






阿里云云原生数据仓库AnalyticDB MySQL版是基于湖仓一体架构打造的实时数仓,高度兼容MySQL、支持毫秒级更新、亚秒级查询。是业界性能全球第一(TPC- DS 10TB)的云数据仓库产品。
无论是数据湖中的非结构化或半结构化数据,还是数据库中的结构化数据,企业都可使用AnalyticDB MySQL版构建数据分析平台,完成高吞吐离线处理和高性能在线分析,快速将企业的关键指标实时可视化展示,完成高吞吐离线处理和高性能在线分析的同时,实现降本增效。
AnalyticDB MySQL湖仓版可无缝替换,CDH/TDH/Databricks/Presto/Spark/Hive等。

具体福利详见文末!
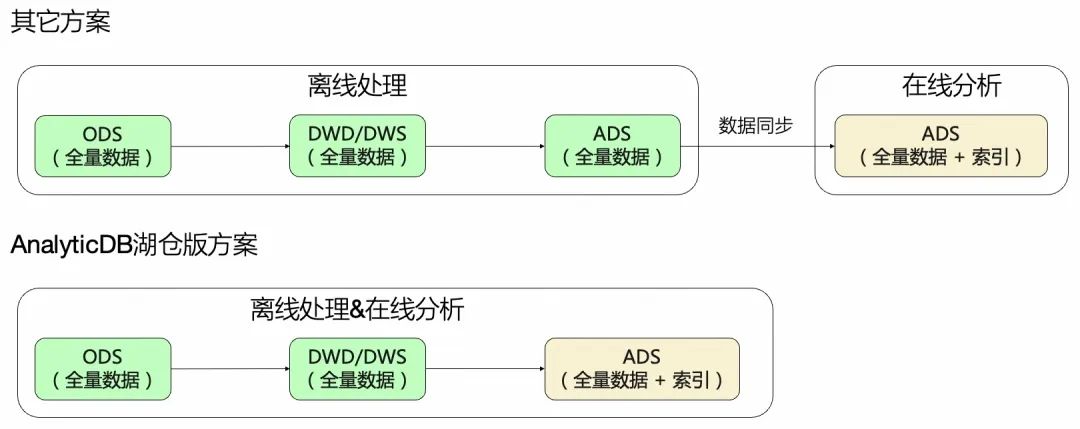
数据一旦在多个系统间进行同步,就难免会因为数据同步工具的稳定性,带来数据一致性、时效性、数据冗余等问题。比如「数据工程师」在数据湖中看到的ADS表,和「数据分析师」在数据仓库中看到的ADS表的数据可能是不一样的。

阿里云数据仓库AnalyticDB MySQL版针对目前数据仓库和数据湖割裂的体系导致体验、系统复杂度、数据一致性和成本等各方面的挑战,在AnalyticDB MySQL作为数据仓库的基础上推出了AnalyticDB MySQL湖仓版,帮助客户可以同时使用数据仓库和数据湖中的数据自由平衡性价比,并且保持全过程同一体验和数据一致性。
