




5.3.6 基于鲲鹏服务器的性能优化
本章着重介绍openGauss基于硬件结构的锁相关的函数及结构体的性能优化。
1. WAL Group inset优化
数据库redo日志缓存系统指的是数据库redo日志持久化的写缓存,数据库redo日志落盘之前会写入到日志缓存中再写到磁盘进行持久化。日志缓存的写入效率是决定数据库整体吞吐量的主要因素,而各个线程之间写日志时为了保证日志顺序写存在锁争抢,锁的争抢就成为了性能的主要瓶颈点。openGauss针对鲲鹏服务器ARM CPU的特点,通过group的方式进行日志的插入,减少锁的争抢,提升WAL日志的插入效率,从而提升整个数据库的吞吐性能。group的方式主要流程如图5-20所示。
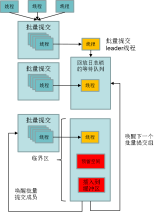
图5-20 group的方式日志插入
(1) 不需要所有线程都竞争锁。
(2) 在同一时间窗口所有线程在争抢锁之前先加入到一个group中,第一个加入group的线程作为leader。通过CAS原子操作来实现队列的管理。
(3) leader线程代表整个group去争抢锁。group中的其他线程(follower)开始睡眠,等待leader唤醒。
(4) 争抢到锁后,leader线程将group里的所有线程想要插入的日志遍历一遍得到需要空间总大小。leader线程只执行一次reserve space操作。
(5) leader线程将group中所有线程想要写入的日志都写入到日志缓冲区中。
(6) 释放锁,唤醒所有follower线程。
(7) follower线程由于需要写入的日志已经被leader写入,不需要再争抢锁,直接进入后续流程。
关键函数代码如下:
{
…/* 初始化变量以及简单校验 */
START_CRIT_SECTION(); /* 开启临界区 */
proc->xlogGroupMember = true;
…
proc->xlogGroupDoPageWrites = &t_thrd.xlog_cxt.doPageWrites;
nextidx = pg_atomic_read_u32(&t_thrd.shemem_ptr_cxt.LocalGroupWALInsertLocks[groupnum].l.xlogGroupFirst);
while (true) {
pg_atomic_write_u32(&proc->xlogGroupNext, nextidx); /* 将上一个成员记录到proc结构体中 */
/* 防止ARM乱序:保证所有前面的写操作都可见 */
pg_write_barrier();
if (pg_atomic_compare_exchange_u32(&t_thrd.shemem_ptr_cxt.LocalGroupWALInsertLocks[groupnum].l.xlogGroupFirst,
&nextidx,
(uint32)proc->pgprocno)) {
break;
} /* 这一步原子操作获取上一个成员的proc no,如果是invalid,说明是leader。 */
}
/* 非leader成员不去获取WAL Insert锁,仅仅进行等待,直到被leader唤醒 */
if (nextidx != INVALID_PGPROCNO) {
int extraWaits = 0;
for (;;) {
/* 充当读屏障 */
PGSemaphoreLock(&proc->sem, false);
/* 充当读屏障 */
pg_memory_barrier();
if (!proc->xlogGroupMember) {
break;
}
extraWaits++;
}
while (extraWaits-- > 0) {
PGSemaphoreUnlock(&proc->sem);
}
END_CRIT_SECTION();
return proc->xlogGroupReturntRecPtr;
}
/* leader成员持有锁 */
WALInsertLockAcquire();
/* 计算每个成员线程的xlog record size */
…
/* leader线程将所有成员线程的xlog record插入到缓冲区 */
while (nextidx != INVALID_PGPROCNO) {
localProc = g_instance.proc_base_all_procs[nextidx];
if (unlikely(localProc->xlogGroupIsFPW)) {
nextidx = pg_atomic_read_u32(&localProc->xlogGroupNext);
localProc->xlogGroupIsFPW = false;
continue;
}
