




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
当TiDB服务不可用时,应第一时间联系TiDB支持人员,当支持人员不能及时到达时,可按此文档操作。 按此文档操作服务恢复后,也需要联系支持人员定位原因以及回滚应急操作。
TiDB Server SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。 TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。 TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。 PD Server 整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。 PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。 此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。 TiKV 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。 存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。 TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。 TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。 TiFlash TiFlash 是一类特殊的存储节点。 和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
mysql --host 127.0.0.1 --port 4000 -u root
复制
Error Number: 8003 ADMIN CHECK TABLE 命令在遇到行数据跟索引不一致的时候返回该错误,在检查表中数据是否有损坏时常出现。出现该错误时,请向 PingCAP 工程师或通过官方论坛寻求帮助。 Error Number: 8223 检测出数据与索引不一致的错误,如果遇到该报错请向 PingCAP 工程师或通过官方论坛寻求帮助。 Error Number: 8027 表结构版本过期。TiDB 采用在线变更表结构的方法。当 TiDB server 表结构版本落后于整个系统的时,执行 SQL 将遇到该错误。遇到该错误,请检查该 TiDB server 与 PD leader 之间的网络。 Error Number: 8120 获取不到事务的 start tso,请检查 PD Server 状态/监控/日志以及 TiDB Server 与 PD Server 之间的网络。 Error Number: 9001 请求 PD 超时,请检查 PD Server 状态/监控/日志以及 TiDB Server 与 PD Server 之间的网络。 Error Number: 9002 请求 TiKV 超时,请检查 TiKV Server 状态/监控/日志以及 TiDB Server 与 TiKV Server 之间的网络。 Error Number: 9005 某个 Raft Group 不可用,如副本数目不足,出现在 TiKV 比较繁忙或者是 TiKV 节点停机的时候,请检查 TiKV Server 状态/监控/日志。 Error Number: 9003 TiKV 操作繁忙,一般出现在数据库负载比较高时,请检查 TiKV Server 状态/监控/日志。 Error Number: 9012 请求 TiFlash 超时。请检查 TiFlash Server 状态/监控/日志以及 TiDB Server 与 TiFlash Server 之间的网络。 Error Number: 9013 TiFlash 操作繁忙。该错误一般出现在数据库负载比较高时。请检查 TiFlash Server 的状态/监控/日志。
场景描述:TiDB服务器宕机 | ||
业务影响:执行sql语句报错 | ||
drop database 误删除库 truncate table 清空表 drop table 误删除表 delete、update 误删除数据
SQL
mysql> select VARIABLE_NAME, VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME like 'tikv_gc_life_time';
+-------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+-------------------+----------------+
| tikv_gc_life_time | 10m0s |
+-------------------+----------------+
1 row in set (0.01 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| bbc |
| employees |
| mysql |
| sbtest |
| test |
+--------------------+
8 rows in set (0.00 sec)
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2021-10-29 15:38:08 |
+---------------------+
1 row in set (0.00 sec)
mysql> drop database sbtest;
Query OK, 0 rows affected (0.61 sec)
