




向量相似度查询
在 AI 领域人脸识别、物体识别、语音识别、知识图谱等,都是通过深度学习算法提取特征向量,特征向量的维度非常高,查询的时候通过比较查询向量和目标向量的余弦相似度取相似度最大的 N 条记录返回结果。过程如图 7-16 所示。
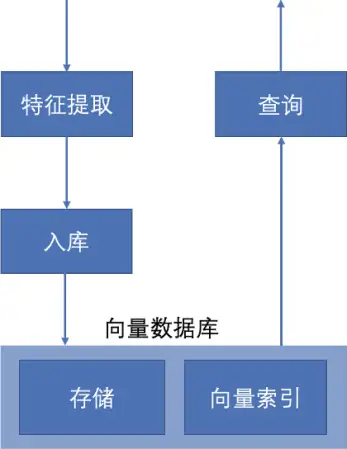
由于特征向量维度非常高(512 维浮点型, 甚至更高),而且数据库内保存的数据量非常多, 通过暴力方式比较余弦相似度显然性能极其低下, 业界常用的做法是通过硬件加速,比如 FPGA 加速,把浮点型数据转成 int8,然后把数据预加载到 FPGA 内存中,查询时通过 FPGA 高并发的能力快速计算余弦相似度。
硬件加速方法有两个缺点:
1. 成本高,需要 FPGA 和大容量内存;
2. 处理不了海量数据,毕竟内存容量有限,无法预加载海量数据。
在 AntDB 中,采用向量索引实现快速相似度查询。向量索引是 AntDB 团队自研的针对高维向量相似度查询而设计的索引结构,查询时间复杂度为K×LogN,其中 K 是常量 15,假设数据库中有 10 亿特征向量,索引相似度查询只需进行 450 次计算,相比暴力计算的 10 亿次,性能提升数个量级。由于索引是保存在磁盘上的,可以存储海量数据。而且该方案不需要 FPGA 和大容量内存,成本很低。
关于AntDB数据库
AntDB 数据库始于 2008 年,在运营商的核心系统上,为全国 24 个省份的 10 亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近 15 年,并在通信、金融、交通、能源、物联网等行业成功商用落地。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
