




1. 背景
数据库系统在同一时间需要承载很多的用户读写行为,而读写的动作在内核里面并不是原子动作,所以这里就带来了数据不一致的问题,即A用户可能看到B用户写了一半的数据。
解决办法之一是加锁,在写的时候就锁住正在更新的数据,让其他人无法读,反之亦然。这种方案可以确保数据一致,但是却降低了系统的吞吐量,实际业务中基本都是读写并存的,如果写阻塞了读,那么势必带来较高的响应延迟。
因此众多数据库系统都选择了办法二——多版本并发控制(Multi-Version Concurrency Control, MVCC),顾名思义这是通过冗余一份数据来提高并发性能。所谓的多版本,就是指当数据更新时,旧的数据并不会立刻删除,这样其他用户依旧可以读历史数据,读写也就可以并发执行。
AntDB也有专属自己的MVCC方案,并不像Oracle那样采用了UNDO LOG,而是选择直接将新数据插入到相关表页中,在同一个存储区域中保存数据的多个版本。也正因此,引入了一个可见性判断的逻辑,即读写数据之时,需要判断哪个版本的数据对当前的事务可见。因此本文主要介绍AntDB数据库的可见性判断的逻辑,帮助大家理解AntDB的并发设计。
2. 可见性判断的基础——数据结构
AntDB内数据存储格式如下(tuple对象的数据结构):
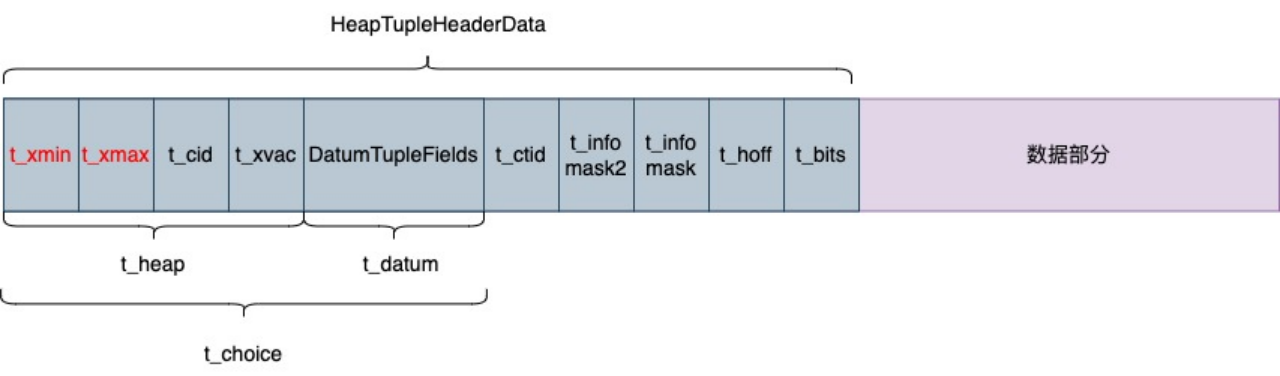
图1:AntDB内的数据存储格式
从图中可以看出,一行数据整体上分为2个组成部分,即行头和实际数据(完整的定义可以参考源码:src/include/access/htup_details.h)。其中行头里面就保存了这行数据的一些状态信息,而与可见性判断息息相关的有2个,t_xmin和t_xmax:
t_xmin:记录写入这行数据的事务号
t_xmax:记录删除这行数据的事务号
t_cid:命令ID,从0开始计数,表示当前事务内,在本命令之前一共执行了多个命令
t_infomask:位掩码,主要保存了事务执行的状态
除了源码分析,通过SQL语句也可以直接在数据库内查看到这些数据,例如:
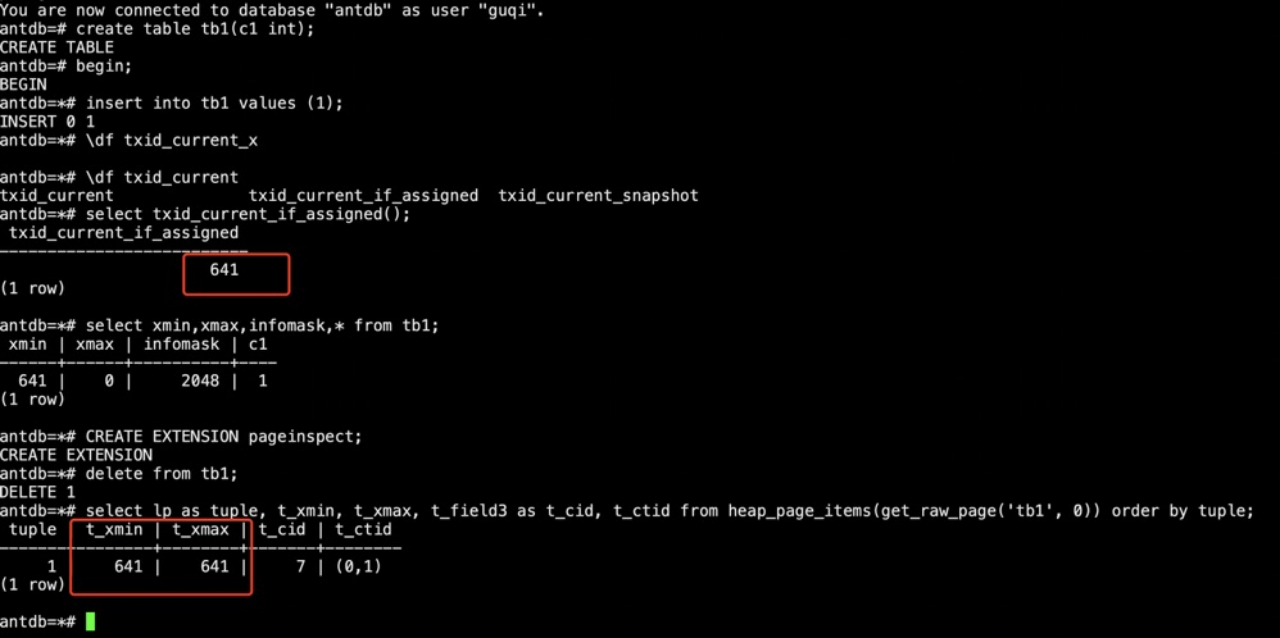
图2:SQL语句查询数据
注:截图内用到了pageinspect这个插件,这是用于观察数据存储状态的工具。
3. 可见性判断的逻辑
3.1 事务快照
通过上面的分析可以看到,AntDB内所有的数据都与更新(Insert/Delete/Update)它的事务相关,因此可见性判断的依据就是事务号的状态。每条SQL语句执行时都会获取事务快照,再结合tuple头内的事务号,就能判断哪些数据对当前SQL语句是可见的。
举个例子,一条SQL语句获取了654:660:655,657这个快照,在判断可见性时,遵循下面的规则:
l 所有 txid < 654 的并且已提交的 tuple 都是对当前快照可见的。
l 所有 txid >= 660 的 tuple 不管其状态如何,对当前快照都是不可见的。
l 由于 655 和 657 在获取快照时仍然处于活跃状态,因此对于该快照也是不可见的。
l 对于 txid 为 654,656,658,659的元组而言,只要其事务提交了,那么对当前快照来说就是可见的。
3.2 可见性判断逻辑
事务的状态,一般有3种(本文中暂不考虑子事务的情况),分别是:
l TRANSACTION_STATUS_IN_PROGRESS: 事务正在运行中
l TRANSACTION_STATUS_COMMITTED: 事务已提交
l TRANSACTION_STATUS_ABORTED: 事务已回滚
AntDB内核之中,判断可见性的核心函数之一是HeapTupleSatisfiesMVCC(函数的源码位于:src/backend/access/heap/heapam_visibility.c)。SQL语句在处理每行tuple时,取出了xmin、xmax这些数据,且需要结合其状态来判断。
xmin为ABORTED状态,这是相对最简单的一个场景,表示更新这行数据的事务已经回滚,即DBA常说的“dead tuple”,这种数据对当前快照用于不可见。
xmin为IN_PROGRESS状态,表示更新这行数据的事务还处于活跃中,绝大多数情况下,这行数据对当前快照不可见。有一个例外,即这行数据是本事务之前的命令创建的,此时就需要通过t_cid的值来判断了:值大的可以看到值小的,所以这种情况下可见(后来的命令,t_cid一定大于之前的命令)。
xmin为COMMITED状态,这个情况相对复杂,原因是事务的提交、事务状态的更新、快照的更新都不是原子行为,所以存在很多中间状态,需要结合多个条件来判断,不能单纯认为提交了就能看见。这里通过一小段伪代码来解释:
if xid仍在snapshot之中
return false
if xmax无效(tuple未被删除)
return true
if xmax有效,但尚未提交(tuple已删除,但事务未提交)
if xmax是本事务
if tuple->cid >= snapshot->cid (删除在后)
return true
else
return false
if xmax仍在snapshot之中
return true
else
if xmax仍在snapshot之中
return true
return false
4. 总结
AntDB通过这样一套机制,既保障了数据的一致性,又提高了系统的并发性能,整体来看是套非常成熟的设计方案。在硬件足够支撑的情况下,可以达到百万TPS的吞吐量。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。
