





一 前言

二 IT系统的可观测性
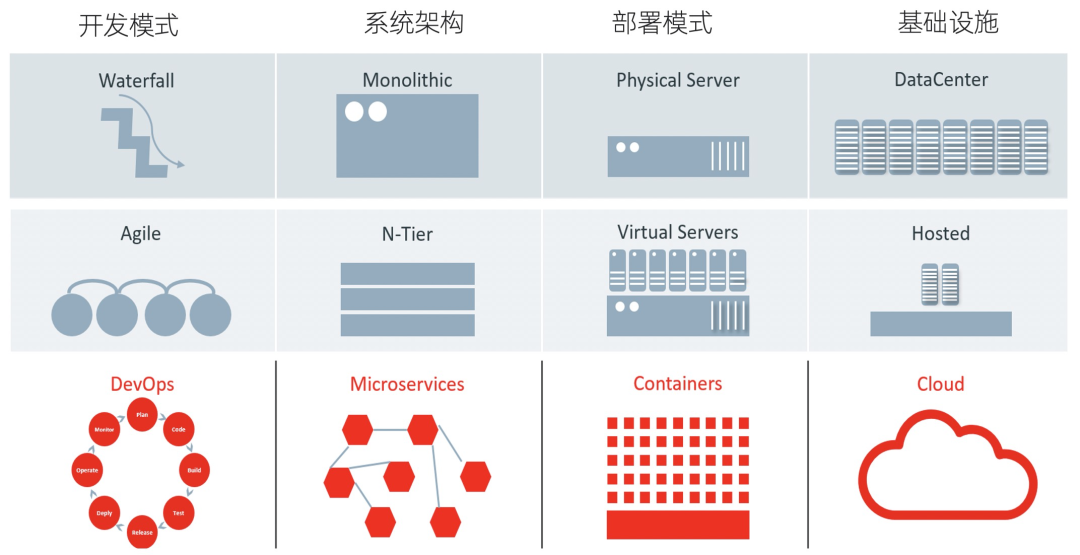
系统更加的复杂:以前的汽车只需要一个发动机、传送带、车辆、刹车就可以跑起来,现在随便一个汽车上至少有上百个部件和系统,故障的定位难度变的更大。
开发涉及更多的人:随着全球化时代的到来,公司、部分的分工也越来越细,也就意味着系统的开发和维护需要更多的部门和人来共同完成,协调的代价也越来越大。
运行环境多种多样:不同的运行环境下,每个系统的工作情况是变化的,我们需要在任何阶段都能有效记录好系统的状态,便于我们分析问题、优化产品。

三 IT可观测性的演进
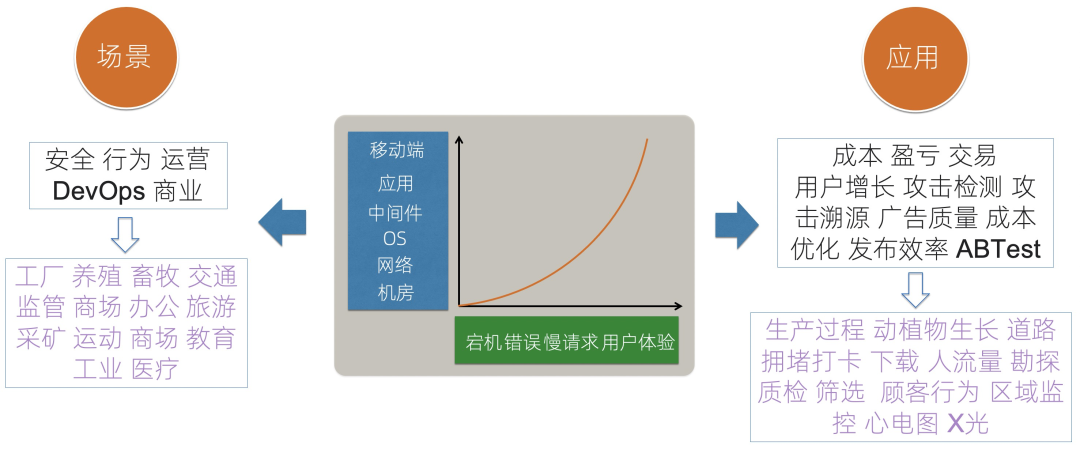
IT运维场景:IT运维场景从横向、纵向来看,观察的目标从最基础的机房、网络等开始向用户的端上发展;观察的场景也从纯粹的错误、慢请求等发展为用户的实际产品体验。 通用场景:观测本质上是一个通用的行为,除了运维场景外,对于公司的安全、用户行为、运营增长、交易等都适用,我们可以针对这些场景构建例如攻击检测、攻击溯源、ABTest、广告效果分析等应用形式。 特殊场景:除了场景的公司内通用场景外,针对不同的行业属性,也可以衍生出特定行业的观测场景与应用,例如阿里云的城市大脑,就是通过观测道路拥堵、信号灯、交通事故等信息,通过控制不同红绿灯时间、出行规划等手段降低城市整体拥堵率。
四 Pragmatic可观测性如何落地
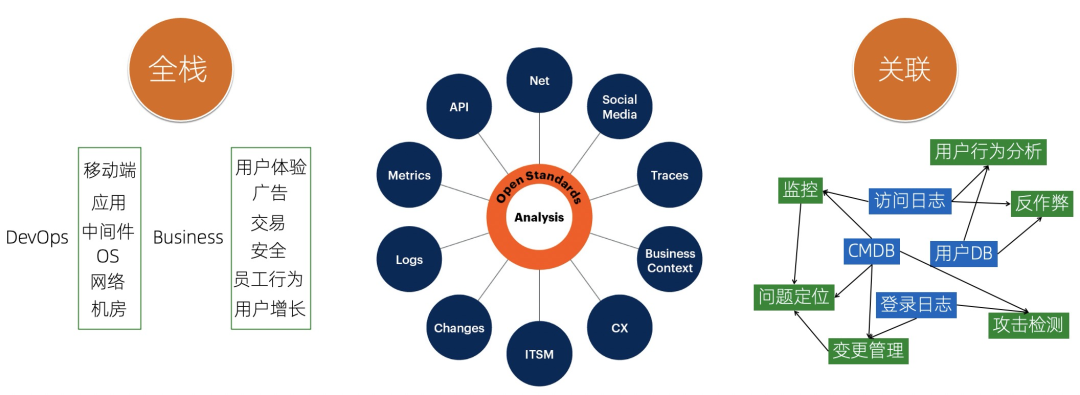