XLogInsertRecordNolock(localProc->xlogGrouprdata,
localProc,
XLogBytePosToRecPtr(StartBytePos),
XLogBytePosToEndRecPtr(
StartBytePos + MAXALIGN(((XLogRecord*)(localProc->xlogGrouprdata->data))->xl_tot_len)),
XLogBytePosToRecPtr(PrevBytePos));
PrevBytePos = StartBytePos;
StartBytePos += MAXALIGN(((XLogRecord*)(localProc->xlogGrouprdata->data))->xl_tot_len);
nextidx = pg_atomic_read_u32(&localProc->xlogGroupNext);
}
WALInsertLockRelease(); /* 完成工作放锁并唤醒所有成员线程 */
while (wakeidx != INVALID_PGPROCNO) {
PGPROC* proc = g_instance.proc_base_all_procs[wakeidx];
wakeidx = pg_atomic_read_u32(&proc->xlogGroupNext);
pg_atomic_write_u32(&proc->xlogGroupNext, INVALID_PGPROCNO);
proc->xlogGroupMember = false;
pg_memory_barrier();
if (proc != t_thrd.proc) {
PGSemaphoreUnlock(&proc->sem);
}
}
END_CRIT_SECTION();
return proc->xlogGroupReturntRecPtr;
}
2. Cache align消除伪共享
CPU在访问主存时一次会获取整个缓存行的数据,其中x86典型值是64字节,而ARM 1620芯片L1和L2缓存都是64字节,L3缓存是128字节。这种数据获取方式本身可以大大提升数据访问的效率,但是假如同一个缓存行中不同位置的数据频繁被不同的线程读取和写入,由于写入的时候会造成其他CPU下的同一个缓存行失效,从而使得CPU按照缓存行来获取主存数据的努力不但白费,反而成为性能负担。伪共享就是指这种不同的CPU同时访问相同缓存行的不同位置的性能低效的行为。
以LWLock为例,代码如下所示:
#define LWLOCK_PADDED_SIZE PG_CACHE_LINE_SIZE(128)
#else
#define LWLOCK_PADDED_SIZE (sizeof(LWLock) <= 32 ? 32 : 64)
#endif
typedef union LWLockPadded
{
LWLocklock;
charpad[LWLOCK_PADDED_SIZE];
} LWLockPadded;
当前锁逻辑中LWLock的访问仍然是最突出的热点之一。如果LWLOCK_PADDED_SIZE是32字节,且LWLock是按照一个连续的数组来存储的,对于64字节的缓存行可以同时容纳两个LWLockPadded,128字节的缓存行则可以同时含有4个LWLockPadded。当系统中对LWLock竞争激烈时,对应的缓存行不停地获取和失效,浪费大量CPU资源。故在ARM机器的优化下将padding_size直接设置为128,消除伪共享,提升整体LWLock的使用性能。
3. WAL INSERT 128CAS无锁临界区保护
目前数据库或文件系统,WAL需要把内存中生成的日志信息插入到日志缓存中。为了实现日志高速缓存,日志管理系统会并发插入,通过预留全局位置来完成,一般使用两个64位的全局数据位置索引分别表示存储插入的起始和结束位置,最大能提供16EB(Exabyte)的数据索引的支持。为了保护全局的位置索引,WAL引入了一个高性能的原子锁实现每个日志缓存位置的保护,在NUMA架构中,特别是ARM架构中,由于原子锁退避和高跨CPU访问延迟,缓存一致性性能差异导致WAL并发的缓存保护成为瓶颈。
优化的主要涉及思想是将两个64位的全局数据位置信息通过128位原子操作替换原子锁,消除原子锁本身在跨CPU访问、原子锁退避(backoff)、缓存一致性代价。如图5-21所示。
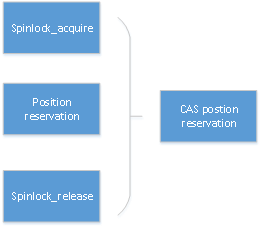
图5-21 128CAS无锁临界区保护示意图
全局位置信息包括一个64位起始地址和一个64位的结束地址,将这两个地址合并成为一个128位信息,通过CAS原子操作完成免锁位置信息的预留。在ARM平台中没有实现128位的原子操作库,openGauss通过exclusive命令加载两个ARM64位数据来实现,ARM64汇编指令为LDXP/STXP。