阿里云数据仓库AnalyticDB版湖仓版在数仓版的能力基础上,从数据的采集、存储、计算和应用等方面做了全面的升级。湖仓版是基于计算存储分离架构打造的,同时具备低成本离线处理和高性能在线分析能力的湖仓一体版本,提供将源端数据实时同步到湖(Hudi on OSS)或仓(C-Store)的可视化配置能力。通过底层存储的一份全量数据,来支持离线和在线两种场景,避免因数据同步产生的数据一致性和时效性等问题。计算层支持标准接口的多语言可编程计算引擎Spark。同时湖仓版提供离线业务与在线业务的计算资源物理隔离的能力,能实现计算资源和存储资源按需弹性扩容。
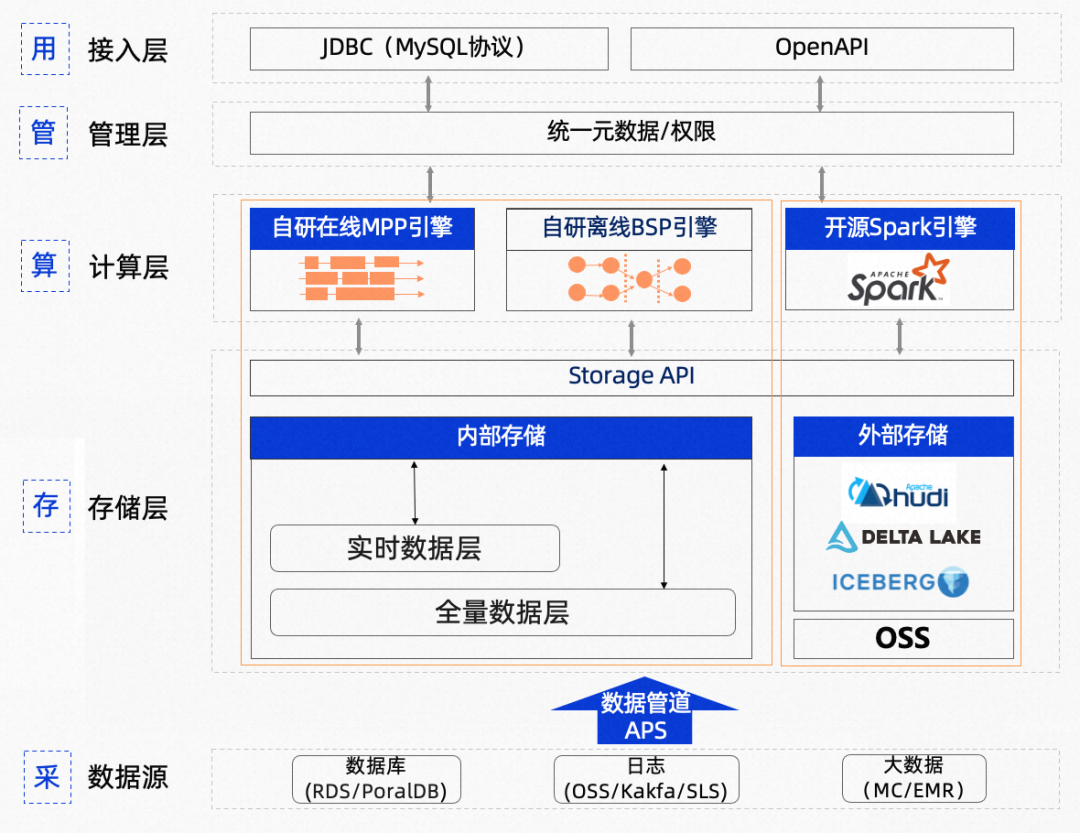
存储层:只需一份全量数据,满足离线在线场景
离线场景和在线场景对数据存储的诉求不一致,如何让一份全量数据同时实现高性能在线分析和低成本离线处理,是一大挑战。在线分析场景希望数据尽量在高性能存储介质上提高性能,离线处理希望数据尽量在低成本存储介质上降低存储成本。
为此,湖仓版首先将一份全量数据存在低成本高吞吐存储介质上,低成本离线处理场景直接读写低成本存储介质,降低数据存储和数据IO成本,保证高吞吐;其次将实时数据存在单独的存储IO节点(EIU)上,保证「行级」的数据实时性,同时对全量数据构建索引,并通过Cache能力对数据进行加速,满足百ms级高性能在线分析场景。
