




He3DB 是由移动云数据库团队研发的一款计算/存储分离的云原生数据库,He3DB通过计算/存储分离、数据冷热分层和压缩、智能中间件等技术,来保证高性能和低成本完美兼得,在获得高性能的同时,最大化的帮助客户节省数据库使用成本。
He3DB 在研发之初团队研读了大量云原生数据库相关论文,包括Aurora、PolarDB、Socrate、Taurus等发布的相关论文,通过论文我们能学习到各厂家关于云原生数据库的理解、实践时所要解决的问题、以及其产品设计的核心理念,这对He3DB 产品的设计、工程实践等启到有效的指导作用。因此为帮助更多人了解、学习云原生数据库的知识,团队推出本专栏,将分期解析云原生数据库领域的经典论文。
本期分享论文为:Taurus Database: How to be Fast, Available, and Frugal in the Cloud
1. Introduction
Taurus是华为对标AWS Aurora的一款云原生数据库。其采用的是计算存储分离的架构,设计思想也是“the log is the database”的这样一种理念,只需要将WAL日志写入到存储层,由存储层负责重放日志、回写page并尽量减少写放大,来最小化网络IO。Taurus建立在以前工作的基础上,并在几个方面进行了改进。Taurus有类似于Aurora的计算存储分离,并且像Socrates一样分开可用性和持久性的概念。此外,本文提出Taurus引入了多项创新,帮助其以极低成本实现高可用性和高性能。
(1)第一个贡献是一种复制和恢复算法,该算法可实现高可用性,且复制因子不高于持久性所需的复制因子,并且不会牺牲性能或强大的一致性保证。(2)第二个贡献是一系列新颖的架构选择,使Taurus能够获得更高的性能。测试表名,与使用本地存储的MySQL 8.0相比,Taurus可以实现高达200%的吞吐量提高,并且主备延迟可以保持在20ms以内。(3)第三个贡献是对存储层内部工作,性能优化和设计取舍的详细描述。
2. 架构
Taurus包含4个主要的模块:
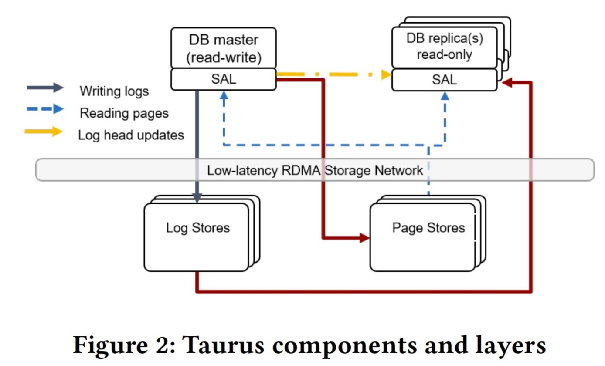
- 数据库前端