数据的覆盖面足够的全:能够包括各类不同场景的不同类型的数据,除了狭义的日志、监控、Trace外,还需要包括我们的CMDB、变更数据、客户信息、订单/交易信息、网络流、API调用等 数据关联与统一分析:数据价值的发掘不是简单的通过一种数据来实现,更多的时候我们需要利用多种数据关联来达到目的,例如结合用户的信息表以及访问日志,我们可以分析不同年龄段、性别的用户的行为特点,针对性的进行推荐;通过登录日志、CMDB等,结合规则引擎,来实现安全类的攻击检测。

传感器:获取数据的前提是要有足够传感器来产生数据,这些传感器在IT领域的形态有:SDK、埋点、外部探针等。 数据:传感器产生数据后,我们需要有足够的能力去获取、收集各种类型的数据,并把这些数据归类分析。 算力:可观测场景的核心是需要覆盖足够多的数据,数据一定是海量的,因此系统需要有足够的算力来计算和分析这些数据。 算法:可观测场景的终极应用是数据的价值发掘,因此需要使用到各类算法,包括一些基础的数值类算法、各种AIOps相关的算法以及这些算法的组合。
五 再论可观测性数据分类
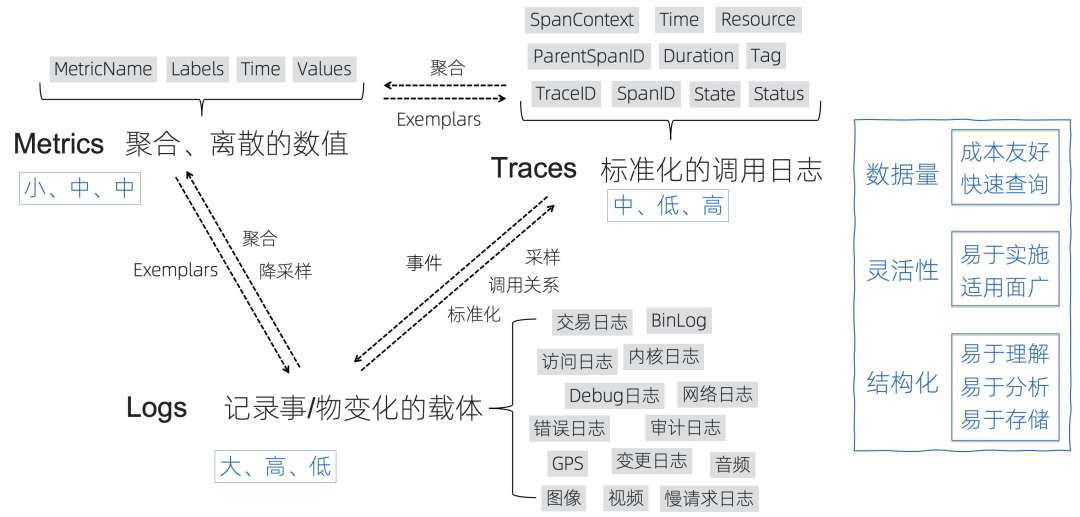
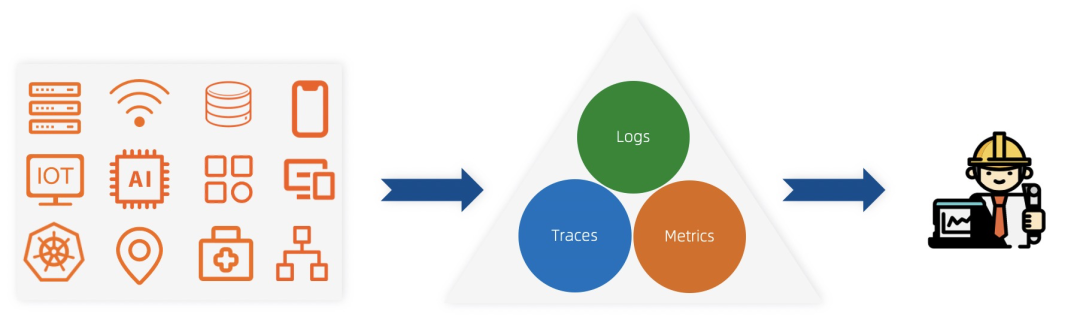
Logs:我们对于Logs是更加宽泛的定义:记录事/物变化的载体,对于常见的访问日志、交易日志、内核日志等文本型以及包括GPS、音视频等泛型数据也包含在其中。日志在调用链场景结构化后其实可以转变为Trace,在进行聚合、降采样操作后会变成Metrics。
Metrics:是聚合后的数值,相对比较离散,一般有name、labels、time、values组成,Metrics数据量一般很小,相对成本更低,查询的速度比较快。
Traces:是最标准的调用日志,除了定义了调用的父子关系外(一般通过TraceID、SpanID、ParentSpanID),一般还会定义操作的服务、方法、属性、状态、耗时等详细信息,通过Trace能够代替一部分Logs的功能,通过Trace的聚合也能得到每个服务、方法的Metrics指标。