关键数据结构及函数ReserveXLogInsertLocation的代码如下:
uint128 u128;
uint64 u64[2];
uint32 u32[4];
} uint128_u; /* 为了代码可读及操作,将u128设计成union的联合结构体,内存位置进行64位数值的赋值。 */
static void ReserveXLogInsertLocation(uint32 size, XLogRecPtr* StartPos, XLogRecPtr* EndPos, XLogRecPtr* PrevPtr)
{
volatile XLogCtlInsert* Insert = &t_thrd.shemem_ptr_cxt.XLogCtl->Insert;
uint64 startbytepos;
uint64 endbytepos;
uint64 prevbytepos;
size = MAXALIGN(size);
#if defined(__x86_64__) || defined(__aarch64__)
uint128_u compare;
uint128_u exchange;
uint128_u current;
compare = atomic_compare_and_swap_u128((uint128_u*)&Insert->CurrBytePos);
loop1:
startbytepos = compare.u64[0];
endbytepos = startbytepos + size;
exchange.u64[0] = endbytepos; /* 此处为了代码可读,将uint128设置成一个union的联合结构体。将起始和结束位置写入到exchange中。 */
exchange.u64[1] = startbytepos;
current = atomic_compare_and_swap_u128((uint128_u*)&Insert->CurrBytePos, compare, exchange);
if (!UINT128_IS_EQUAL(compare, current)) { /* 如果被其他线程并发更新,重新循环*/
UINT128_COPY(compare, current);
goto loop1;
}
prevbytepos = compare.u64[1];
#else
SpinLockAcquire(&Insert->insertpos_lck); /* 其余平台使用自旋锁原子锁来保护变量更新 */
startbytepos = Insert->CurrBytePos;
prevbytepos = Insert->PrevBytePos;
endbytepos = startbytepos + size;
Insert->CurrBytePos = endbytepos;
Insert->PrevBytePos = startbytepos;
SpinLockRelease(&Insert->insertpos_lck);
#endif /* __x86_64__|| __aarch64__ */
*StartPos = XLogBytePosToRecPtr(startbytepos);
*EndPos = XLogBytePosToEndRecPtr(endbytepos);
*PrevPtr = XLogBytePosToRecPtr(prevbytepos);
}
4. CLOG Partition优化
CLOG日志即是事务提交日志(详情可参考章节“5.2.2 事务ID分配及CLOG/CSNLOG)”,每个事务存在4种状态:IN_PROGRESS、COMMITED、ABORTED、SUB_COMMITED,每条日志占2 bit。CLOG日志需要存储在磁盘上,一个页面(8kB)可以包含215条,每个日志文件(段=256 x 8k)226条。当前CLOG的访问通过缓冲池实现,代码中使用统一的SLRU缓冲池算法。
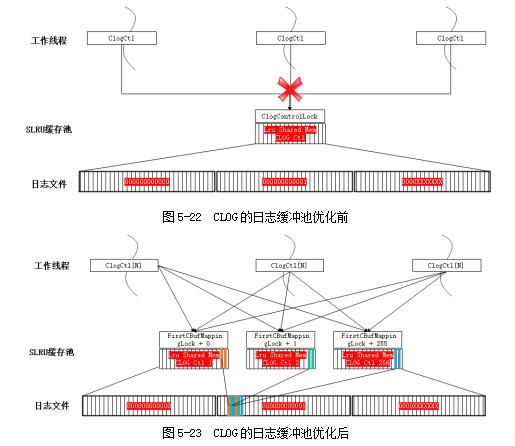
如图5-22所示,CLOG的日志缓冲池在共享内存中且全局唯一,名称为名称为“CLOG Ctl”,为各工作线程共享该资源。在高并发的场景下,该资源的竞争成为性能瓶颈,优化分区后如图5-23。按页面号进行取模运算(求两个数相除的余数)将日志均分到多个共享内存的缓冲池中,由线程局部对象的数组ClogCtlData来记录,名称为“CLOG Ctl i”,同步增加共享内存中的缓冲池对象及对应的全局锁。也就是通过打散的方式提高整体吞吐。
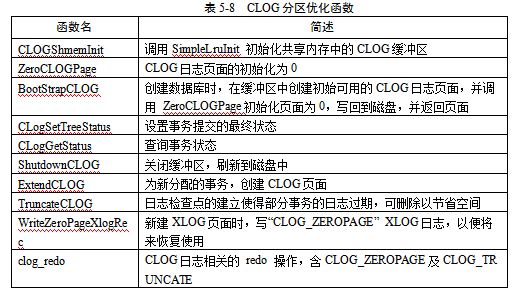
