(150000000):
template0中最老的表的年龄19亿多:
postgres=# select * from (SELECT datname, age(datfrozenxid) as age FROM pg_database) t order by age desc;
datname | age
-------------+-----------
template0 | 192862306
postgres | 10543365
template1 | 10543309
Let’s google some from 大佬们;
https://stackoverflow.com/questions/62598131/why-does-the-transaction-age-of-template0-db-increase-in-postgresql
Cybertec的CEO 说 template0不需要定时的做vacuum, 当template0的age超过 autovacuum_freeze_max_age(2亿)的时候,
会强制触发freeze.
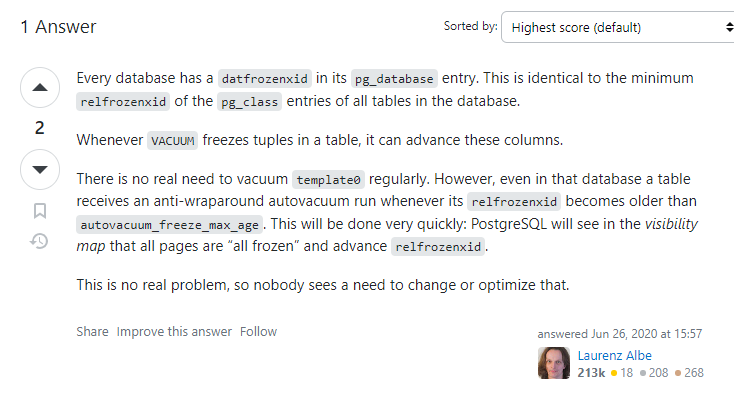
https://postgrespro.com/list/thread-id/2492704
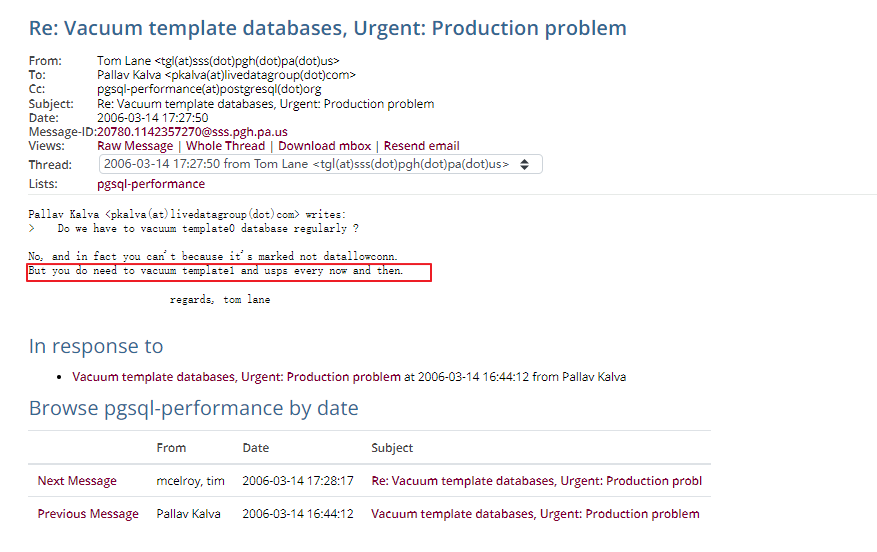
来自于PG core team 的Tom: 大致的意思是你不需要在 template0上做 freeze的监控。 template0足够小,freeze没有任何开销。
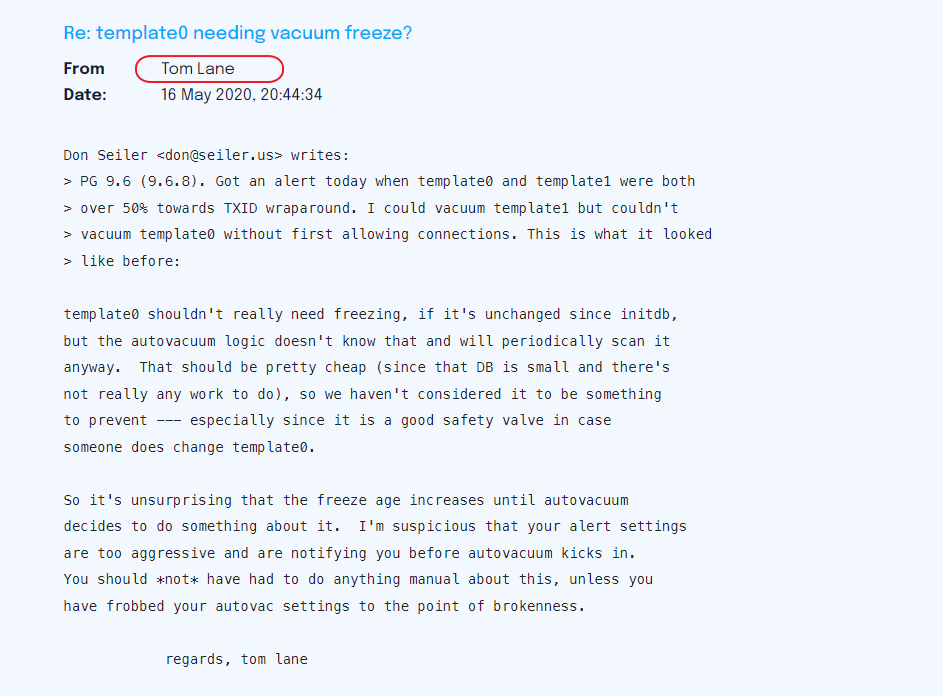
这个时候有人会问 template1这个库需要vacuum吗? 我们需要知道 template1和template0的区别是什么?
