




之前的1.6版本源码解析已经全部发布,后续会发布一些资料地址、翻译文件、基于2.x系列的Spark源码解析与案例实战等等。 目前人手有限,文档也比较费时,后续的发布频率会比较慢,见谅...........
今天刚看到Databricks Blog上昨天发布的一篇博文,感觉整个流程非常不错(除了内部一些相关信息还需要查看Databricks相关文档,以及部分功能免费版本不提供之外),所以顺便简单翻译了下下,有兴趣的话,可以尝试做下。
原文链接:
https://databricks.com/blog/2016/12/12/apache-spark-scala-library-development-with-databricks.html
在Databricks上 Notebook 的链接:
http://go.databricks.com/hubfs/notebooks/blogs/Just%20enough%20sbt/Prototype%20Date%20Dimension.html
声明:下面只是简单翻译,NOT逐字逐句………
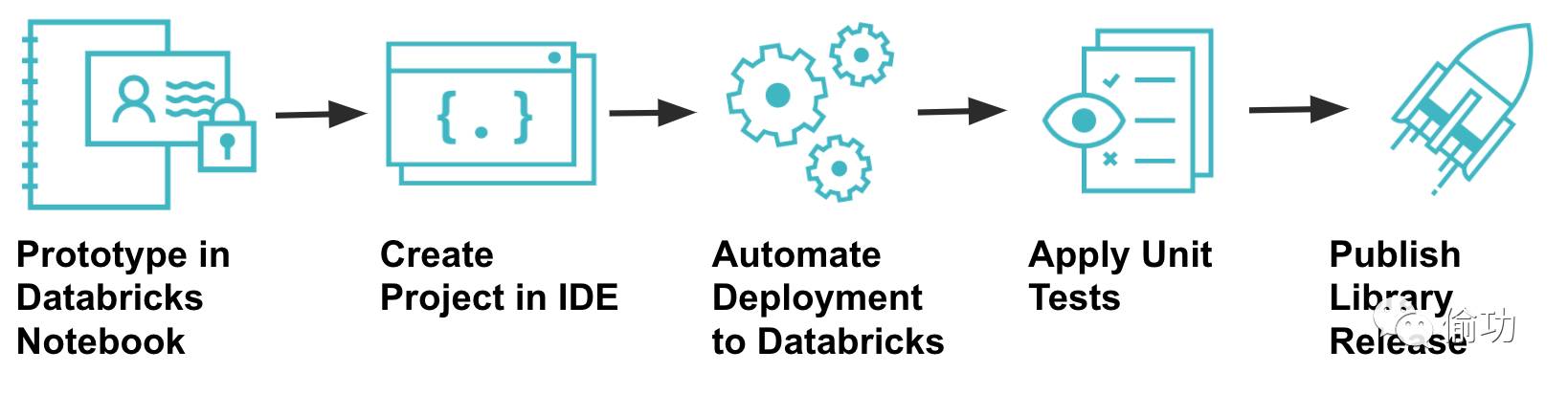
本博客介绍了如何快速构建一个Notebook原型,用于为一个数据集市构建一个Date Dimension(时间维度),然后就可以添加单元测试,构建类库然后发布了。
1 前提条件
开始前先确保已经安装了:
Git
Java (version 8 for Spark 2.0)
Maven
Scala
SBT
IntelliJ
2 Databricks Notebook上的原型构建