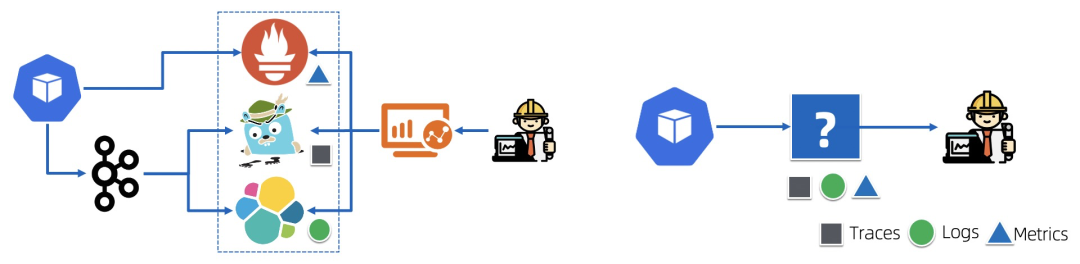
六 “割裂”的可观测性方案

Metrics:Zabbix、Nagios、Prometheus、InfluxDB、OpenFalcon、OpenCensus Traces:Jaeger、Zipkin、SkyWalking、OpenTracing、OpenCensus Logs:ELK、Splunk、SumoLogic、Loki、Loggly
多套方案交织:可能要使用至少Metrics、Logging、Tracing3种方案,维护代价巨大 数据不互通:虽然是同一个业务组件,同一个系统,产生的数据由于在不同的方案中,数据难以互通,无法充分发挥数据价值
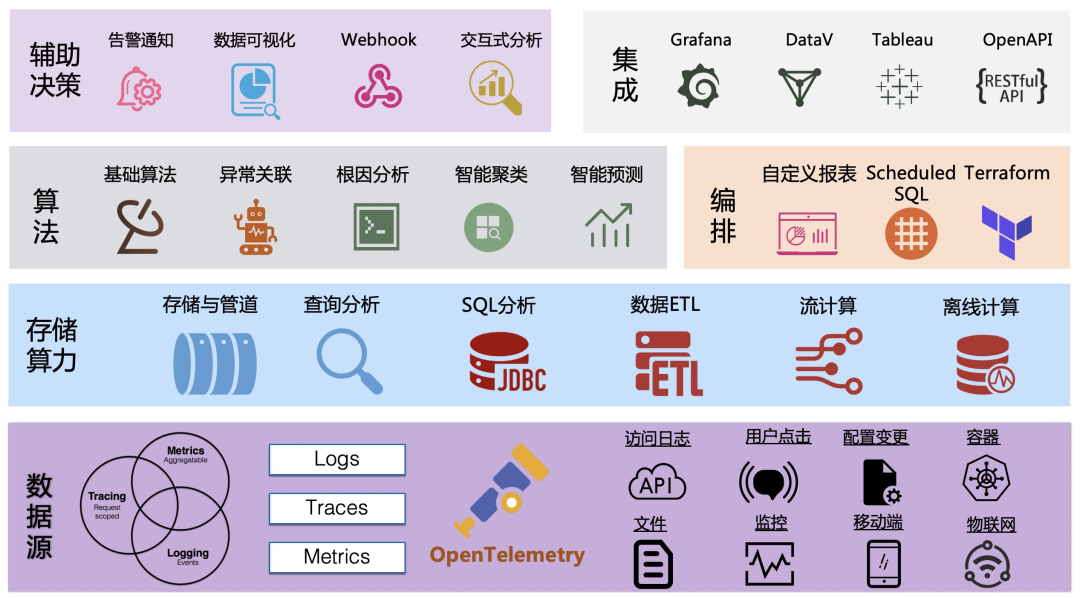
七 可观测性数据引擎架构
数据全面覆盖:包括各类的可观测数据以及支持从各个端、系统中采集数据 统一的系统:拒绝割裂,能够在一个系统中支持Traces、Metrics、Logs的统一存储与分析 数据可关联:每种数据内部可以互相关联,也支持跨数据类型的关联,能够用一套分析语言把各类数据进行融合分析 足够的算力:分布式、可扩展,面对PB级的数据,也能有足够的算力去分析 灵活智能的算法:除了基础的算法外,还应包括AIOps相关的异常检测、预测类的算法,并且支持对这些算法进行编排
传感器:数据源以OpenTelemetry为核心,并且支持各类数据形态、设备/端、数据格式的采集,覆盖面足够的“广”。
数据+算力:采集上来的数据,首先会进入到我们的管道系统(类似于Kafka),根据不同的数据类型构建不同的索引,目前每天我们的平台会有几十PB的新数据写入并存储下。除了常见的查询和分析能力外,我们还内置了ETL的功能,负责对数据进行清洗和格式化,同时支持对接外部的流计算和离线计算系统。