数据库前端是基于MySQL的修改版,包含一个提供读写服务的Master实例,以及若干个提供只读服务的RO实例。Master实例提交事务时会产生redo log,这些log内容描述了事务对page所做的修改。Master会将log发送给Log Store,另外,Master也会将log分发给Page Stores。其中,写log、读取page的逻辑都封装在了SAL中,为计算层屏蔽了存储层的复杂性。 - SAL
SAL(Storage Abstraction Layer)是一个嵌入到计算层的library,将远程存储、数据分片、故障恢复、主从复制的复杂性从计算层隔离开来。主要功能包括:负责计算引擎与存储的LogStore/PageStore交互;负责创建、管理、删除PageStore的Slices;管理page在Slices上的映射关系。 - Log Store
Log Store负责持久化log,一旦事务的所有log持久化之后,那么计算层即可通知客户端事务已经提交完成。另外,Log Store负责为RO实例提供log内容,RO实例需要重做log来更新自己buffer pool中的page。Master实例会周期性地通知RO实例最新log的位置,以便RO实例可以读取到最新的log。 - Page Store
Page Store的主要功能是响应Master实例和RO实例的读page请求,Page Store具有构造计算层所需要的任意版本的page的能力。
Log Store
Log Store的主要功能是保存由Master实例生成的日志记录,并提供从任何副本对其的读取访问权限。Log Store提供了一个关键的抽象对象,PLog。每个PLog都是大小有限的、append-only的存储对象,并同步复制到不同的Log Store上。
Log Store节点以集群的方式部署,一个典型的云化部署有上百个Log Store节点。当需要创建PLog时,集群管控平台会选择3个Log Store节点来负责PLog的3个副本。
Taurus采用的是采用N=3,W=3,R=1的复制策略,当SAL需要将一批log写入到PLog时,只有全部3个PLog副本都写入成功后,才认为写入成功。如果其中一个Log Store无法响应,那么对该PLog的写入操作就认为是失败的,并且不会再有写入请求发送给该PLog,取而代之的是由另外3个Log Store组成的新PLog。从Log Store读取log时,只需要PLog有一个replica存活就能读取成功,通常有两种场景会读取log:RO实例读取由Master实例产生的log,为了加速读log的效率,Log Store用FIFO cache缓存最新的log,可以再大部分情况下避免磁盘读;在数据库恢复的过程中也会读取log。
