




最近邻算法
算法原理
最近邻方法的原理是找到预定义数量的训练样本,这些样本与新点的距离最近,并从中预测标签。样本的数量可以是用户定义的常数(k-最近邻学习),也可以根据点的局部密度变化(基于半径的邻居学习)。
sklearn.neighbors
sklearn.neighbors
是 scikit-learn 库中提供的一个模块,用于实现基于邻居的学习方法,包括无监督和监督学习。无监督的最近邻方法是许多其他学习方法的基础,特别是流形学习和谱聚类。
距离可以是任何度量标准:标准欧氏距离是最常见的选择。邻居方法被称为非泛化的机器学习方法,因为它们只是简单地“记住”所有的训练数据。
近邻算法对比
蛮力算法
快速计算最近邻是机器学习中的一个活跃研究领域。最朴素的最近邻搜索实现涉及计算数据集中所有点对之间的距离:对于 N
个样本在 D
维度中,这种方法的复杂度为 O[D * N^2]
。
对于小数据样本,高效的蛮力最近邻搜索可能非常有竞争力。然而,随着样本数量 N
的增加,蛮力方法迅速变得不可行。可以通过关键字 algorithm = 'brute'
指定蛮力最近邻搜索,并使用 sklearn.metrics.pairwise
中可用的例程进行计算。
K-D 树
为了解决蛮力方法的计算效率问题,发明了各种基于树的数据结构。总体上,这些结构试图通过高效地编码样本的聚合距离信息来减少所需的距离计算次数。基本思想是,如果点 A
与点 B
距离很远,点 B
与点 C
距离很近,那么我们知道点 A
与点 C
距离很远,而无需明确计算它们的距离。通过这种方式,最近邻搜索的计算成本可以降低到 O[D N \log(N)]
或更好。这相对于大 N
来说是一个显著的改进。
KD 树是一个二叉树结构,它沿着数据轴递归地划分参数空间,将其划分为嵌套的正交区域,其中数据点被分配。构建 KD 树非常快:因为仅沿着数据轴进行划分,无需计算 D
维度的距离。
Ball 树
为了解决 KD 树在高维度中的低效性,发展了 ball 树数据结构。Ball 树与 KD 树不同,KD 树沿笛卡尔坐标轴划分数据,而 ball 树则通过一系列嵌套的超球体进行划分。这使得 ball 树的构建成本比 KD 树更高,但结果是一种在高度结构化数据上非常高效的数据结构,即使在非常高的维度中也是如此。
Ball 树递归地将数据划分为由质心 C
和半径 r
定义的节点,以便节点中的每个点都位于由 r
和 C
定义的超球体内。通过使用 三角不等式,减少了对候通过这种设置,测试点与质心之间的单一距离计算足以确定到节点内所有点的距离的下界和上界。由于 ball 树节点的球形几何结构,它在高维度中可能优于 KD-tree,尽管实际性能高度依赖于训练数据的结构。
最近邻算法的选择
对于给定数据集的最佳算法是一个复杂的选择,取决于许多因素:
样本数 N
(即n_samples
)和维数D
(即n_features
)。蛮力 查询时间随 O[D N]Ball 树 查询时间随 O[D log(N)]KD 树 查询时间随 D
变化,难以精确刻画。对于小D
(小于20左右)的情况,成本约为O[D log(N)]
,KD 树查询可能非常高效。对于较大D
,成本增加到接近O[DN]
,并且由于树结构的开销,查询可能比蛮力更慢。查询点请求的邻居数 k
。蛮力 查询时间在很大程度上不受 k
值的影响。Ball 树 和 KD 树 查询时间会随着 k
的增加而变慢。
案例1:Unsupervised Nearest Neighbors
NearestNeighbors
实现了无监督的最近邻学习,充当了三种不同最近邻算法(BallTree
、KDTree
和基于sklearn.metrics.pairwise
中的例程的蛮力算法)的统一接口。
通过关键字algorithm
控制邻居搜索算法的选择,它必须是['auto', 'ball_tree', 'kd_tree', 'brute']
中的一个。当传递默认值 'auto' 时,算法会尝试从训练数据中确定最佳方法。
>>> from sklearn.neighbors import NearestNeighbors
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> nbrs = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(X)
>>> distances, indices = nbrs.kneighbors(X)
>>> indices
array([[0, 1],
[1, 0],
[2, 1],
[3, 4],
[4, 3],
[5, 4]]...)