mysql> select count(*) from sbtest.sbtest1;
ERROR 1146 (42S02): Table 'sbtest.sbtest1' doesn't exist复制
SQL
mysql> admin show ddl jobs;
+--------+---------+------------+-------------------------------+--------------+-----------+----------+-----------+---------------------+---------------------+--------+
| JOB_ID | DB_NAME | TABLE_NAME | JOB_TYPE | SCHEMA_STATE | SCHEMA_ID | TABLE_ID | ROW_COUNT | START_TIME | END_TIME | STATE |
+--------+---------+------------+-------------------------------+--------------+-----------+----------+-----------+---------------------+---------------------+--------+
| 196 | sbtest | | drop schema | none | 84 | 0 | 0 | 2021-10-29 15:39:03 | 2021-10-29 15:39:03 | synced |
| 195 | sbtest | sbtest1 | create table | public | 84 | 194 | 0 | 2021-10-28 10:13:17 | 2021-10-28 10:13:17 | synced |
| 193 | sbtest | sbtest1 | drop table | none | 84 | 110 | 0 | 2021-10-28 10:11:24 | 2021-10-28 10:11:24 | synced |
| 192 | sbtest | sbtest1 | rename table | public | 84 | 110 | 0 | 2021-10-28 09:51:04 | 2021-10-28 09:51:04 | synced |
| 191 | sbtest | sbtest1 | drop table | none | 84 | 187 | 0 | 2021-10-28 09:50:53 | 2021-10-28 09:50:53 | synced |
| 190 | sbtest | test1 | recover table | public | 84 | 110 | 0 | 2021-10-28 09:50:04 | 2021-10-28 09:50:05 | synced |
| 189 | sbtest | sbtest1 | update tiflash replica status | public | 84 | 187 | 0 | 2021-10-28 09:49:49 | 2021-10-28 09:49:49 | synced |
| 188 | sbtest | sbtest1 | truncate table | public | 84 | 110 | 0 | 2021-10-28 09:49:43 | 2021-10-28 09:49:43 | synced |
| 186 | bbc | | create schema | public | 185 | 0 | 0 | 2021-10-27 17:37:53 | 2021-10-27 17:37:53 | synced |
| 184 | bba | | drop schema | none | 180 | 0 | 0 | 2021-10-27 17:35:02 | 2021-10-27 17:35:02 | synced |
+--------+---------+------------+-------------------------------+--------------+-----------+----------+-----------+---------------------+---------------------+--------+
10 rows in set (0.02 sec)复制
SQL
mysql> set @@tidb_snapshot="2021-10-29 15:39:01";
Query OK, 0 rows affected (0.02 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 999995 |
+----------+
1 row in set (0.52 sec)复制
SQL
./dumpling -u root -P 4000 -h 172.16.7.122 -o /tmp/test1 -t 32 -F 64MiB -B sbtest --snapshot "2021-10-29 15:39:02"复制
Makefile
[lightning]
#日志
level = "info"
file = "tidb-lightning_sbtest.log"
region-concurrency = 16
[mydumper]
数据源目录
data-source-dir = "/tmp/test1"
[tidb]
目标集群的信息。tidb-server 的地址,填一个即可
host = "172.16.7.122"
port = 4000
user = "root"
password = ""
[tikv-importer]
backend = "tidb"复制