CLOG分区优化需要将源代码中涉及原缓冲池的操作进行修改,改为操作对应的分区的缓冲池,而通过事务id、页面号能方便地找到对应的分区,与此同时对应的控制锁也从原来的一把锁改为多把锁的操作,涉及的结构体代码如下,涉及的函数如表5-8所示:
#define NUM_CLOG_PARTITIONS 256 /*分区打散的个数*/
/* CLOG轻量级分区锁*/
#define CBufHashPartition(hashcode) \
((hashcode) % NUM_CLOG_PARTITIONS)
#define CBufMappingPartitionLock(hashcode) \
(&t_thrd.shemem_ptr_cxt.mainLWLockArray[FirstCBufMappingLock + CBufHashPartition(hashcode)].lock)
#define CBufMappingPartitionLockByIndex(i) \
(&t_thrd.shemem_ptr_cxt.mainLWLockArray[FirstCBufMappingLock + i].lock)
5. 支持NUMA-aware数据和线程访问分布
NUMA远端访问:内存访问涉及访问线程和被访问内存两个的物理位置。只有两者在同一个NUMA Node中时,内存访问才是本地的,否则就会涉及跨Node远端访问,此时性能开销较大。
Numactl开源软件提供了libnuma库允许应用程序方便地将线程绑定在特定的NUMA Node或者CPU列表,可以在指定的NUMA Node上分配内存。下面对openGauss代码可能涉及的api进行描述。
(1) “int numa_run_on_node(int node);”将当前任务及子任务运行在指定的Node上。该API对应函数如下所示。

如图5-24所示,对每个客户端连接系统都会分配一个专门的PGPROC结构来维护相关信息。ProcGlobal->allProcs原本是一个PGPROC结构的全局数组,但是其物理内存所在的NUMA Node是不确定的,造成每个事务线程访问自己的PGPROC结构时,线程可能由于操作系统的调度在多个NUMA Node间,而对应的PGPROC结构的物理内存位置也是无法预知,大概率会是远端访存。
由于PGPROC结构的访问较为频繁,根据NUMA Node的个数将这个全局结构数组分为多份,每份分别使用numa_alloc_onnode来固定NUMA Node分配内存。为了尽量减少对当前代码的结构性改动,将ProcGlobal->allProcs由PGPROC* 改为PGPROC**。对应所有访问ProcGlobal->allProcs的地方均需要做相应调整(多了一层间接指针引用)。相关代码如下:
if (nNumaNodes > 1) {
ereport(INFO, (errmsg("InitProcGlobal nNumaNodes: %d, inheritThreadPool: %d, groupNum: %d",
nNumaNodes, g_instance.numa_cxt.inheritThreadPool,
(g_threadPoolControler ? g_threadPoolControler->GetGroupNum() : 0))));
int groupProcCount = (TotalProcs + nNumaNodes - 1) / nNumaNodes;
size_t allocSize = groupProcCount * sizeof(PGPROC);
for (int nodeNo = 0; nodeNo < nNumaNodes; nodeNo++) {
initProcs[nodeNo] = (PGPROC *)numa_alloc_onnode(allocSize, nodeNo);
if (!initProcs[nodeNo]) {
ereport(FATAL, (errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("InitProcGlobal NUMA memory allocation in node %d failed.", nodeNo)));
}
add_numa_alloc_info(initProcs[nodeNo], allocSize);
int ret = memset_s(initProcs[nodeNo], groupProcCount * sizeof(PGPROC), 0, groupProcCount * sizeof(PGPROC));
securec_check_c(ret, "\0", "\0");
}
} else {
#endif
2) 全局WALInsertLock数组优化