>>> distances
array([[0. , 1. ],
[0. , 1. ],
[0. , 1.41421356],
[0. , 1. ],
[0. , 1. ],
[0. , 1.41421356]])
由于查询集与训练集匹配,每个点的最近邻都是其本身,距离为零。此外,还可以高效地生成一个显示相邻点之间连接的稀疏图:
>>> nbrs.kneighbors_graph(X).toarray()
array([[1., 1., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[0., 1., 1., 0., 0., 0.],
[0., 0., 0., 1., 1., 0.],
[0., 0., 0., 1., 1., 0.],
[0., 0., 0., 0., 1., 1.]])
案例2:Nearest Neighbors Classification
scikit-learn 实现了两种不同的最近邻分类器:KNeighborsClassifier
基于每个查询点的最近邻实现学习,其中是由用户指定的整数值。RadiusNeighborsClassifier
基于每个训练点周围固定半径内的邻居数量来实现学习,其中是由用户指定的浮点值。
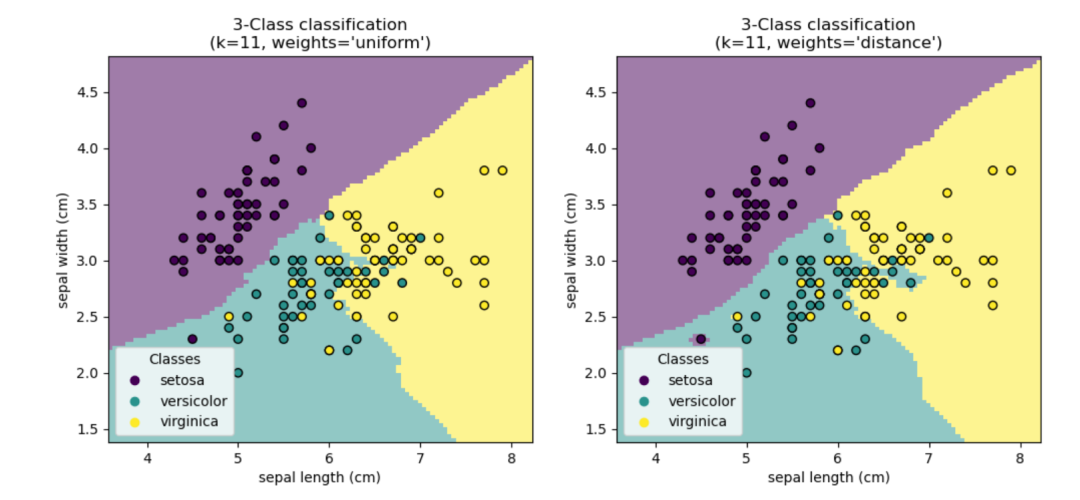
在数据不均匀采样的情况下,RadiusNeighborsClassifier
中的基于半径的邻居分类可能是一个更好的选择。 用户指定一个固定的半径,以便在更稀疏的邻域中的点使用更少的最近邻进行分类。对于高维参数空间,由于所谓的“维度灾难”,这种方法变得不太有效。
>>> X = [[0], [3], [1]]
>>> from sklearn.neighbors import NearestNeighbors
>>> neigh = NearestNeighbors(n_neighbors=2)
>>> neigh.fit(X)
NearestNeighbors(n_neighbors=2)
>>> A = neigh.kneighbors_graph(X)
>>> A.toarray()
array([[1., 0., 1.],
[0., 1., 1.],
[1., 0., 1.]])