对于一个全新的数据库来说, template0就是template1的一个静态copy.
唯一区别是 template0是不允许登录的,不允许修改的。template1的目的是为用户提定制化比如字符集,locate排序什么的自定义模板,是可以改变的。
我们可以参考源码中的注释:
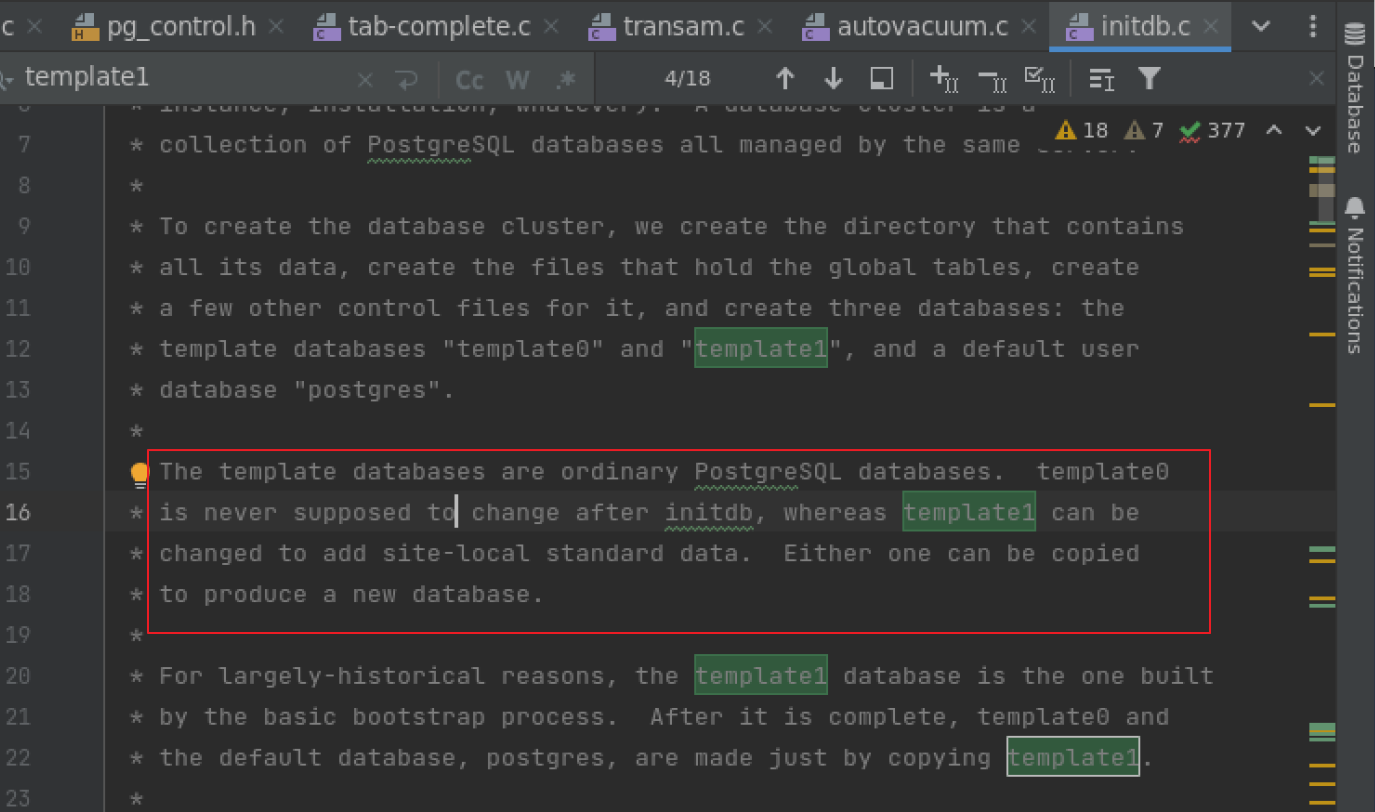
所以我们也就template1由于是可变的,那么需要vacuum来维护。
From PG core team TOM: https://www.postgresql.org/message-id/20780.1142357270%40sss.pgh.pa.us
最后我们来看一下安全保护模式(Failsafe mode: PG14 开始支持):
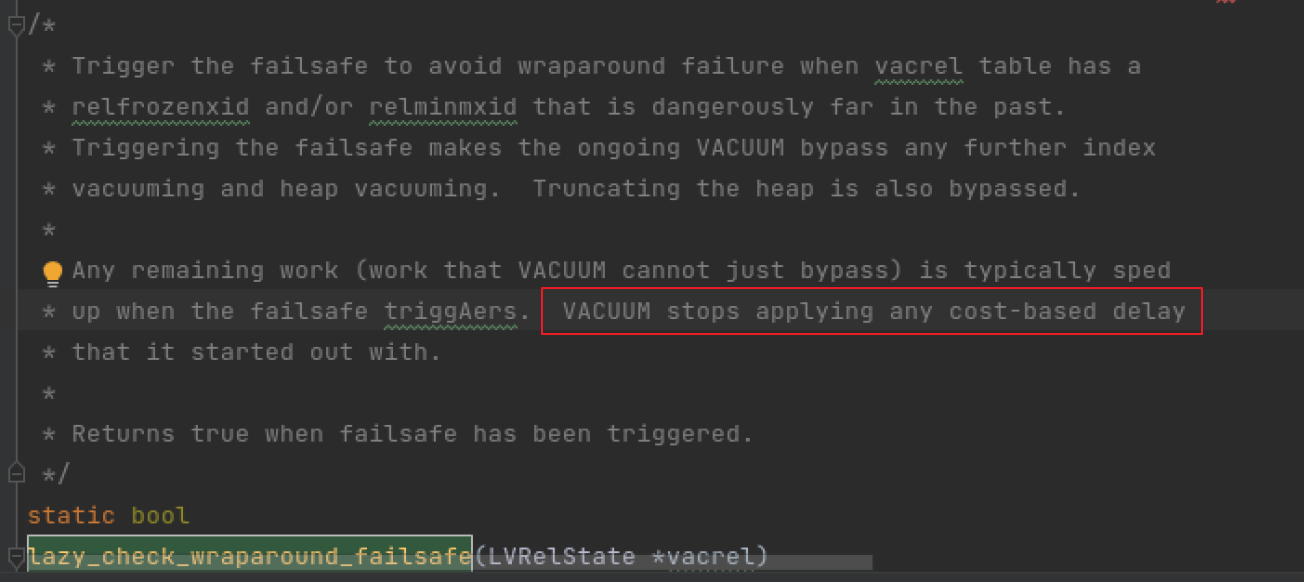
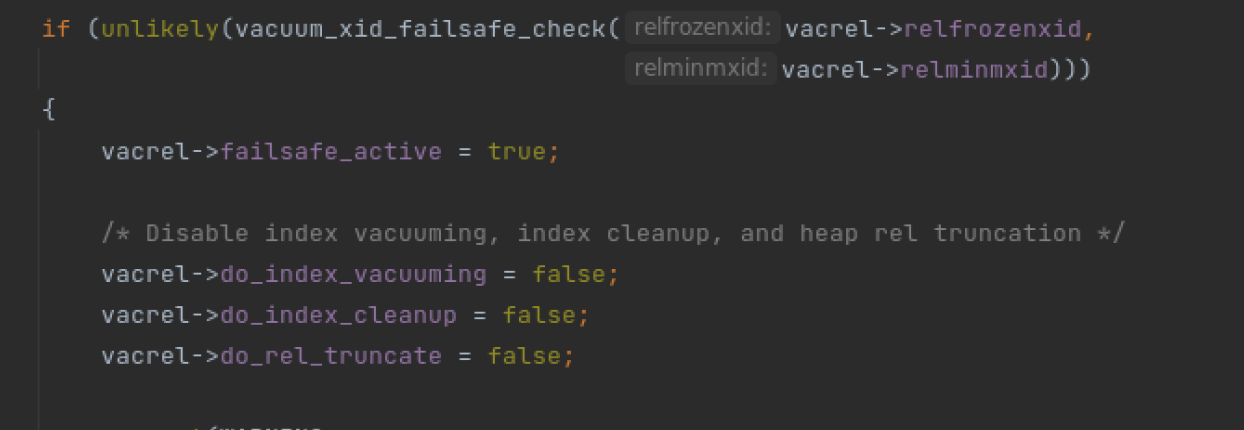
由于某些原因,造成前3种模式freeze 没有冻结成功,于是数据库开始自我抢救: 这种模式下会忽略参数autovacuum_vacuum_cost_delay 并且会过跳过索引的vacuum.