算法:除了基础的数值算法外,目前我们支持了十多种的异常检测/预测算法,并且还支持流式异常检测;同时也支持使用Scheduled SQL进行数据的编排,帮助我们产生更多新的数据。
价值发掘:价值发掘过程主要通过可视化、告警、交互式分析等人机交互来实现,同时也提供了OpenAPI来对接外部系统或者供用户来实现一些自定义的功能。
八 数据源与协议兼容
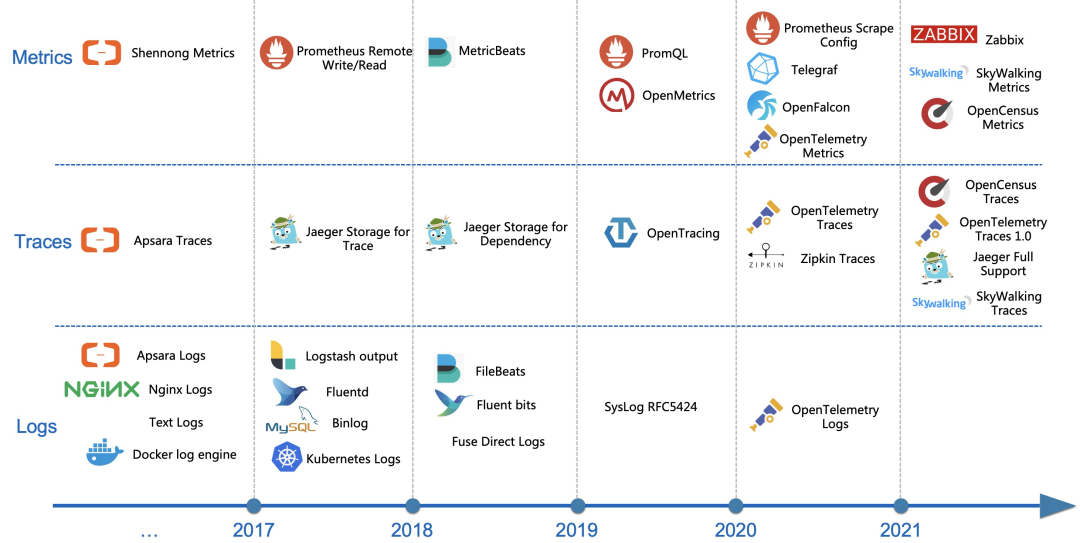
Traces:除了内部的飞天Trace、鹰眼Trace外,开源的包括Jaeger、OpenTracing、Zipkin、SkyWalking、OpenTelemetry、OpenCensus等。
Logs:Logs的协议较少,但是设计比较多的日志采集Agent,我们平台除了自研的Logtail外,还兼容包括Logstash、Beats(FileBeat、AuditBeat)、Fluentd、Fluent bits,同时还提供syslog协议,路由器交换机等可以直接用syslog协议上报数据到服务端。
Metrics:时序引擎我们在新版本设计之初就兼容了Prometheus,并且支持Telegraf、OpenFalcon、OpenTelemetry Metrics、Zabbix等数据接入。
九 统一存储引擎

Logs/Traces:
查询的方式主要是通过关键词/TraceID进行查询,另外会根据某些Tag进行过滤,例如hostname、region、app等
每次查询的命中数相对较少,尤其是TraceID的查询方式,而且命中的数据极有可能是离散的
通常这类数据最适合存储在搜索引擎中,其中最核心的技术是倒排索引
Metrics:
通常都是range查询,每次查询某一个单一的指标/时间线,或者一组时间线进行聚合,例如统一某个应用所有机器的平均CPU
