




[翻译]Scalable Partition Handling for Cloud-NativeArchitecture in Apache Spark 2.1
https://databricks.com/blog/2016/12/15/scalable-partition-handling-for-cloud-native-architecture-in-apache-spark-2-1.html
by Eric Liang, Michael Allman and Wenchen Fan Posted in ENGINEERING BLOGDecember 15,2016
大致内容翻译,Not逐字逐句……
本博客讨论了即将发布的最重要的功能之一:可扩展分区处理.。
Spark SQL让我们能过在一个job中查询T级别的数据。但通常情况下,用户只希望访问其中的一小部分数据,比如,扫描San Francisco而不是全世界的用户活动。这是通过用常用的过滤字段,如日期或地点,将表的数据文件进行分区来实现的。
之后Spark SQL就可以使用这些分区信息进行“裁剪”或忽略与用户查询无关的文件。然而,之前的Spark 版本中,首次读取表可能会很慢,因为Spark必须先发现哪些分区是存在的(分区发现)。
在Spark 2.1 中,我们大大改进了只查询一小部分表分区的初始延迟。某些情况下,在一个新集群上需要花费数十分钟的查询,现在可以以秒为单位来执行。我们的改进降低了表的内存开销,使SQL从表元数据完全缓存在内存中的“热”集群转换为冷集群。
Spark 2.1也统一了数据源(DataSource)和Hive表的分区管理功能。这意味着这两种表现在支持相同的分区DDL操作,比如,增加,删除和重定位特定分区。
一、Spark表管理
为了更好的理解为什么会有延迟,先介绍下Spark之前版中是如何管理表的。在这些版本中,Spark的catalog支持两种类型的表:
1. DataSource tables 是Spark中创建表时首选的格式。这种类型的表可以直接通过将一个DataFrame保存到文件系统来定义,比如:
df.write.partitionBy("date").saveAsTable("my_metrics")
,或通过一个表创建语句(CREATETABLE statement),如CREATE TABLE my_metricsUSING parquet PARTITIONED BY date
.
在之前的版本,Spark从文件系统和内存缓存中发现DataSource的表元数据。该元数据包含分区列表以及每个分区的文件统计。一旦被缓存,后续的查询就可以直接在内存中对表分区进行裁剪。
2. 对Apache Hive转来的用户,Spark SQL也可以读取由Hive serdes定义的catalog 表。Spark可以透明地将Hive表转换为DataSource格式,以便利用在Spark SQL中在IO性能上的改进。在内部,Spark会从Hive metastore中读取表和分区元数据信息并将其缓存到内存中。
这种策略下,在表元数据被缓存到内存时可以优化性能,但同时也存在两个缺点:首先,表的初始查询会被阻塞,直到Spark加载了所有的表分区元数据。对分区很多的表,初始查询时,递归地扫描文件系统来发现文件元数据会消耗不少分钟,尤其是存储在云存储,如S3上的数据。其次,表的所有元数据都需要存储在driver进程的内存中,这会增加内存压力。
我们已经从我们的客户和其他大规模Spark的用户处看到了这个问题。虽然有时候可以通过使用其他Spark APIs直接读取文件来避免初始查询的延迟,但却不能让表的性能可扩展。
在Spark 2.1, Databricks和VideoAmp一起合作来消除此开销,以及统一DataSource和Hive格式的表管理。
VideoAmp简介…….(略)
Michael Allman (VideoAmp) 描述了项目中他们参与的部分:
Spark 2.1之前,获取最大的表的元数据需要几分钟时间,并且每次增加一个新的分区就需要重新获取一次。Spark 2.0发布不久,我们开始构建一个基于延迟加载分区元数据的方法原型。同时,在社区阐明我们的想法。我们为其中一个原型向Spark源仓库提交一个PR(pullrequest),并开始为实现生产级别的可靠性和性能而一起协作。
二、性能基准
在一头扎进技术细节之前,我们先展示下我们内部一个度量表的查询延迟改进,该表有50,000个以上的分区(在Databricks,we believe in eating our own dog food)。表按日期和度量类型进行分区,大致如下:
CREATE TABLE metricData ( value BIGINT, dimensions struct<...>, date STRING, metric STRING) USING parquet OPTIONS (path 'dbfs:/mnt/path/to/data-root') PARTITIONED BY (date, metric) |
我们使用一个小的Databricks集群,包含8个workers,32个cores和250G内存。并基于一天,一周和一个月的数据运行一个简单的聚合查询,并评估新启动的Spark 集群上,首次获取结果的时间开销:
SELECT metric, avg(value) FROM metricData WHERE date >= "2016-11-01" AND date <= "2016-11-07" // ex. 1 week GROUP BY metric |
