




背景
Apache Spark作为为大规模数据处理而设计的快速通用的计算引擎,借助Spark Sql、Spark Streaming等模块能力,提供给租户快捷方便地处理大规模数据的能力,在生产环境中得到了广泛的应用。但即便如此,由于租户需要处理的业务众多,数据量庞大,集群环境复杂等情况,spark任务在处理数据时依然会遇到各种各样的性能问题。所以作为一线的运维和技术支撑人员,需要掌握一些常规的spark作业原理以及性能调优方式,以此解决大部分spark作业性能问题。
基本概念
首先作为一线运维和支撑人员,需要了解spark作业的基本概念,这样在后续排查作业状态信息时,无论是日志的排查,还是spark ui界面的信息都可以做到有的放矢。
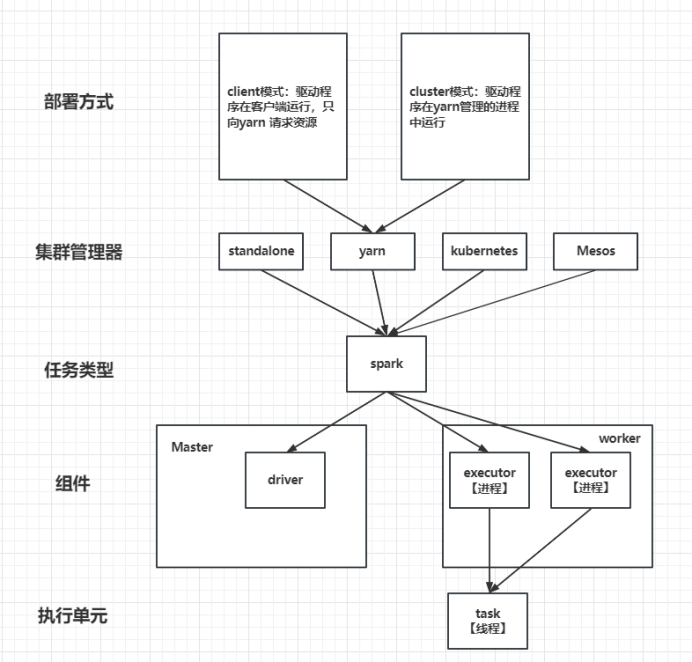
如上图所示,列出了一些spark任务类型相关的基本概念。
1、集群管理器:spark应用程序在集群中作为独立的进程运行,spark支持在standalone、yarn、kubernetes、Mesos这几种集群管理器,这些管理器在应用程序之间分配资源。
2、组件:spark是master-worker架构,master节点运行driver进程,负责管理worker节点。我们从master节点提交应用。Worker节点运行executor进程,与driver进程通信。driver进程作为程序的入口,负责向集群申请资源,负责作业的解析,调度,同时监控executor的状态,通过UI展示执行情况。executor进程,负责执行spark作业的具体任务(task),并且将执行结果返回给driver。
3、执行单元:task是spark作业的最小执行单元,executor每个核在同一时间只能处理一个task。
4、部署方式:根据spark作业提交的方式,部署方式可以分为client模式和cluster模式。以集群管理器为YARN时为例:
client模式:驱动程序【即driver进程】在客户端【即提交应用的master节点】运行,只向yarn申请资源,获得资源后executor进程分配到集群上运行。
cluster模式:驱动程序【即driver进程】在集群上的某个节点运行,后续向yarn申请资源后,executor进程分配到集群上运行。
优化1:client模式和driver模式的区别在于,client模式下driver进程运行在本地集群上,cluster模式下driver进程运行在集群的某个节点上【该节点由yarn调度,可以在yarn ui中查看】。因此,client模式会导致本地机器负载压力增大、网络流量增大,且出现故障的情况较大,而cluster模式可以避免这种情况,一般建议优先使用cluster模式提交作业,client模式可用于测试。
作业原理
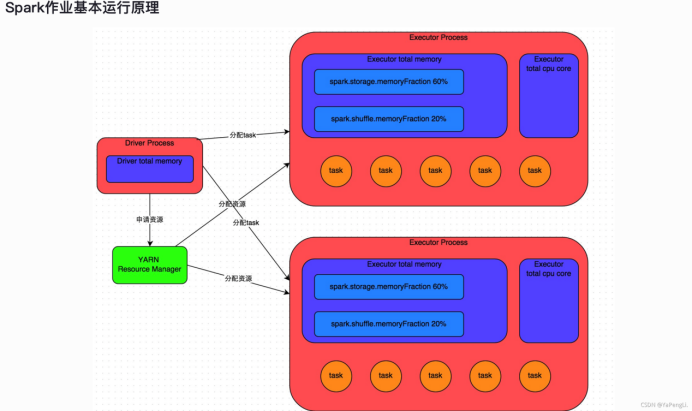
在熟悉的基本概念后,就需要对spark作业的原理有个全面的认识,如上图所示。spark作业作为计算资源敏感型的任务,其作业运行过程对资源都有着严格的规定和设置。在实际业务运行过程中,资源使用的合理性对性能的影响非常关键。以下内容在描述spark作业运行原理时,以YARN为集群管理器为例。
1、使用spark-submit命令行提交一个spark作业后,作业会启动一个driver进程,该进程会占用一定数量的内存的CPU core。
2、driver进程会向YARN集群管理器申请资源,该资源用于运行executor进程。YARN集群管理器会根据spark作业设置的资源参数,在集群管理器管理下的工作节点上,启动指定数量的executor进程,此时每个executor进程都占用指定数量的内存和CPU core。
3、申请到资源后,driver进程开始调度和执行作业代码。一般会将spark作业分为多个stage,每个stage执行部分可并行执行的代码逻辑,即每个stage会生成多个task,这些task作为最小执行单元,被分配到每个executor进程中执行。一个stage执行完,中间结果会进入下一个stage,直到所有的stage的task都执行结束,得到最终的结果。
在这里涉及到几个重要概念:
1、stage:阶段,每个作业以shuffle为边界划分出不同的阶段,即为stage,构成一组task。
2、shuffle:字面意思是混洗,是我们在代码层面执行了某个shuffle算子(如reduceByKey、join等),算子前后划分出不同的stage。这些stage各包含一部分作业代码的逻辑,后面的stage从之前的stage执行的节点拉取数据进行聚合等操作,这个过程就是shuffle。
3、持久化:spark支持在作业中执行cache/persist等持久化操作,将中间结果保存在executor进程的内存或者所在节点磁盘上。
优化2:从上面的作业原理上看,spark作业的shuffle过程是最消耗性能的地方,它会带来大量的磁盘文件读写的IO操作,以及数据的网络传输。一般建议在编写代码中尽量避免使用shuffle类算子。
资源调优
spark作业的性能好坏归根到底是看所有task执行结束所需要的时间,task在executor进程中执行,所以需要着重控制executor的资源。
从上述spark的作业原理可以看出,executor的内存主要分为三个使用部分:

1、业务代码:task执行业务代码使用的内存。
2、shuffle过程:task通过shuffle过程拉取上一个stage中task生成的数据,进行聚合等操作时使用的内存。
3、持久化:RDD数据持久化时使用的内存。
executor的CPU core数量与task的执行速度有直接的关系。一个CPU core同时只能执行一个task,每个executor进程占有若干个CPU core,分配到executor进程的多个task,可以同时并发执行。
基于上述情况,为我们对spark作业进行常规的参数调优提供了方向和依据。
以YARN为集群管理器为例,我们对spark作业的资源进行配置调优,具体的过程如下:
首先我们需要对拥有的资源有个整体的评估,在YARN UI页面上查看当前队列拥有的总内存数和总的CPU core数量,这是我们资源调优的上限,必须关注,在租户共用队列资源时尤其需要注意,避免作业的相互影响。
接下来对几个重点参数进行调优:
num-executors:整体spark作业使用的executor进程数量。
优化3:executor进程是实际执行业务逻辑的进程,占用固定数量的内存和CPU core。这里的num-executors是总进程数,在大数据作业时,如果设置少量的executor进程,spark作业会执行的非常慢。设置少或者多,没有绝对的标准,这个需要和下面具体每个executor进程设置的内存量和CPU core数量进行关联评估,标准则是不能超过总的内存数和总CPU core数量。在不设置的情况下,默认只启动少量的executor,一般建议设置50-100个。
executor-memory:每个executor进程的内存大小。
优化4:executor的内存直接影响spark作业的性能,跟常见的JVM OOM异常有关。需要关注的是,在设置的时候需要和num-executors一同评估,num-executors 乘以 executor-memory的结果【即spark作业申请到的总内存量】不能大于队列的总资源量。同时若存在和其他租户共享队列的情况,一般建议不要超过队列总内存的1/2。
executor-cores:每个executor进程的CPU core数量。
优化5:executor进程的CPU core数量决定着executor并行执行task线程的能力。每个CPU core同一时间只能执行一个task线程。 每个executor进程的CPU core数量越多,越能快速执行完分配给自己的所有task进程,需要注意的是,在设置的时候也需要和num-executors一同评估,num-executors 乘以 executor-cores的结果【即spark作业申请到的总CPU core数量】不能大于队列的总CPU core数量。同时若存在和其他租户共享队列的情况,一般建议不要超过队列总CPU core数量的1/3。
spark.default.parallelism:每个stage的默认task数量。
优化6:该参数非常重要,很多时候会被忽略掉,如果不设置,按照默认的spark设置,task的数量会非常的少,这会导致上面设置的executor进程没有task执行,或者executor进程中有空闲的CPU core,从而浪费了资源。因此spark官网建议这个参数一般设置为num-executors 乘以 executor-cores的2-3倍,这样才能充分利用spark作业的资源。
spark.storage.memoryFraction【持久化操作】:设置RDD持久化数据在executor内存种能占的比例,默认0.6,即可以使用executor进程 60%的内存来持久化。
优化7:调整的依据主要分为以下几种情况:
调大比例的情况:
1、有较多的RDD持久化操作
调小比例的情况:
1、shuffle类操作比较多,持久化操作较少。
2、频繁的gc【spark web ui 可以观察作业的gc耗时】说明task执行用户代码的内存不够用,这时需要调小。
建议按照上述情况具体分析,从而调整该参数比例。
spark.shuffle.memoryFraction【shuffle操作】:设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2,即Executor默认只有20%的内存用来进行该操作。
优化点8:调整的依据主要分为以下几种情况:
调大比例的情况:
1、RDD持久化操作较少,shuffle操作较多
调小比例的情况:
1、频繁的gc【spark web ui 可以观察作业的gc耗时】说明task执行用户代码的内存不够用,这时需要调小。
总结:
1、首先查看当前队列拥有的总资源量【总内存量,总CPU core数量,可在hadoop yarn页面上查看】
2、设置num-executors在50-100之间。
3、设置executor-memory,2-8G 【总内存量不得超过队列的总内存量】
4、设置executor-cores,2-4个【总核数不得超过队列的总核数】
5、按照executor总核数【num-executors * executor-cores】的2-3倍来设置spark.default.parallelism【必须设置,容易忽略】
6、在重shuffle操作的场景下关注spark.shuffle.memoryFraction的比例设置。
7、在涉及持久化操作多的场景下关注spark.storage.memoryFraction的比例设置。
生产环境实践
场景:租户有20亿数据,整个spark作业中主要涉及一个shuffle操作然后数据入库。一直出现shuffle报错的情况,如下图所示:

同时执行的时间非常长,如下图所示:

针对这种情况,我们首先从提交任务的命令开始分析,知道几个重点,如下图所示,

第一点,作业开启了动态资源调度。

第二点,如上图所示,设置了持久化和shuffle操作的内存占比。
然后我们根据spark ui查看了若干个task执行节点的负载,发现节点的负载非常高,如下图所示,
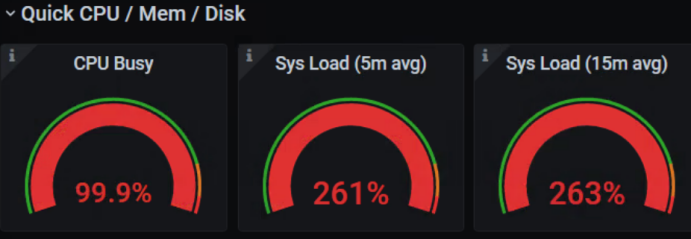
同时发现很多executor进程都被调度到了同一个节点。
之后在和租户沟通后得知,该spark任务存在重shuffle操作,作业一直以来,shuffle操作都是性能瓶颈。这时,就准备开始调整“spark.shuffle.memoryFraction”为0.5,但是结果并没有很好的改善,shuffle过程仍然耗时严重,同时伴随着失败的情况。继续扩大比例仍没有效果。
在查看节点情况时,节点情况存在非常高的负载,并且调度到相同节点的情况较多,这时设想是否是动态调度出了问题。后面将executor进程的动态资源调度关掉,使用“资源调优”中的参数进行静态设置,控制实际的资源使用情况,结果数据出来了,并且执行时间也得到了明显的改善。
分析:spark的动态资源分配可以在空闲时释放 Executor,繁忙时申请 Executor,虽然逻辑比较简单,但是和任务调度密切相关。它可以防止小数据申请大资源,Executor 空转的情况。在集群资源紧张,有多个 Spark 应用的场景下,可以开启动态分配达到资源按需使用的效果。但是在重shuffle操作的情况下,动态资源调度会导致部分executor在某些情况下无法感知外部的资源状态,例如落盘的文件等,从而导致任务的失败。
总结
从上面的参数调优和生产环境实际问题可以清楚的了解,性能调优不是一成不变,我们不仅需要在了解spark作业原理的基础上,清楚常规的参数资源调优方式,同时我们需要分析现网的业务情况,集群节点情况等,进行综合的分析才能更好的处理问题。
同时,在某些情况下,单靠参数调优无法解决性能问题,还需要从开发代码层面去分析问题,如前文说到的shuffle算子操作的情况,还有一些诸如数据倾斜的问题,都需要从业务代码层面去解决问题,由于篇幅有限,此处不再展开,后续会带来其他相关文章。
一般情况下,业务代码以jar方式存在,无法从代码层面解决问题【租户的解释是,在其他环境上可以用,为什么在当前环境上没法用。。。】,所以在解决性能问题时,我们需要最大程度的使用资源的优势,根据实际集群情况、数据量情况,优化资源调度情况,以此改善spark作业。
参考链接
1、https://spark.incubator.apache.org/
2、https://blog.csdn.net/lucklilili/article/details/120400745
3、https://www.cnblogs.com/ganshuoos/p/13703126.html



