




一、概述
“下推”是数据库管理系统优化查询性能的一种思路,单机数据库支持谓词下推和投影下推,通过将Filter(过滤)和Project(映射)算子在算子数中向下移动,提前对行/列进行裁剪的方式来减少后续计算处理的数据量。对于分布式数据库AntDB-M,将继续沿用单机数据库的执行思路,来解决跨节点访问数据的开销。
二、条件下推
分布式数据库与单机不同,分布式数据库的数据在不同的数据节点需要避免过多复杂的算子下推而导致查询性能下降。比如:Hash Join、FileSort、涉及临时表、Agg Merge等,其分类如下:
表1:条件分类
条件类型 | 是否支持 | 备注 |
谓词下推 | 支持 | 支持率约99%,对使用场景复杂且频率极低的,暂不支持 |
列裁剪 | 支持 | |
Join下推 | 支持 | 不支持BNL和BKA |
Sort下推 | 支持 | 不支持Jion前file sort |
Agg下推 | 支持 | 算子单独实现 |
三、实现方式
当分布式数据库条件下推时,在接入端序列化条件树,数据节点(服务端)反序列化条件树在服务端行记录返回前,执行条件树需要判断当前行是否满足条件。
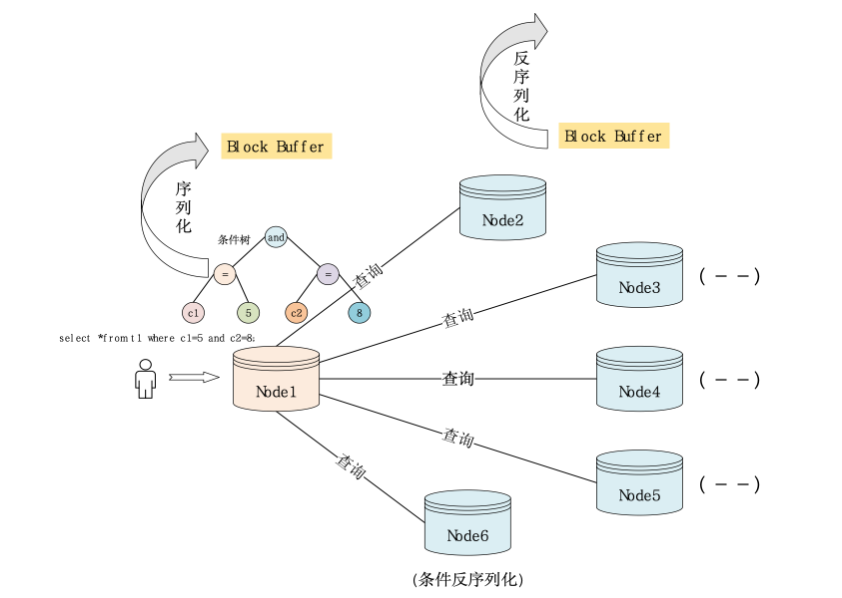
图1:下推示意图
(1) 条件树序列化
条件树的序列化过程,就是将内存中的树型条件链表,转化为可识别的标记型xml语言,然后打包写入到上行包。

图2:序列化
(2) 条件树反序列化
服务端节点接收到数据包,将Block Buffer转化为标记型xml语言,并重构树型条件链表。为减少重复发送,客户端只在首次访问时发送条件树。

图3:反序列化
(3) 驱动算子
多张表关联查询时,执行Nest Loop算法,SQL优化为由小表驱动大表的嵌套循环操作。这里涉及到驱动表和被驱动表,被驱动表执行时,需要检测驱动表记录是否发生切换。

图4:驱动算子
执行tb2查询时,驱动表tb1字段(id)在条件树中称之为“驱动算子”,根据tb1行唯一标识(Row_id)的值,判断记录是否切换。若驱动算子的值发生变化,需要将驱动算子的值重新推到远端节点。远端节点接收到新的驱动算子,需要将其回写到驱动表行记录中,这个回写的过程称之为“回表”,保证所有节点的上下文一致。
四、总结
分布式数据库支持谓词下推和投影(列裁剪)下推,优化产生的副作用极小,关联Join通过驱动表回表等操作来实现下推功能。为进一步降低网络开销,定义规则表,将Agg算子整体下推,并在接入端Merge。批量查询/更新、服务端自动提交、延迟发送等优化技术,能够合理的计算下推大幅降低网络开销,提升查询性能。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。