Page Store
Page Store的主要功能就是处理来自Master实例和RO实例的page读取请求,Page Store节点必须能够构建计算层可能请求的page的任何版本。当Master实例修改page时,它将为该page分配一个版本(LSN),每个page版本均由其pageid和LSN标识。Page Store暴露4个主要的API来与SAL进行交互:
- WriteLogs:接受log记录的写请求
- ReadPage:读取特定版本的page
- SetRecycleLSN:设置recycle LSN,在这个LSN之前的版本不会再被计算层请求
- GetPersistentLSN:获取Page Store可以提供的最大LSN
Page Store在实现上有三个特性:
- 每个Page Store节点单独进行日志合并
- log持久化是append-only操作,提升写入速度并减少存储设备的损耗
- log合并的过程中所需的数据(即基础页和日志记录)都缓存在内存中,保证在整个合并过程涉及到page的更新不会产生读IO
下图是Page Store的主要组件的工作流程:
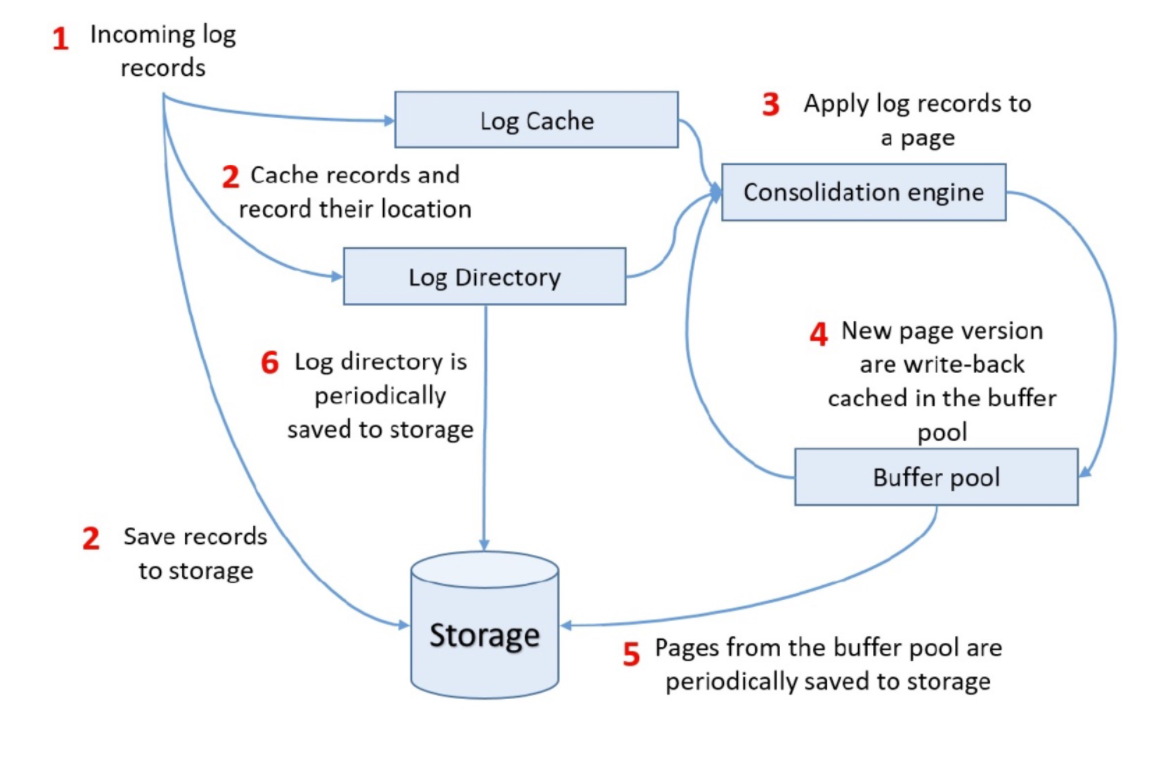
SAL
SAL负责将log写入到Log Store和Page Store中,并从Page Store读取page。只要Master决定持久化log,log就会发送到SAL。SAL维护着cluster visible(CV) LSN,这个LSN代表数据库的全局一致性点。只有同时满足以下两个条件时,SAL才会推进CV-LSN:
- 数据库的log buffer已经成功写入到Log Store
- 对于包含与组刷新的log,所有包含此log的每个slice均已成功写入至少一个Page Store中
数据库前端
目前,Taurus使用MySQL 8.0的修改版本作为数据库前端。修改包括将日志写入和页面读取转发到SAL层,以及禁用主节点的缓冲池刷新和重做恢复。只读副本的修改包括使用SAL从日志存储读取的记录来更新缓冲池中的页面,以及为事务分配读取视图的机制。
Read replicas
Read replicas可提供快速的故障转移和为读负载提供横向扩展功能。下图显示了Read replicas的工作流:
- Master实例更新数据库时,产生了log,并将log写入到Log Store和Page Stores中
- Read replicas从Master实例中获取最新的log位置和LSN
- Read replicas从Log Store读取log,来更新其buffer pool中的page
- Read replicas还根据需要从Page Store中读取page
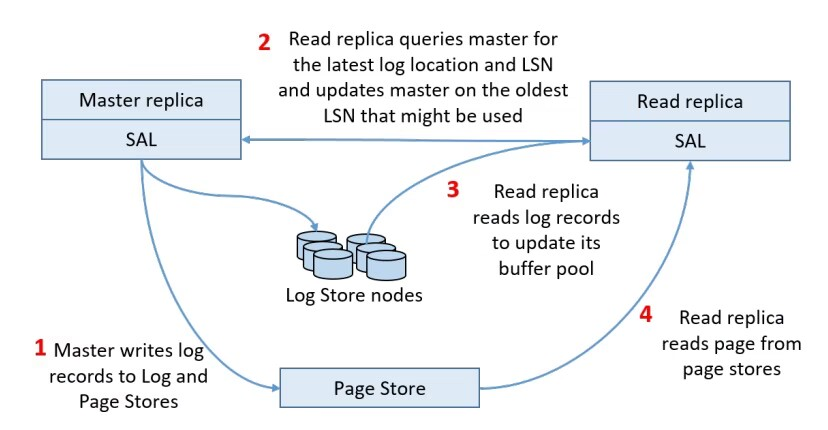
以前传统的主备复制,是将所有日志记录直接从主库流复制到每个只读节点,但是这种方式会导致网络IO成为瓶颈。为了解决这个问题,He3DB采用的方式与Taurus类似,主备之间只是同步log的元信息,而不是同步完整的日志记录。
数据是共享的,并且可以由Master实例修改,而无需与只读副本同步。因此,一个重要的挑战是只读副本如何保持数据的一致视图。Taurus的方案是将日志记录成组写入,始终将组边界设置在一个一致性点,只读副本按这些组边界自动读取和应用日志记录。只读副本处理的最后一条log的LSN表示该实例的数据库物理视图,称为replica visibleLSN。
只读副本从Log Store中读取并解析log,识别日志记录组边界,并不断推进replica visible LSN。当读取的事务需要访问page时,通过记录当前的replica visible LSN(称为transaction visible LSN(TV-LSN)),来创建其自己的数据库物理视图。不同事务可以有不同的TV-LSN,读副本跟踪最小的TV-LSN并将其发送给Master实例。Master实例收集这些TV-LSN,选择最小值,并将其作为一个新的recycle LSN(用于垃圾回收)发送给Page Stores。Page Stores必须确保它们能够提供在recycle LSN之后创建的任何页面版本。当读事务完成一个需要物理一致性的操作(例如,索引查找)时,它会释放TV-LSN。因为这样的操作通常很短,所以读副本可以非常快地推进他们的recycle LSN,允许Page Store清除旧版本,从而减少占用的存储空间。
3. Replication
数据持久性和服务可用性是数据库服务的关键特征。在实践中,通常认为拥有三个数据副本足以保证持久性。但是,三份副本可能不足以达到所需的可用性级别。维护三个一致的副本意味着所有副本都必须在线才能使系统可用。为了解决这种可用性问题,Taurus使用一种对日志和数据具有不同复制策略的方法。