vacuum_failsafe_age= 16亿已经式接近于 20亿大小了
源码触发的函数:backend/access/heap/vacuumlazy.c, lazy_check_wraparound_failsafe function
忽略参数autovacuum_vacuum_cost_delay:
跳过索引:
Okay. 我们已经理解了PG的4种冻结模式,那么在我们实际的生产系统中必须要监控一下数据库表的年龄:
SELECT
c.oid::regclass as table_name,
pg_size_pretty(pg_total_relation_size(c.oid::regclass)) as table_size,
least(c.relfrozenxid::text::int,t.relfrozenxid::text::int) as relfrozenxid,
greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age
FROM pg_class c
LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
WHERE c.relkind IN ('r', 'm')
order by age ;
我们做一个每日定时监控table age 的report :
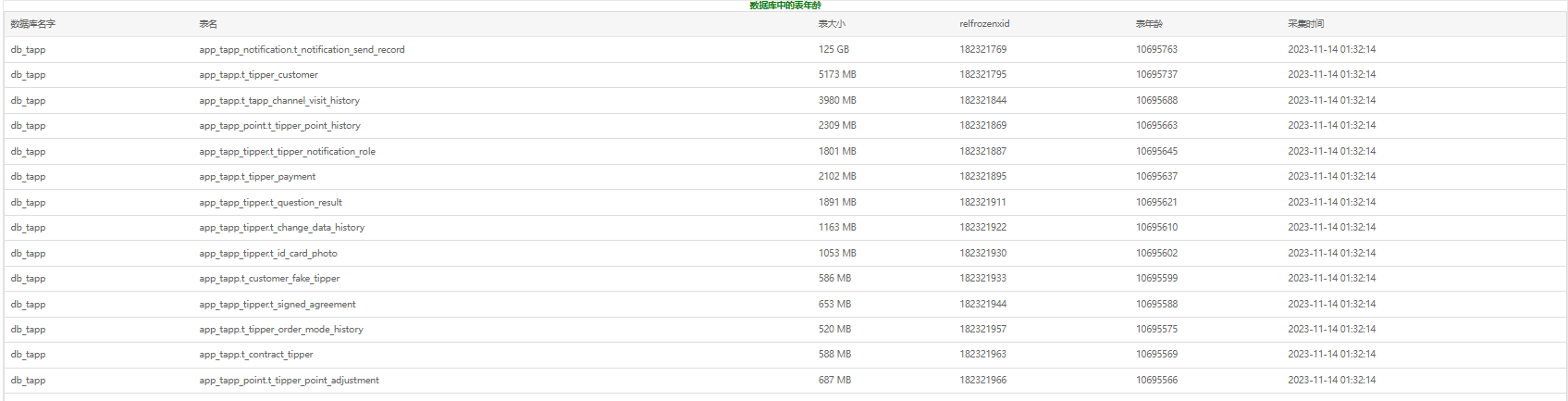
把将要触发eager mode freeze的表列出来找一个业务低峰的时候手动或者脚本进行
vacuum freeze TABLENAME;
最后我们总结一下4种冻结模式:
1.懒惰模式(Lazy mode): table age > vacuum_freeze_min_age(5千万), 冻结不彻底,不能够冻结VM中all_visibility的page
2.饥渴模式(Eager mode): table age > vacuum_freeze_table_age(1.5亿),作为Lazy mode的补漏方案,会根据VM的all_frozen来优化跳过全部冻结的page
3.强制模式 (Forced mode): table age > autovacuum_freeze_max_age (2亿) , 发生在autovacuum没有开启,也没有手动vacuum的情况下,实例中默认创建的template0就是通过这个模式来冻结的。
二另外2个默认的template1和postgres数据库则需要常规的冻结方式。(Lazy mode和Eager mode)
4.安全保护模式(Failsafe mode): table age > vacuum_failsafe_age (16亿), 这个参数是PG14之后引入的,数据库实例进入自我抢救模式或者说是紧急模式:忽略参数autovacuum_vacuum_cost_delay 并且会过跳过索引的vacuum
16亿这个数字已经非常接近 int 32位的一半:20亿。
5.作为生产环境,DBA有必要做table age的监控和报警,定期去在业务低估去去手动的做一些超级大表的 vacuum freeze的操作,目的是避免大表集中爆发freeze, 造成业务高峰高IO,高WAL log 日志量。
对于一些大量的数据迁移特别是(历史归档数据,或者是不变的静态数据): 建议手动的去 vacuum freeze一下归档数据表,这样会更新VM的all_frozen的page,为未来的冻结操作提供了大大的优化。
如果用Psql 原生的copy命令中可以设置参数 FREEZE,这个参数默认会在数据copy完成后,进行 vacuum freeze table的操作。
如果用Kettle, dataworks 这种基于JAVA JDBC的迁移工具, 那么手动执行 vacuum freeze table的操作。
Have a fun 🙂 !