但在Spark 2.1 中启动了可扩展分区管理,读取一天的数据仅10秒多一点。该时间与查询所涉及的分区数成线性关系。为了理解时间花在什么地方,我们将查询时间分成查询计划期间的时间开销和Spark job执行的时间开销:
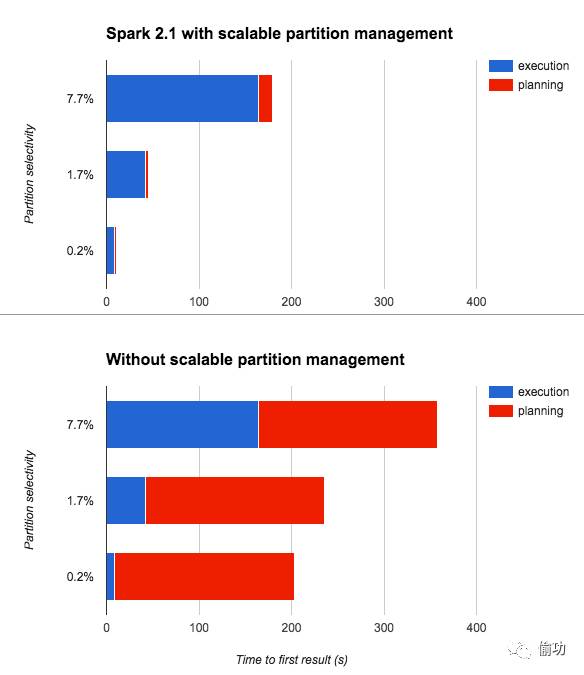
可以看到,在可扩展分区管理启动后,查询计划时间的开销(红条)是随着执行时间(蓝条)是成比例增加的,因为扫描了更多的数据。如果再次查询,则由于元数据缓存,查询计划时间可以忽略不计(太小而无法图形化)。
而对应的,如果没有启动,可以看到首次查询表时,不管是哪个查询,这都有一个很大的近200秒的常数因子。
我们预测这些改进在原生云上的Spark部署中会非常明显,因为在云上文件系统元数据的处理性能是相当慢的,并且由于短期Spark集群的使用,会频繁地要求重新缓存元数据。即使是HDFS用户也可以看到这个改进对大分区表的好处。
(一) VideoAmp 生产基准
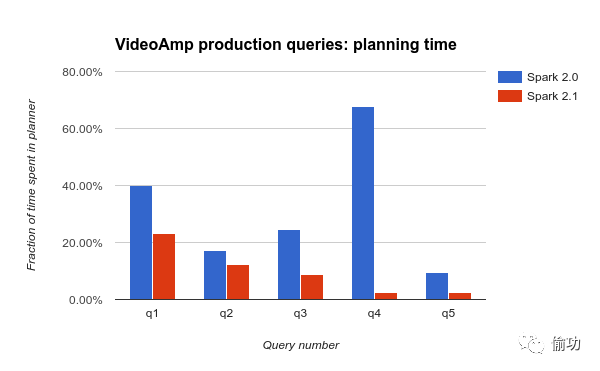
我们也表明了这些改进极大地影响了VideoAmp工作负载中的生产查询。它们运行复杂的多阶段(multi-stage)的查询,包含数十个列,在带有成千上万个分区的定期更新的表上多次聚合和联合。
VideoAmp测量了一些日常查询中在计划生成上花的时间比例,比较了Spark 2.0与2.1之间的性能。他们发现了重大的(有时是戏剧性的)改进:
三、 实现
这些好处是SparkSQL内部的两个重大改变来实现的。
对Hive 和 DataSource 表, Spark 现在在system catalog (和Hive 的metastore 一样)中存储Hive 和 DataSource 表的分区元数据。通过新的PruneFileSourcePartitions rule,在从文件系统读取元数据信息前,Catalyst优化器使用catalog在logical planning期间进行分区裁剪。这避免了在未被使用的分区中查找文件。
文件统计信息现在可以在planning期间部分地、增量地缓存,而不是全部预缓存。Spark 需要知道文件的大小,以便在物理计划中将它们拆分到各个读取tasks中。而不是急于在内存中缓存所有表文件统计信息,表现在共享一个固定250M大小(可配置)的缓存,可以不冒内存错误的风险,加快重复性查询速度。
总的来说,这些修改意味着在一个冷启动的Spark中查询速度更快。由于增量文件统计缓存,和旧的分区管理策略相比,重复查询几乎没有性能损失。
四、 新支持的分区 DDLs
这些修改的另一个好处是DataSource表支持之前只在Hive表上可用的几个DDL命令。这些DDLs允许为分区指定文件位置,而不是默认布局,比如,partition (date='2016-11-01', metric='m1')可以放置到任意的文件系统位置,而不仅仅是 /date=2016-11-01/metric=m1。
ALTER TABLE table_name ADD [IF NOT EXISTS] (PARTITION part_spec [LOCATION path], ...) ALTER TABLE table_name DROP [IF EXISTS] (PARTITION part_spec, ...) ALTER TABLE table_name PARTITION part_spec SET LOCATION path SHOW PARTITIONS [db_name.]table_name [PARTITION part_spec] |
当然,你仍然可以使用原生的DataFrameAPIs,如df.write.insertInto和 df.write.saveAsTable来添加到分区的表中。关于
Databricks中支持的DDLs的更多信息,参考
language manual。
五、 迁移提示
虽然在Spark 2.1创建新的DataSource表时,会默认使用新的可扩展的分区管理策略,但为了后向兼容,已有的表并不会这样。为了让已经存在的DataSource表也能利用这些改进,你可以使用MSCK命令将已经存在的一个表,从使用旧的分区管理策略转换为使用新的:
MSCK REPAIR TABLE table_name; |
在现有文件上创建新表时,你也需要使用MSCK REPAIR TABLE。
注意,这可能是一个向后不兼容的更改,因为直接写入表的底层文件将不再反映在表中,直到catalog也被更新。这个同步由Spark 2.1自动完成,但是从较旧的Spark版本,外部系统或Spark表的API之外的写入将需要再次调用MSCK REPAIR TABLE。
如何获知一个表的catalog分区管理是否启用? 运行一个DESCRIBEFORMATTED table_name 命令,然后检查输出信息中是否包含PartitionProvider :Catalog :
scala> sql("describe formatted test_table")复制
.filter("col_name like '%Partition Provider%'").show复制
+-------------------+---------+-------+复制
| col_name|data_type|comment|复制
+-------------------+---------+-------+复制
|Partition Provider:| Catalog| |复制
+-------------------+---------+-------+复制
六、 结论
本博客描述内容包含在Apache Spark 2.1版本中,对应参考JIRA的SPARK-17861即可。