案例3:Nearest Neighbors Regression
scikit-learn 实现了两种不同的邻居回归器:KNeighborsRegressor
基于每个查询点的最近邻实现学习,其中是由用户指定的整数值。RadiusNeighborsRegressor
基于查询点周围固定半径内的邻居实现学习,其中是由用户指定的浮点值。
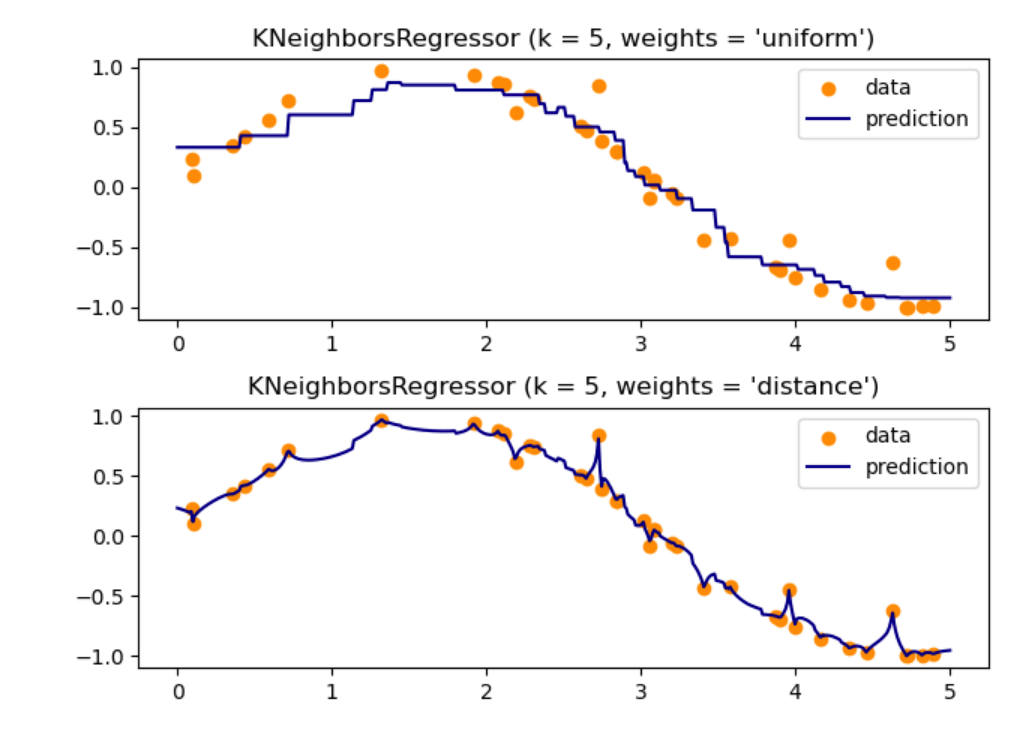
>>> X = [[0], [1], [2], [3]]
>>> y = [0, 0, 1, 1]
>>> from sklearn.neighbors import KNeighborsRegressor
>>> neigh = KNeighborsRegressor(n_neighbors=2)
>>> neigh.fit(X, y)
KNeighborsRegressor(...)
>>> print(neigh.predict([[1.5]]))
[0.5]
案例4:Nearest Centroid Classifier
最近质心分类器(NearestCentroid
)是一种简单的算法,通过其成员的质心来表示每个类别。实际上,这使其类似于KMeans
算法的标签更新阶段。它也没有需要选择的参数,因此是一个很好的基线分类器。然而,在非凸类别或类别具有明显不同方差的情况下,它可能表现不佳,因为它假设所有维度上的方差相等。
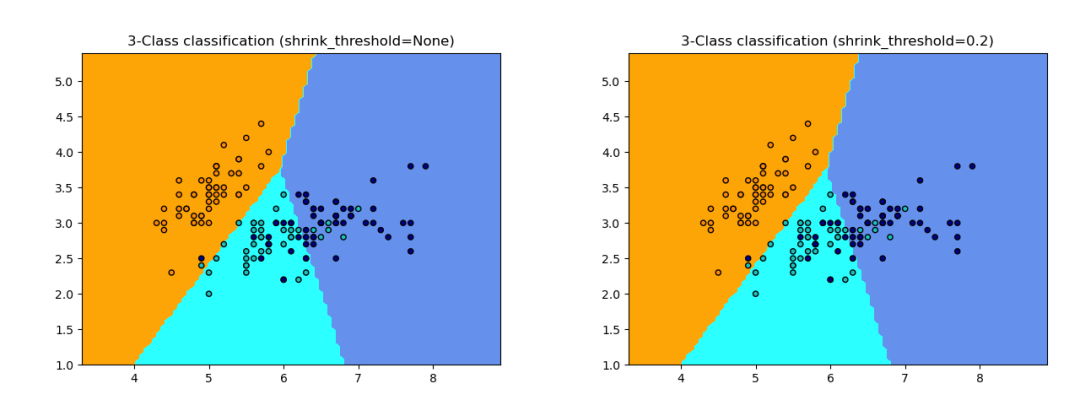
>>> from sklearn.neighbors import NearestCentroid
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> y = np.array([1, 1, 1, 2, 2, 2])
>>> clf = NearestCentroid()
>>> clf.fit(X, y)
NearestCentroid()
>>> print(clf.predict([[-0.8, -1]]))
[1]
案例5:Nearest Neighbors Transformer
许多 scikit-learn 的估计器依赖于最近邻方法,包括一些分类器和回归器,如KNeighborsClassifier
和KNeighborsRegressor
,以及一些聚类方法,如DBSCAN
和SpectralClustering
,以及一些流形嵌入方法,如TSNE
和Isomap
。
首先,预先计算的图可以多次重复使用,例如在调整估计器的参数时。这可以由用户手动完成,也可以利用 scikit-learn 流水线的缓存特性:
>>> import tempfile
>>> from sklearn.manifold import Isomap
>>> from sklearn.neighbors import KNeighborsTransformer