Write path
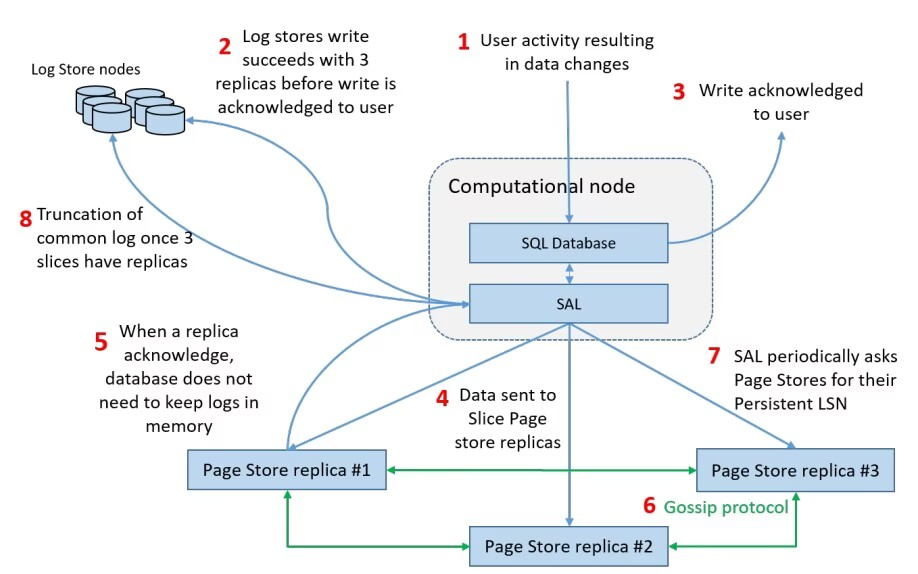
上图是关于写路径的描述,其中:
- 步骤2需要Log Store将log的三副本都持久化后才认为写入成功,而步骤5中SAL只要有一个Slice replica确认,就可以释放缓冲区并重用。
- 步骤3只要log写入到Log Store中,事务即可认为已提交。
- 步骤6中Page Store replica通过gossip协议定期相互交换消息,以检测和恢复丢失的缓冲区。
Read path
这部分主要介绍了Taurus修改了buffer pool的淘汰算法,在最新的日志持久化到Page Store之前,要保证相应的页面在缓冲池中可用。只有log持久化到Page Store上,Page Store才能构造计算层需要的任意版本的page。
与Quorum复制的比较
这部分主要介绍了Taurus与Quorum复制,并对两者存储不可用的概率进行了比较:
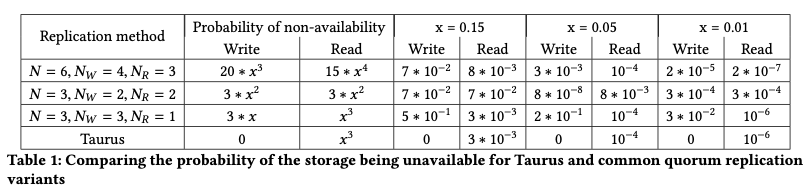
如果出现不相关的故障,Taurus总是可以进行写操作。对于读操作,Taurus提供与Quorum复制相同或更好的可用性,除非x=0.01,并且Quorum的节点数为6。但是这种情况下,相较于Taurus算法,Quorum必须使用两倍的副本数。
4. Recovery
Taurus认为恢复的重要设计目标是最大程度地使用户看不到故障和后续恢复,因此在Taurus的设计中,Log Store和Page Store的故障对于应用程序是不可见的,他们只会意识到前端故障。
Log Stores和Page Stores的节点可用性由一个Recovery服务监控,如果检测到某个Store节点故障,那么这个故障首先会被认为是短暂故障,并且还会持续监控该Store节点。如果该节点长时间都不可用(15min),那么会被认为是长期故障。Taurus认为15min这个阈值已经足够小,因为15min内虽然数据只有2个副本,但是也不会破坏数据的持久性保证。
4.1 Log Store节点的恢复
-
短期故障
Log Store节点的所有PLogs停止接受新的写入,变成只读。因此,短期故障后无需恢复。
-
长期故障
将故障节点从集群中移除,并在剩余的集群节点上,根据可用副本重新创建出故障节点的PLog副本。