湖仓版的「一份数据」方案,很好地解决了因为数据同步带来的数据一致性和数据时效性问题。
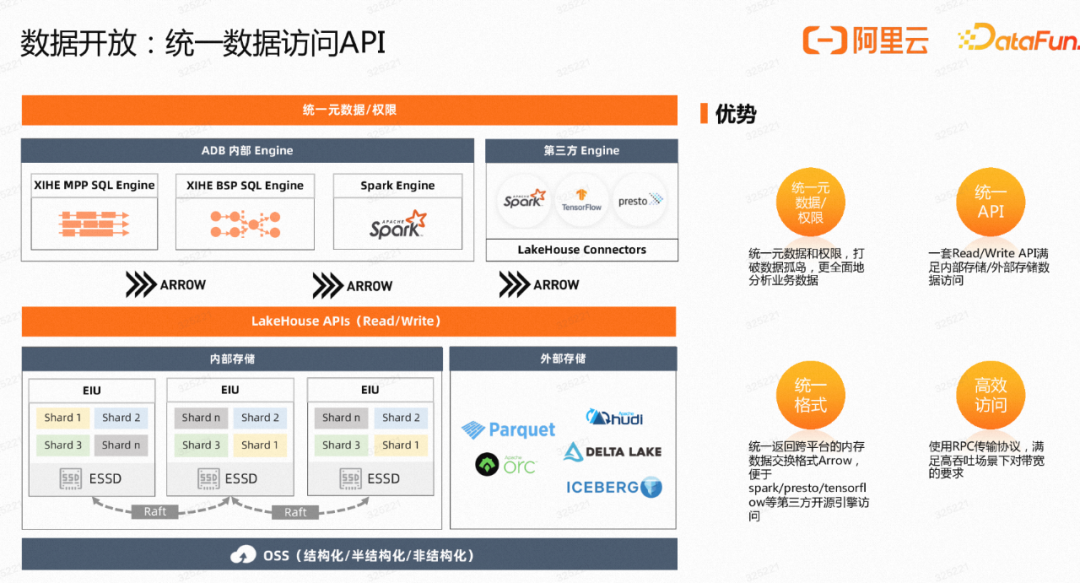
计算层:融合计算引擎
极致弹性:千核秒级弹性能力,完美贴合业务负载
● 平滑迁移:采用开源Spark内核,接口和功能100%兼容;
● 性能:通过数据缓存、向量化执行、下推优化等,相比开源同版本,10TB TPC-H测试场景下性能提升2.7倍;
● 成本:提交Spark Job才会触发资源的申请,满足业务波峰波谷对资源弹性的需求,降低资源成本;
● 高效入仓:使用Storage API替代传统JDBC方式,入仓速度提升5倍;
阿里云数据库仓库AnalyticDB MySQL湖仓版的优势可以用程序员最熟悉的数字「1024」进行总结。
1: 是指一份数据,避免数据同步带来的数据一致性、时效性、冗余等问题;
0: 是指灵活弹性,用Serverless的方式贴合业务负载,保证查询性能,降低资源成本;
2: 是指湖仓版同时满足低成本离线处理和高性能在线分析;
4: 是指4个统一,统一计费单位、统一数据管道、统一数据管理、统一数据访问。
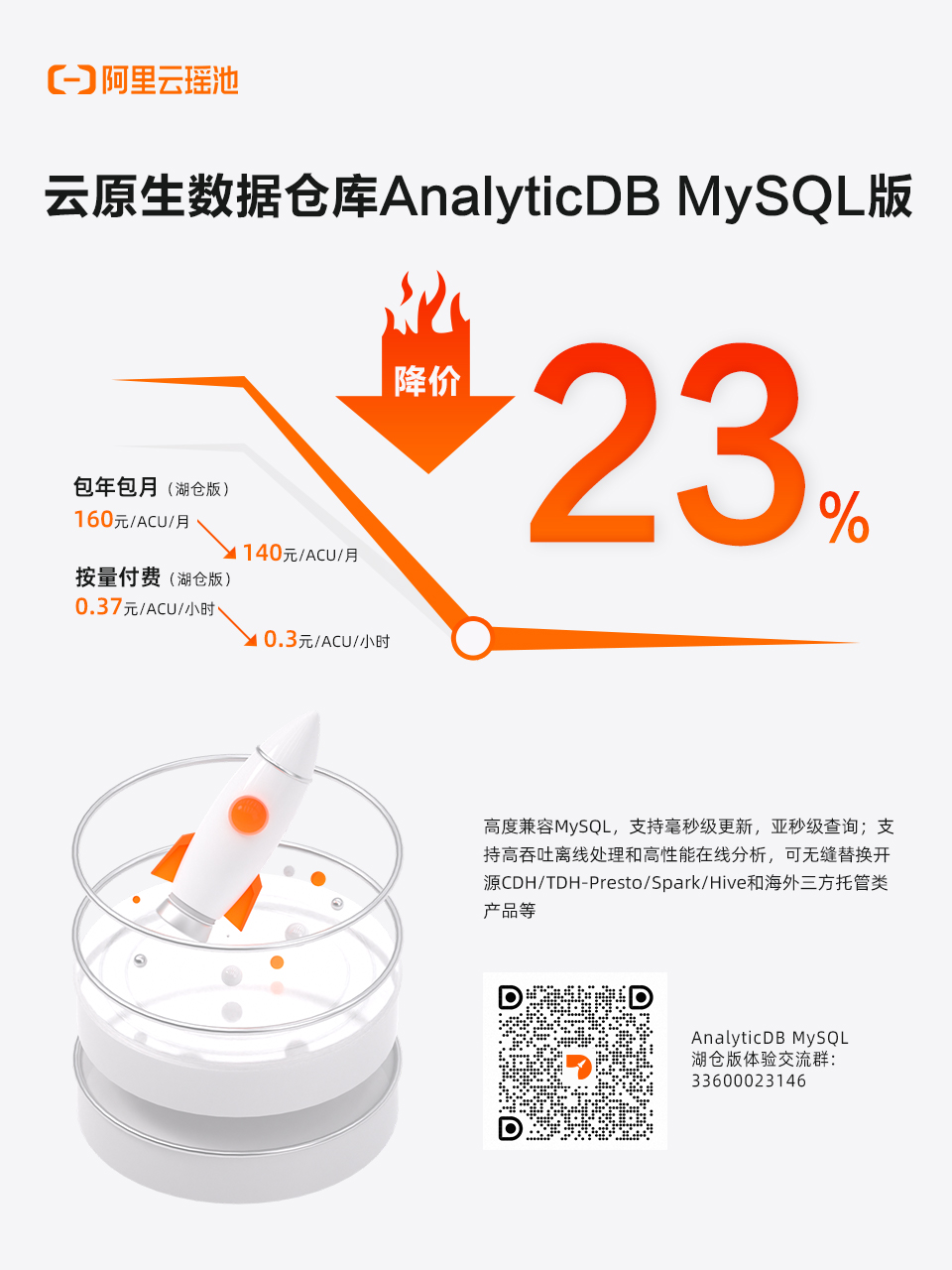
近期大降价福利
了解更多



 点击 阅读原文 即可查看 湖仓版3.0定价文档
点击 阅读原文 即可查看 湖仓版3.0定价文档