时序类的查询一般QPS都较高(主要有很多告警规则),为了适应高QPS查询,需要把数据的聚合性做好
对于这类数据都会有专门的时序引擎来支撑,目前主流的时序引擎基本上都是用类似于LSM Tree的思想来实现,以适应高吞吐的写入和查询(Update、Delete操作很少)
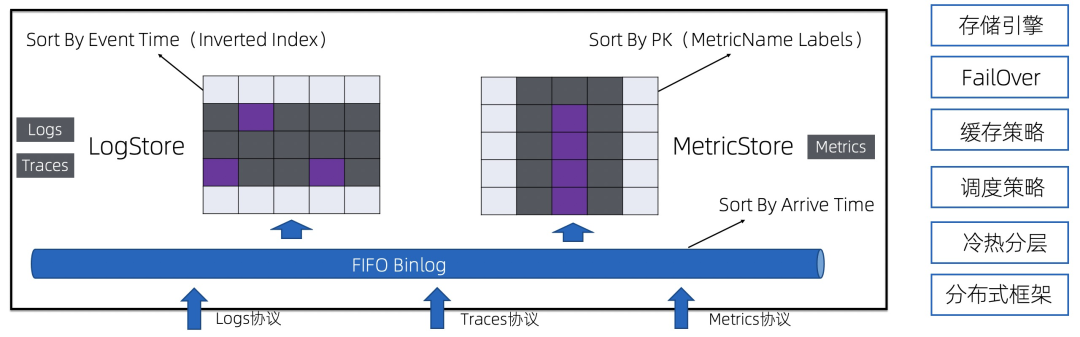
接入层支持各类协议写入,写入的数据首先会进入到一个FIFO的管道中,类似于Kafka的MQ模型,并且支持数据消费,用来对接各类下游 在管道之上有两套索引结构,分别是倒排索引以及SortedTable,分别为Traces/Logs和Metrics提供快速的查询能力 两套索引除了结构不同外,其他各类机制都是共用的,例如存储引擎、FailOver逻辑、缓存策略、冷热数据分层策略等 上述这些数据都在同一个进程内实现,大大降低运维、部署代价 整个存储引擎基于纯分布式框架实现,支持横向扩展,单个Store最多支持日PB级的数据写入
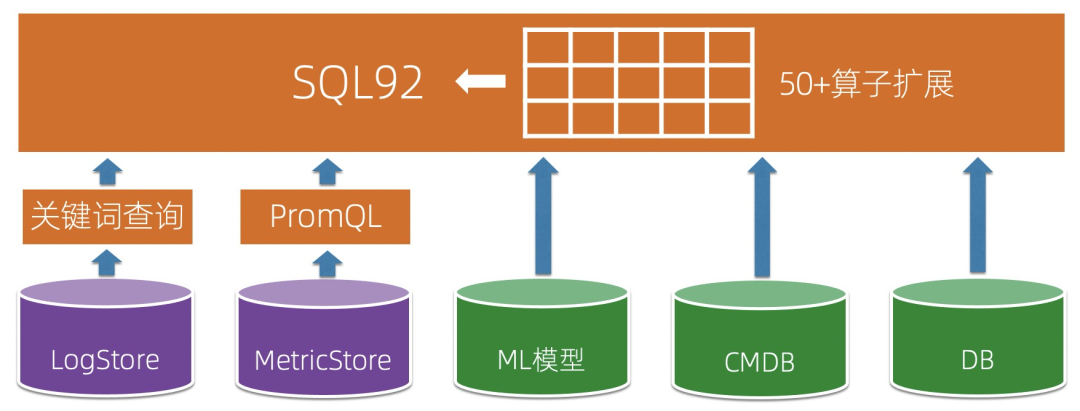
十 统一分析引擎
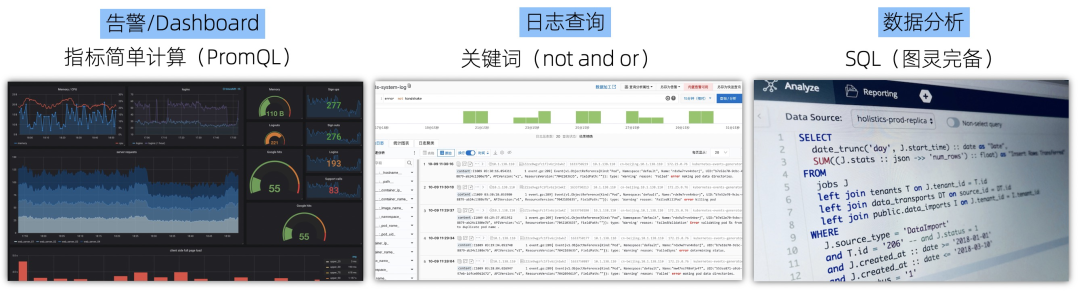
Metrics:通常用于告警和图形化展示,一般直接获取或者辅以简单的计算,例如PromQL、TSQL等 Traces/Logs:最简单直接的方式是关键词的查询,包括TraceID查询也只是关键词查询的特例 数据分析(一般针对Traces、Logs):通常Traces、Logs还会用于数据分析和挖掘,所以要使用图灵完备的语言,一般程序员接受最广的是SQL
背景:线上发现有支付失败的错误,需要分析这些出现支付失败的错误的机器CPU指标有没有问题
实现