如果选用 Local-backend 来导入数据,导入期间集群无法提供正常的服务,速度更快,适用于导入大量的数据(TB 以上级别)。 如果选用 TiDB-backend 来导入数据,导入期间集群可以正常提供服务,但相对导入速度较慢。二者的具体差别参见 TiDB Lightning Backend。
SQL
mysql> use sbtest;
Database changed
mysql> show tables;
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest2 |
| sbtest3 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
+------------------+
10 rows in set (0.00 sec)
mysql> select count(1) from sbtest1;
+----------+
| count(1) |
+----------+
| 999995 |
+----------+
1 row in set (0.65 sec)复制
SQL
mysql> SELECT * FROM mysql.tidb WHERE variable_name = 'tikv_gc_safe_point' \G
*************************** 1. row ***************************
VARIABLE_NAME: tikv_gc_safe_point
VARIABLE_VALUE: 20211027-17:11:12 +0800
COMMENT: All versions after safe point can be accessed. (DO NOT EDIT)
1 row in set (0.00 sec)复制
SQL
mysql> select count(1) from sbtest1;
+----------+
| count(1) |
+----------+
| 1000000 |
+----------+
1 row in set (0.05 sec)
mysql> truncate table sbtest1;
Query OK, 0 rows affected (0.42 sec)
mysql> flashback table sbtest1 to test1;
Query OK, 0 rows affected (1.80 sec)
mysql> select count(1) from sbtest1;
+----------+
| count(1) |
+----------+
| 0 |
+----------+
1 row in set (0.01 sec)
mysql> select count(1) from test1;
+----------+
| count(1) |
+----------+
| 1000000 |
+----------+
1 row in set (0.05 sec)
mysql> drop table sbtest1;
Query OK, 0 rows affected (0.70 sec)
mysql> alter table test1 rename to sbtest1;
Query OK, 0 rows affected (0.30 sec)复制
SQL
mysql> drop table sbtest1;
Query OK, 0 rows affected (0.59 sec)
mysql> FLASHBACK TABLE sbtest1;
Query OK, 0 rows affected (1.68 sec)
mysql> select count(1) from sbtest1;
+----------+
| count(1) |
+----------+
| 1000000 |
+----------+
1 row in set (0.03 sec)复制
SQL
mysql> select VARIABLE_NAME, VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME like 'tikv_gc_life_time';
+-------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+-------------------+----------------+
| tikv_gc_life_time | 10m0s |
+-------------------+----------------+
1 row in set (0.01 sec)
mysql> select id,k from sbtest1 where id in (1,2,3,4,5,6,7);
+----+--------+
| id | k |
+----+--------+
| 1 | 504616 |
| 2 | 503857 |
| 3 | 459563 |
| 4 | 499299 |
| 5 | 350856 |
| 6 | 498938 |
| 7 | 499050 |
+----+--------+
7 rows in set (0.00 sec)
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2021-10-28 10:31:26 |
+---------------------+
1 row in set (0.00 sec)
mysql> delete from sbtest1 where id in (1,2,3,4,5);
Query OK, 5 rows affected (0.03 sec)
mysql> select id,k from sbtest1 where id in (1,2,3,4,5,6,7);