4.2 PageStore节点的恢复
由于Page Store节点的恢复更为复杂,因此论文详细介绍了在面对不同情况下Page Store节点时如何恢复的:
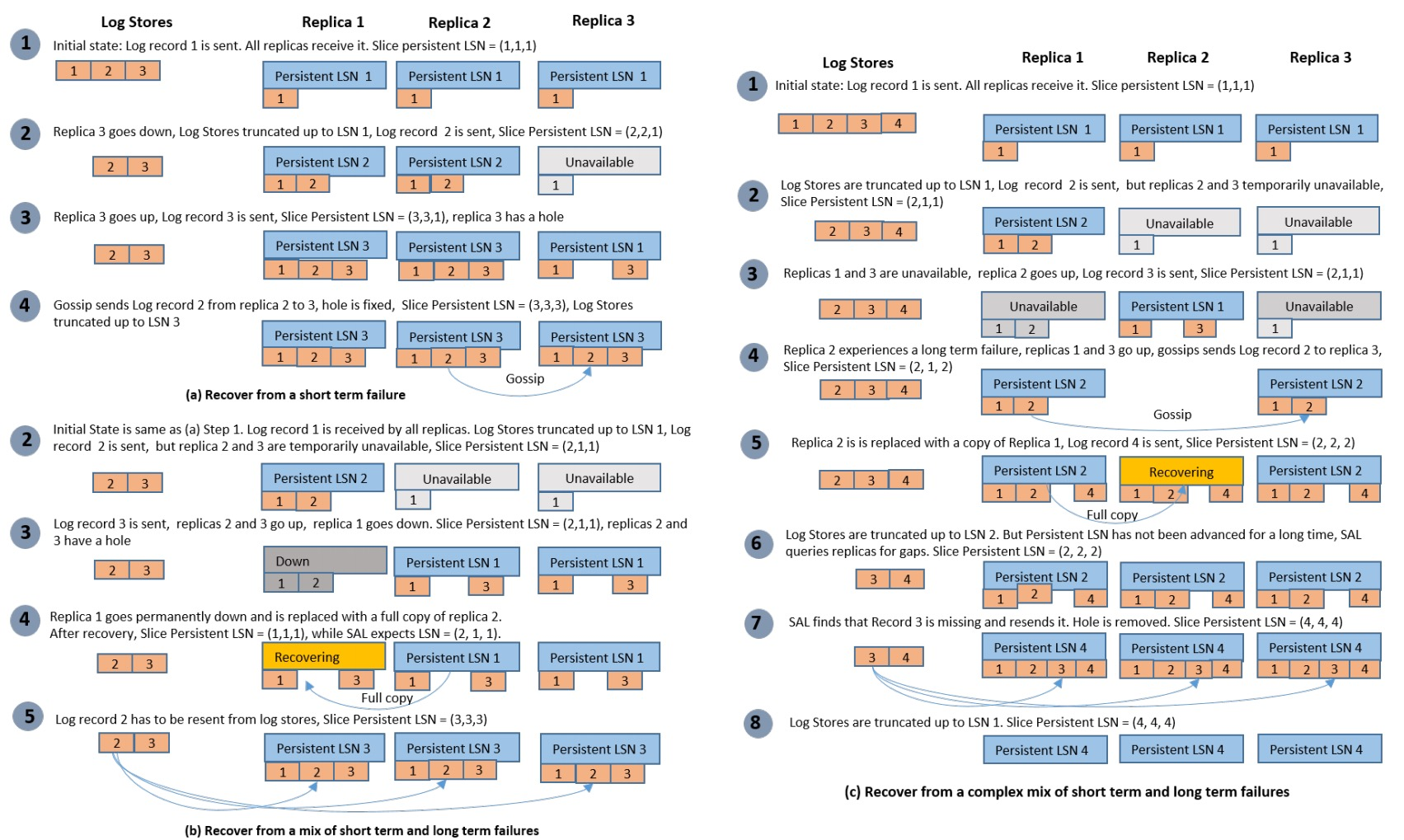
当Page Store节点在短期失败后恢复时,它将与其他Page Store节点通过Gossip协议去同步其缺失的log。当检测到长期故障时,集群管理器将从集群中移除故障节点,然后再其余Page Store节点中重新分配已存储在故障节点上的slice副本,正在恢复的切片副本最初是空的,它可以立即开始接受WriteLogs的请求但是由于它没有必需的较旧的log,因此它无法处理读取请求,接着正在恢复的slice将请求所有页面的最新版本,一旦收到所有页面,slice副本就可以同时提供读取和写入服务。除了这两种比较常见的情况,论文中还提到了另外两种更复杂的情形,并对这两种情况,提出了解决方案,见上图中的(b)和(c)。
4.3 SAL和数据库前端的恢复
因为SAL是一个库,所以SAL和数据库前端都会在数据库进程重新启动时一起恢复,在恢复时,先恢复SAL,再恢复数据库前端。
-
恢复SAL
恢复SAL主要包括两个步骤:
-
找到上次最后使用的PLog的有效的结束LSN
因为该PLog的末尾可能包含大量未达成3副本的log,SAL恢复的时候,要找到PLog的3副本中最小的结束LSN,并且清空多余的log,或者将该PLog设为read-only,并新建一个PLog用于后续的log写入
-
从db persistent LSN开始从Log Store读取log,并把slice缺失的log发送给Page Store
确保db的slices都含有计算层崩溃之前已经写入到Page Store的所有log
-
-
恢复数据库前端
SAL恢复完成后,数据库就可以接收新请求。与此同时,数据库前端通过回滚崩溃时未提交的事务所做的更改来执行撤销阶段。在接受新事务之前,必须完成重做恢复,因为重做可确保Page Store可以读取最新版本的页面。
5. 总结
以上就是我对TaurusDB论文核心内容的介绍,主要介绍了Taurus的架构、核心组件、复制过程和恢复过程。除此之外,论文中将Taurus和Aurora、Socrates分别做了对比,证明该架构有一定的性能优势,最后该论文也简单展望了下未来的工作计划。