首先查询机器的CPU指标 关联机器的Region信息(需要排查是否某个Region出现问题) 和日志中出现支付失败的机器进行Join,只关心这些机器 最后应用时序异常检测算法来快速的分析这些机器的CPU指标 最后的结果使用线图进行可视化,结果展示更加直观

十一 数据编排
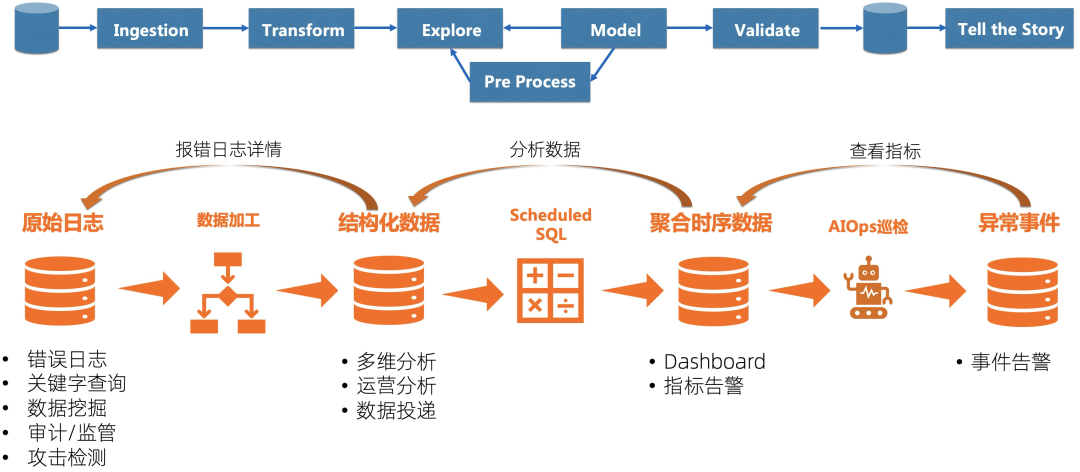
数据加工:也就是大数据ETL(extract, transform, and load)中T的功能,能够帮我们把非结构化、半结构化的数据处理成结构化的数据,更加容易分析。 Scheduled SQL:顾名思义,就是定期运行的SQL,核心思想是把庞大的数据精简化,更加利于查询,例如通过AccessLog每分钟定期计算网站的访问请求、按APP、Region粒度聚合CPU、内存指标、定期计算Trace拓扑等。 AIOps巡检:针对时序数据特别开发的基于时序异常算法的巡检能力,用机器和算力帮我们去检查到底是哪个指标的哪个维度出现问题。
十二 可观测性引擎应用实践
1 全链路可观测
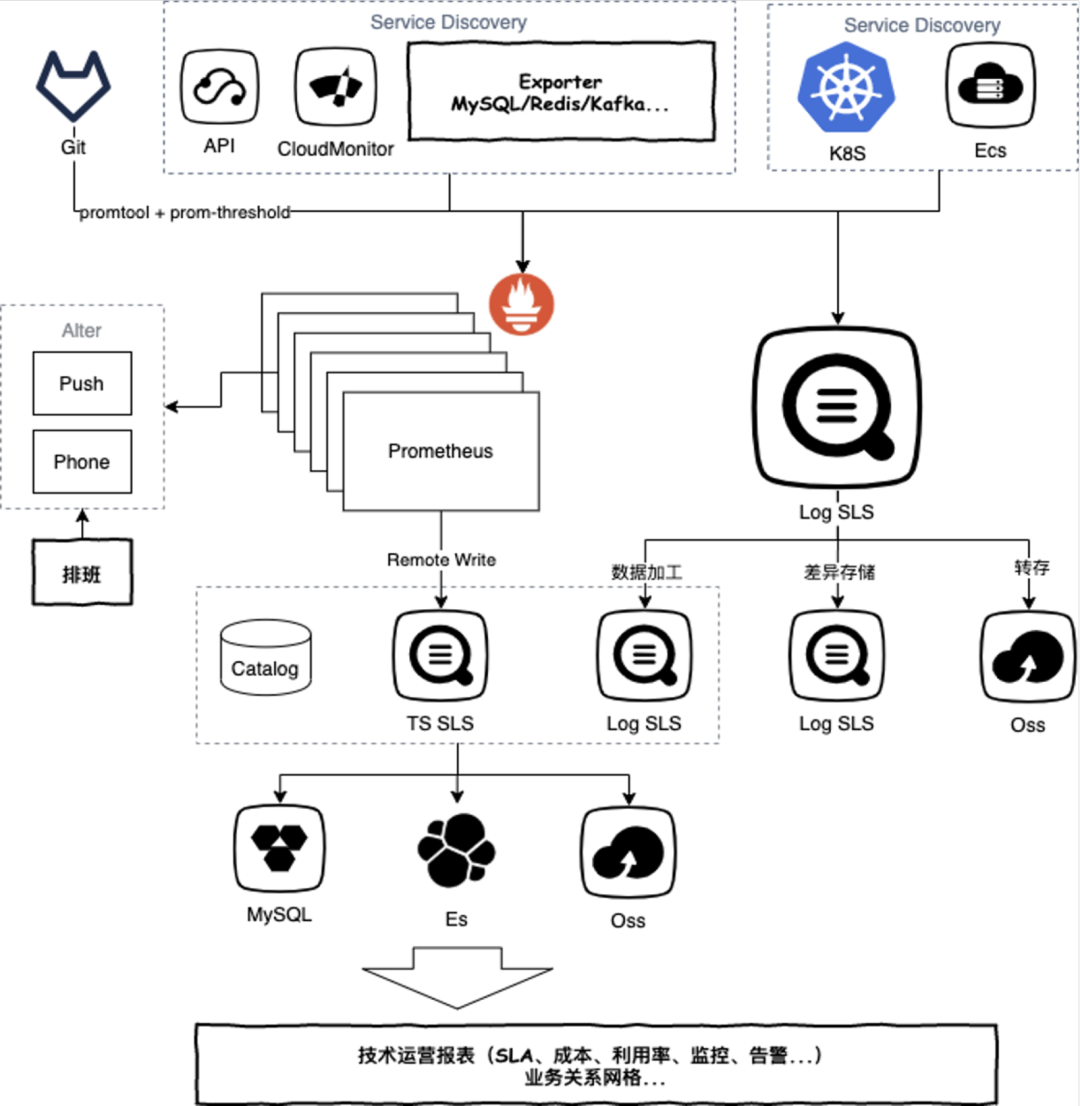
数据源包括移动端、Web端、后端的各类数据,同时还包括一些监控系统的数据、第三方的数据等 采集通过SLS的Logtail和TLog实现 基于离在线混合的数据处理方式,对数据进行打标、过滤、关联、分发等预处理 各类数据全部存储在SLS可观测数据引擎中,主要利用SLS提供的索引、查询和聚合分析能力 上层基于SLS的接口构建全链路的数据展示和监控系统

2 成本可观测
收集云上每个产品(虚拟机、网络、存储、数据库、SaaS类等)的费用,包括详细的计费信息 收集每个产品的监控信息,包括用量、利用率等 建立起Catalog/CMDB,包括每个资源/实例所属的业务部门、团队、用途等