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.datasets import make_regression
>>> cache_path = tempfile.gettempdir() # we use a temporary folder here
>>> X, _ = make_regression(n_samples=50, n_features=25, random_state=0)
>>> estimator = make_pipeline(
... KNeighborsTransformer(mode='distance'),
... Isomap(n_components=3, metric='precomputed'),
... memory=cache_path)
>>> X_embedded = estimator.fit_transform(X)
>>> X_embedded.shape
(50, 3)
案例6:Neighborhood Components Analysis
邻域分量分析(NCA,Neighborhood Components Analysis
)是一种距离度量学习算法,旨在提高相对于标准欧几里德距离的最近邻分类的准确性。该算法直接最大化训练集上留一法 k-最近邻(KNN)得分的随机变体。它还可以学习数据的低维线性投影,用于数据可视化和快速分类。
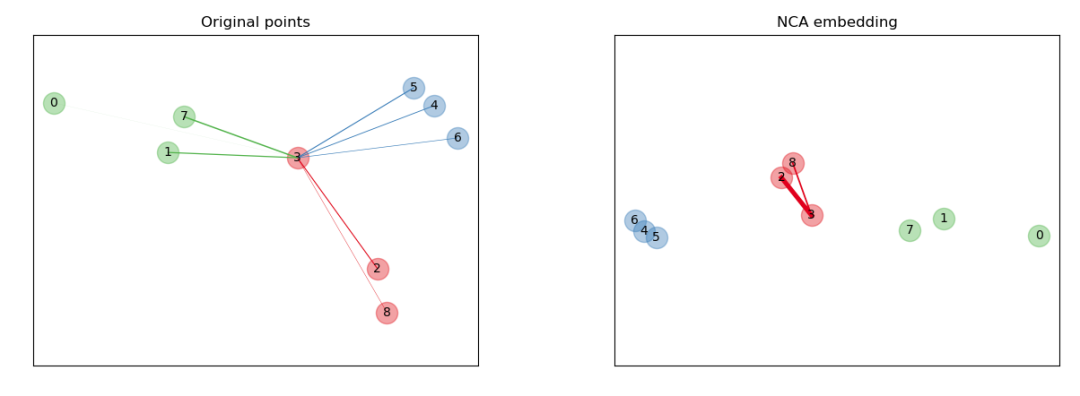
>>> from sklearn.neighbors import (NeighborhoodComponentsAnalysis,
... KNeighborsClassifier)
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import Pipeline
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... stratify=y, test_size=0.7, random_state=42)
>>> nca = NeighborhoodComponentsAnalysis(random_state=42)
>>> knn = KNeighborsClassifier(n_neighbors=3)
>>> nca_pipe = Pipeline([('nca', nca), ('knn', knn)])
>>> nca_pipe.fit(X_train, y_train)
Pipeline(...)
>>> print(nca_pipe.score(X_test, y_test))
0.96190476...
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