WALInsertLock用来对WAL Insert操作进行并发保护,可以配置多个,比如16。优化前,所有的WALInsertLock都在同一个全局数组,并通过共享内存进行分配。事务线程运行时在整个全局数组中分配其中的一个Insert Lock进行使用,因此大概率会涉及远端访存,即多个线程会进行跨Node、跨P竞争。WALInsertLock也可以按NUMA Node单独分配内存,并且每个事务线程仅使用本Node分组内的WALInsertLock,这样就可以将数据竞争限定在同一个NUMA Node内部。基本原理如图5-25所示。
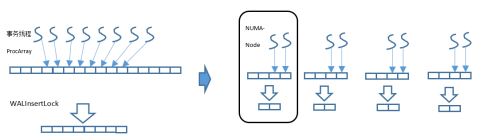
图5-25 全局WALInsertLock数组优化原理
假如系统配置了16个WALInsertLock,同时NUMA Node配置为4个,则原本长度为16的数组将会被拆分为4个数组,每个数组长度为4。全局结构体为“WALInsertLockPadded **GlobalWALInsertLocks”,线程本地WALInsertLocks将由指向本Node内的WALInsertLock[4],不同的NUMA Node下拥有不同地址的WALInsertLock子数组。GlobalWALInsertLocks则用于跟踪多个Node下的WALInsertLock数组,以方便遍历。WALInsertLock分组方式如图5-26所示。
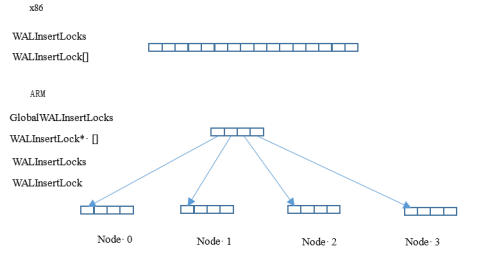
图5-26 WALInsertLock分组示意图
初始化WALInsertLock结构体的代码如下:
(WALInsertLockPadded**)CACHELINEALIGN(palloc0(nNumaNodes * sizeof(WALInsertLockPadded*) + PG_CACHE_LINE_SIZE));
#ifdef __USE_NUMA
if (nNumaNodes > 1) {
size_t allocSize = sizeof(WALInsertLockPadded) * g_instance.xlog_cxt.num_locks_in_group + PG_CACHE_LINE_SIZE;
for (int i = 0; i < nNumaNodes; i++) {
char* pInsertLock = (char*)numa_alloc_onnode(allocSize, i);
if (pInsertLock == NULL) {
ereport(PANIC, (errmsg("XLOGShmemInit could not alloc memory on node %d", i)));
}
add_numa_alloc_info(pInsertLock, allocSize);
insertLockGroupPtr[i] = (WALInsertLockPadded*)(CACHELINEALIGN(pInsertLock));
}
} else {
#endif
char* pInsertLock = (char*)CACHELINEALIGN(palloc(
sizeof(WALInsertLockPadded) * g_instance.attr.attr_storage.num_xloginsert_locks + PG_CACHE_LINE_SIZE));
insertLockGroupPtr[0] = (WALInsertLockPadded*)(CACHELINEALIGN(pInsertLock));
#ifdef __USE_NUMA
}
#endif
在ARM平台下,访问WALInsertLock需遍历GlobalWALInsertLocks两维数组,第一层遍历NUMA Node,第二层遍历Node内部的WALInsertLock数组。
WALInsertLock引用的LWLock内存结构在ARM平台下也进行的相应的优化适配,代码如下所示:
{
LWLock lock;
#ifdef __aarch64__
pg_atomic_uint32xlogGroupFirst;
#endif
XLogRecPtrinsertingAt;
} WALInsertLock;
这里的lock成员变量将引用共享内存中的全局LWLock数组中的某个元素,在WALInsertLock优化之后,尽管WALInsertLock已经按照NUMA Node分布了,但是其引用的LWLock却无法控制其物理内存位置,因此在访问WALInsertLock的lock时仍然涉及了大量的跨Node竞争。因此将LWLock直接嵌入到WALInsertLock内部,从而将使用的LWLock一起进行NUMA分布,同时还减少了一次缓存访问。