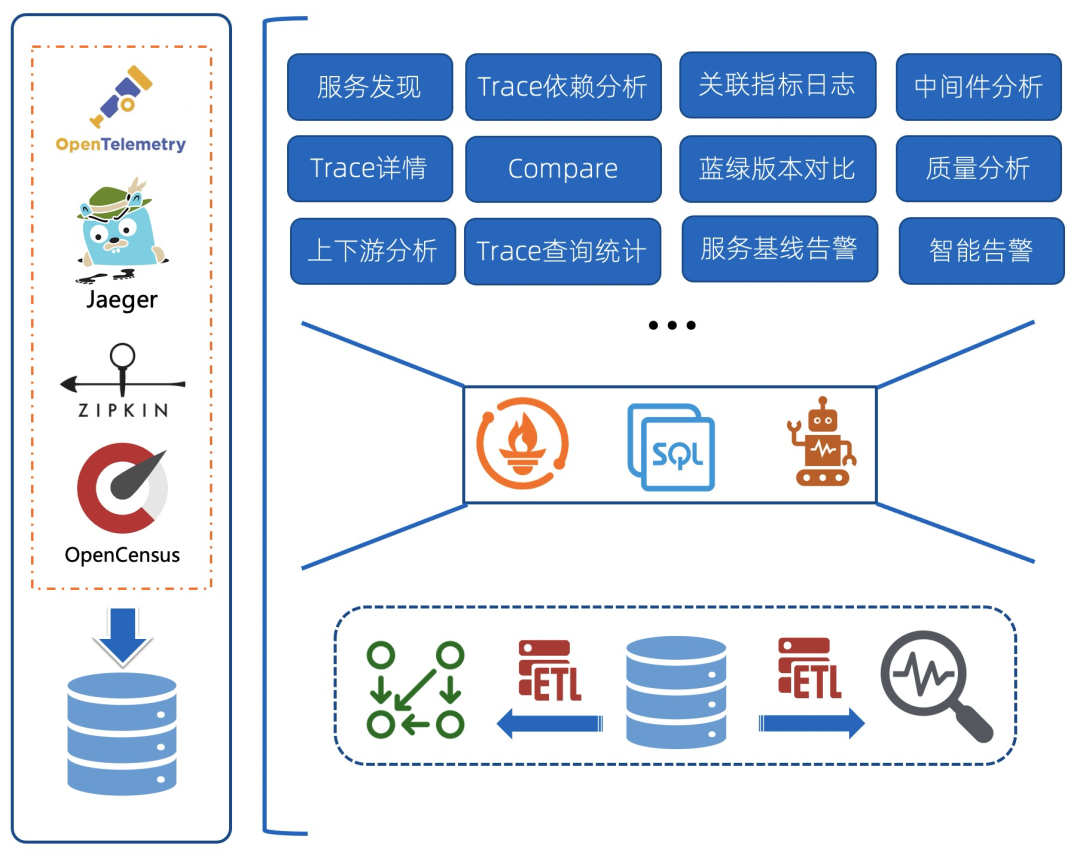
3 Trace可观测
依赖关系:这是绝大部分的Trace系统都会附带的功能,基于Trace中的父子关系进行聚合计算,得到Trace Dependency 服务/接口黄金指标:Trace中记录了服务/接口的调用延迟、状态码等信息,基于这些数据可以计算出QPS、延迟、错误率等黄金指标。 上下游分析:基于计算的Dependency信息,按照某个Service进行聚合,统一Service依赖的上下游的指标 中间件分析:Trace中对于中间件(数据库/MQ等)的调用一般都会记录成一个个Span,基于这些Span的统计可以得到中间件的QPS、延迟、错误率。 告警相关:通常基于服务/接口的黄金指标设置监控和告警,也可以只关心整体服务入口的告警(一般对父Span为空的Span认为是服务入口调用)。
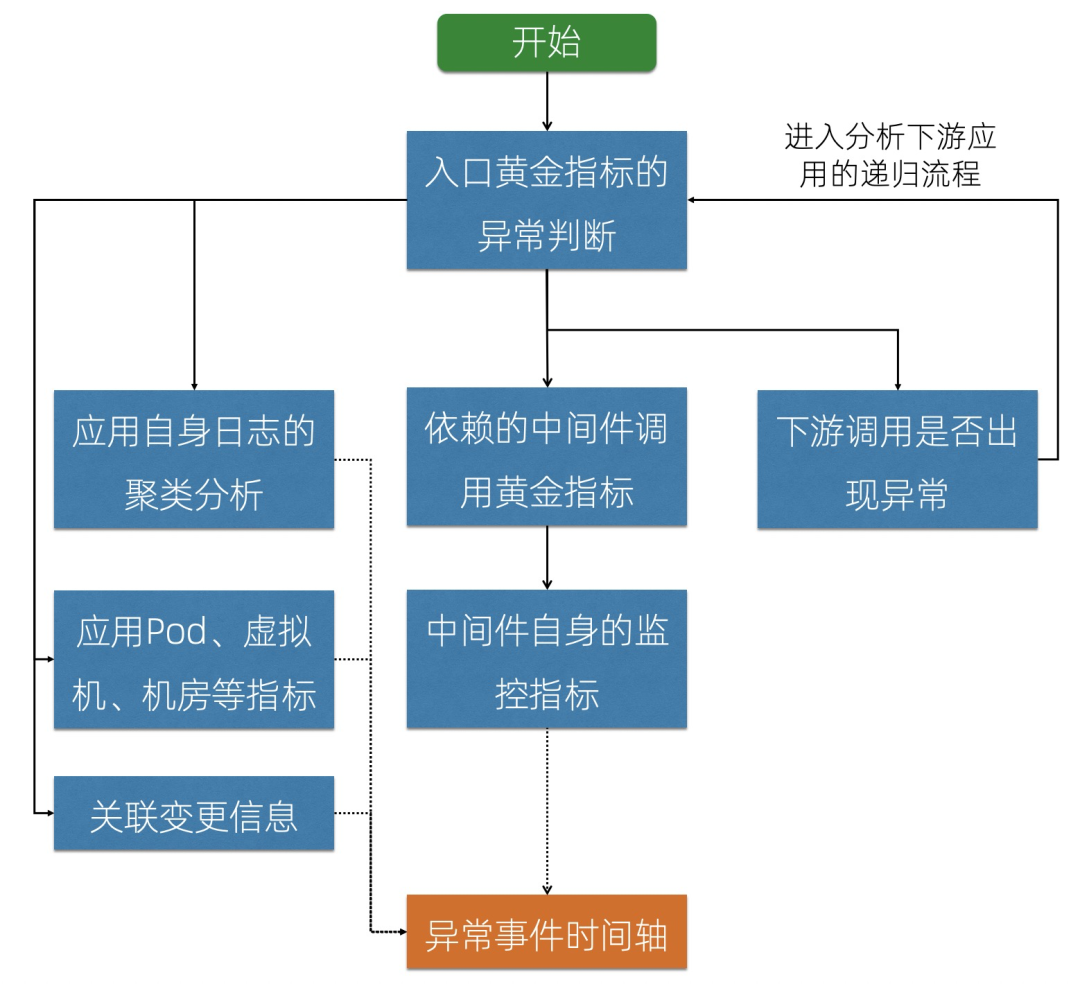
4 基于编排的根因分析
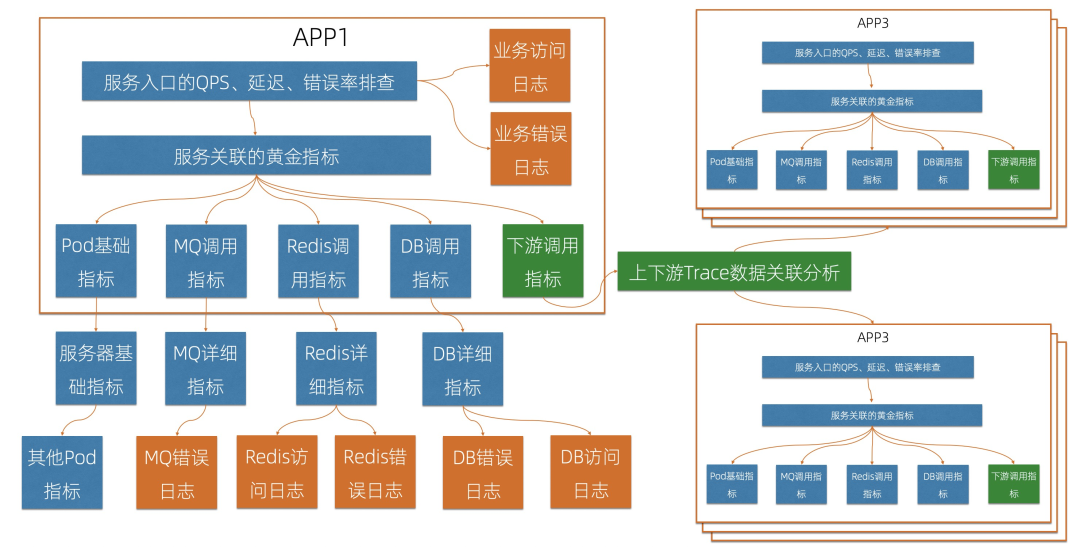
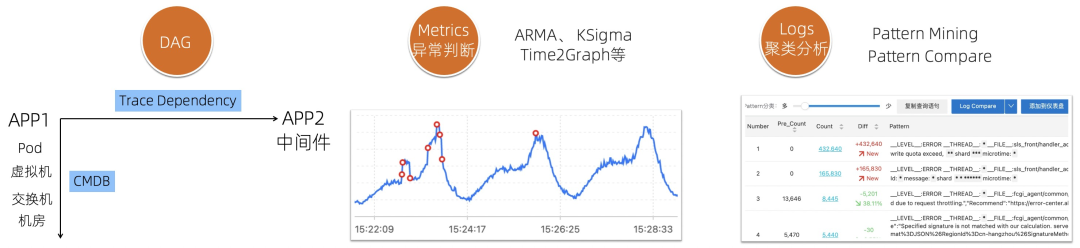
关联关系:通过Trace可以计算出APP/服务之间的依赖关系;通过CMDB信息可以得到APP和PaaS、IaaS之间的依赖关系。通过关联关系就可以“顺藤摸瓜”,找到出现问题的原因。 时序异常检测算法:自动检测某一条、某组曲线是否有异常,包括ARMA、KSigma、Time2Graph等,详细的算法可以参考:异常检测算法、流式异常检测。 日志聚类分析:将相似度高的日志聚合,提取共同的日志模式(Pattern),快速掌握日志全貌,同时利用Pattern的对比功能,对比正常/异常时间段的Pattern,快速找到日志中的异常。
十三 写在最后
让系统更加稳定,用户体验更好 观察IT支出,消除不合理的使用,节省更多的成本 观察交易行为,找到刷单/作弊,即使止损 利用AIOps等自动化手段发现问题,节省更多的人力,运维提效
《看见新力量》第二期免费下载!带你走进数十位科技创业者背后的故事
文章转载自阿里技术,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1228次阅读
2025-04-27 16:53:22
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
690次阅读
2025-04-30 15:24:06
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
580次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
496次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
472次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
466次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
356次阅读
2025-04-18 10:01:22
国产数据库图谱又上新|82篇精选内容全览达梦数据库
墨天轮编辑部
269次阅读
2025-04-23 12:04:21
MySQL 30 周年庆!MySQL 8.4 认证免费考!这次是认真的。。。
数据库运维之道
252次阅读
2025-04-28 11:01:25
给准备学习国产数据库的朋友几点建议
白鳝的洞穴
246次阅读
2025-05-07 10:06:14