+----+--------+
| id | k |
+----+--------+
| 6 | 498938 |
| 7 | 499050 |
+----+--------+
2 rows in set (0.00 sec)
mysql> set@@tidb_snapshot="2021-10-28 10:31:26";
Query OK, 0 rows affected (0.03 sec)
mysql> select id,k from sbtest1 where id in (1,2,3,4,5,6,7);
+----+--------+
| id | k |
+----+--------+
| 1 | 504616 |
| 2 | 503857 |
| 3 | 459563 |
| 4 | 499299 |
| 5 | 350856 |
| 6 | 498938 |
| 7 | 499050 |
+----+--------+
7 rows in set (0.00 sec)复制
Apache
dumpling -h 172.21.xx.xx -P 4000 -uroot -p xxx -t 32 -F 64MiB -B xxx_ods -T xxx_ods.xxx_comment --snapshot "2020-11-17 09:55:00" -o ./da复制
tiup cluster display tidb-test复制
tail -1000 /var/log/messages
tail -1000 <deploy_dir>/log复制
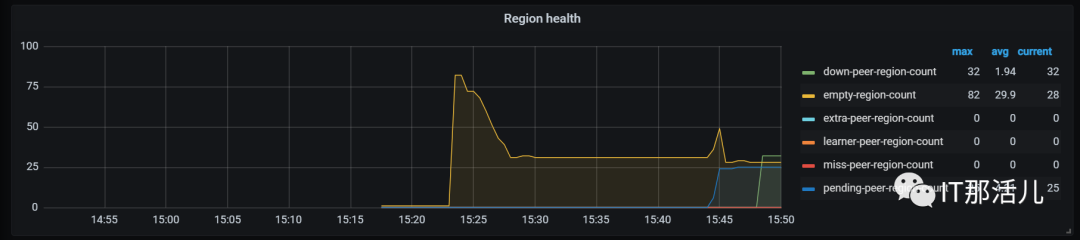
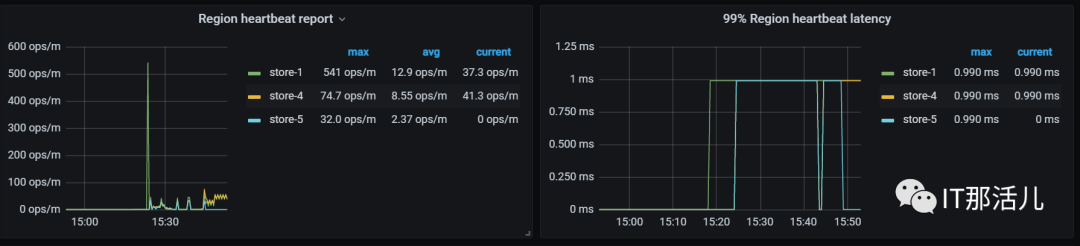
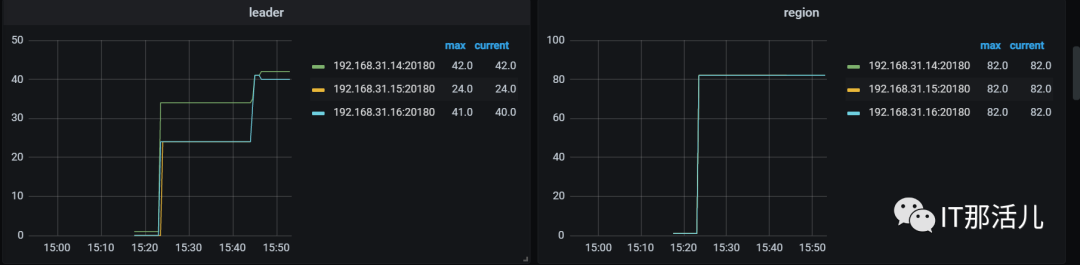
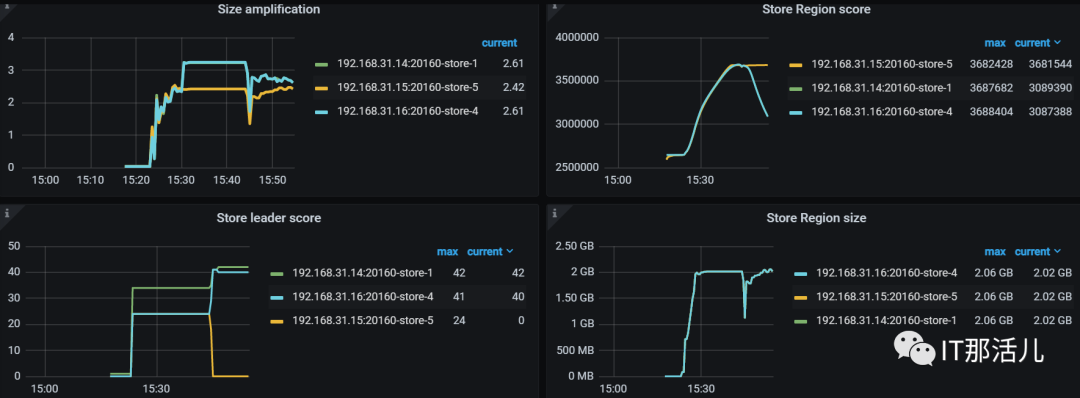
tiup cluster scale-in tidb-test -N XXX.XXX.XX.15:20160复制
tiup cluster scale-in tidb-test -N XXX.XXX.XX.15:20160 --force复制
tiup cluster edit-config tidb-test
vi scale-out-tikv.yaml复制
tiup cluster scale-out tidb-test scale-out-tikv.yaml -uroot -p复制
9.1.12.31:3000复制
启动参数中的地址已经被其他的 TiKV 注册在 PD 集群中了。造成该错误的常见情况:TiKV--data-dir 指定的路径下没有数据文件夹(删除或移动后没有更新 --data-dir),用之前参数重新启动该 TiKV。请尝试用 pd-ctl 的 store delete 功能,删除之前的 store,然后重新启动 TiKV 即可。
tiup ctl:<cluster-version> pd -u http://<pd_ip>:<pd_port> [-i]
查看store
store
删除指定store
store delete 1
删除所有tombstone
store remove-tombstone复制
["add ddl item to syncer, you can add this commit ts to `ignore-txn-commit-ts` to skip this ddl if needed"]
[sql="create index idx_usercode_updatedate_realpay on mesorderuser.mes_order_infos(user_code,update_date,real_pay)"]
["commit ts"=428853636475125794]复制
11.2 原因分析
config:
syncer.ignore-txn-commit-ts: [428853636475125794]复制
/home/tidb/.tiup/storage/cluster/clusters/gsc-tczy/meta.yaml复制
tiup cluster reload gsc-tczy -N 9.1.12.33:8349 -R drainer复制
本文作者:白炀斌(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
MySQL8.0统计信息总结
闫建(Rock Yan)
558次阅读
2025-03-17 16:04:03
MySQL生产实战优化(利用Index skip scan优化性能提升257倍)
chengang
378次阅读
2025-03-17 10:36:40
MySQL数据库当前和历史事务分析
听见风的声音
352次阅读
2025-04-01 08:47:17
墨天轮个人数说知识点合集
JiekeXu
332次阅读
2025-04-01 15:56:03
MySQL 生产实践-Update 二级索引导致的性能问题排查
chengang
322次阅读
2025-03-28 16:28:31
Oracle SQL 执行计划分析与优化指南
Digital Observer
287次阅读
2025-04-01 11:08:44
MySQL8.0直方图功能简介
Rock Yan
260次阅读
2025-03-21 15:30:53
MySQL 有没有类似 Oracle 的索引监控功能?
JiekeXu
244次阅读
2025-03-19 23:43:22
云和恩墨杨明翰:安全生产系列之MySQL高危操作
墨天轮编辑部
238次阅读
2025-03-27 16:45:26
openHalo问世,全球首款基于PostgreSQL兼容MySQL协议的国产开源数据库
严少安
227次阅读
2025-04-07 12:14:29