类似于先在草稿纸上(原文与玩具总动员电影的制作方式进行对比),你可以使用Databricks Notebooks来快速对想法进行原型构建。可以写几行代码,立即执行,查看其结果,并不断迭代这个过程。这仅仅需要几分钟来启动集群运行代码,你可以在真实的数据集上快速测试代码功能的正确性。
我(原作者…)已经构建了一些代码原型,可以构建一个能在多个数据集市中使用的Date Dimension(时间维度)。我已经用Spark构建了一个包括100年日期(100 years worth of dates)的DataFrame,并在为它创建一个SparkSQL表之前检查了DataFrame的模式(schema)和内容,创建表后任何集群都可以查询或join到该DataFrame了。
3 在IDE中创建一个工程
作者构建原型时,通常会以类库的方式去构建,然后发布到其他团队用于他们各自的数据集市。下面是在IntelliJ 上构建一个新的Scala/SBT工程的步骤。
打开Intellij并选择 “Create New Project” ,然后为该工程选择“SBT”。
设置Java SDK和Scala Versions版本,这些版本需要和你要使用的Databricks上的Apache Spark环境中的版本一致。
开启 “auto-import” 选项,可以在构建文件中添加对应类库时,自动导入。
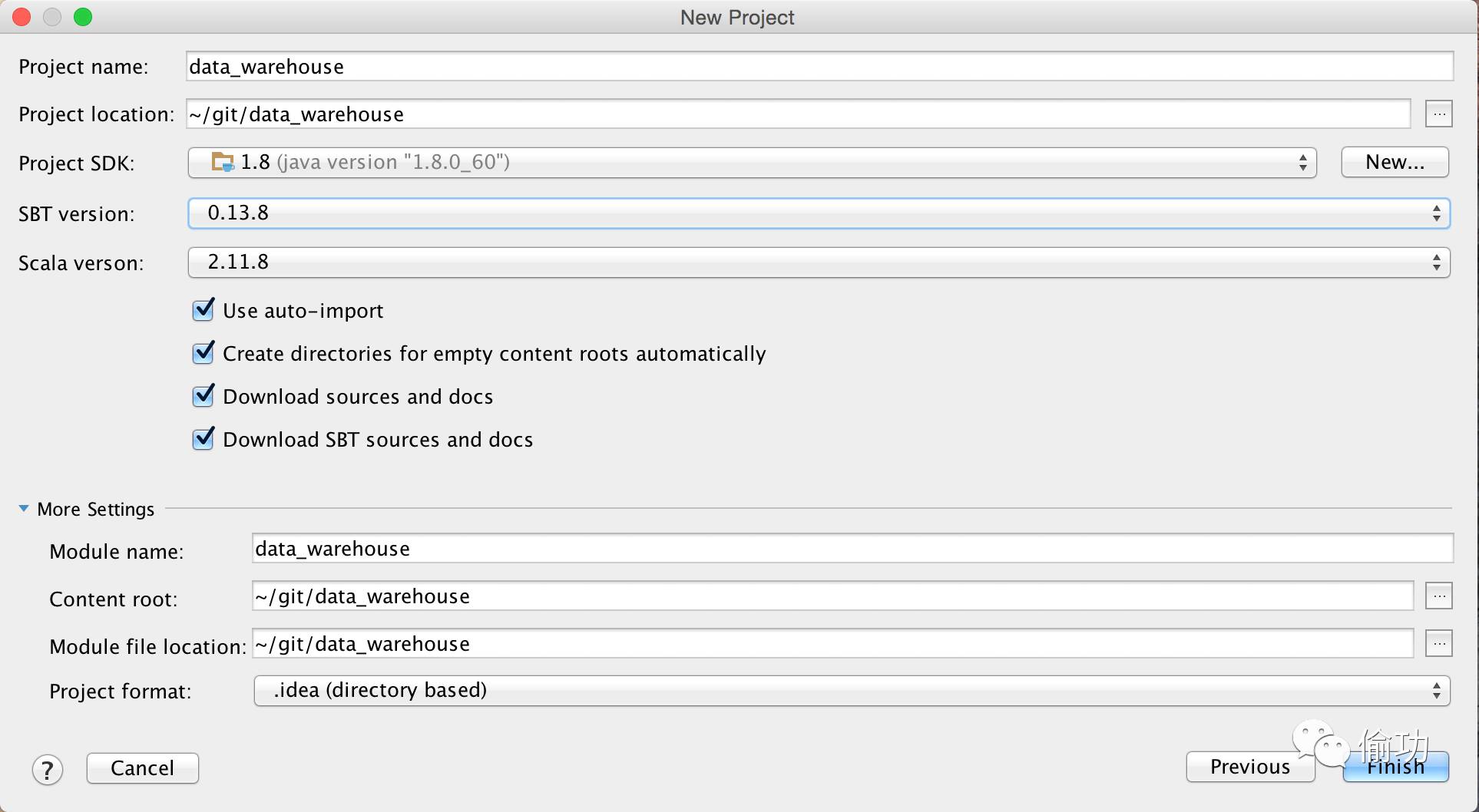
4. 在Databricks上启动一个集群,并查看Spark UI界面的“Environment”页面,检查在Databricks上所使用的Apache Spark 环境。
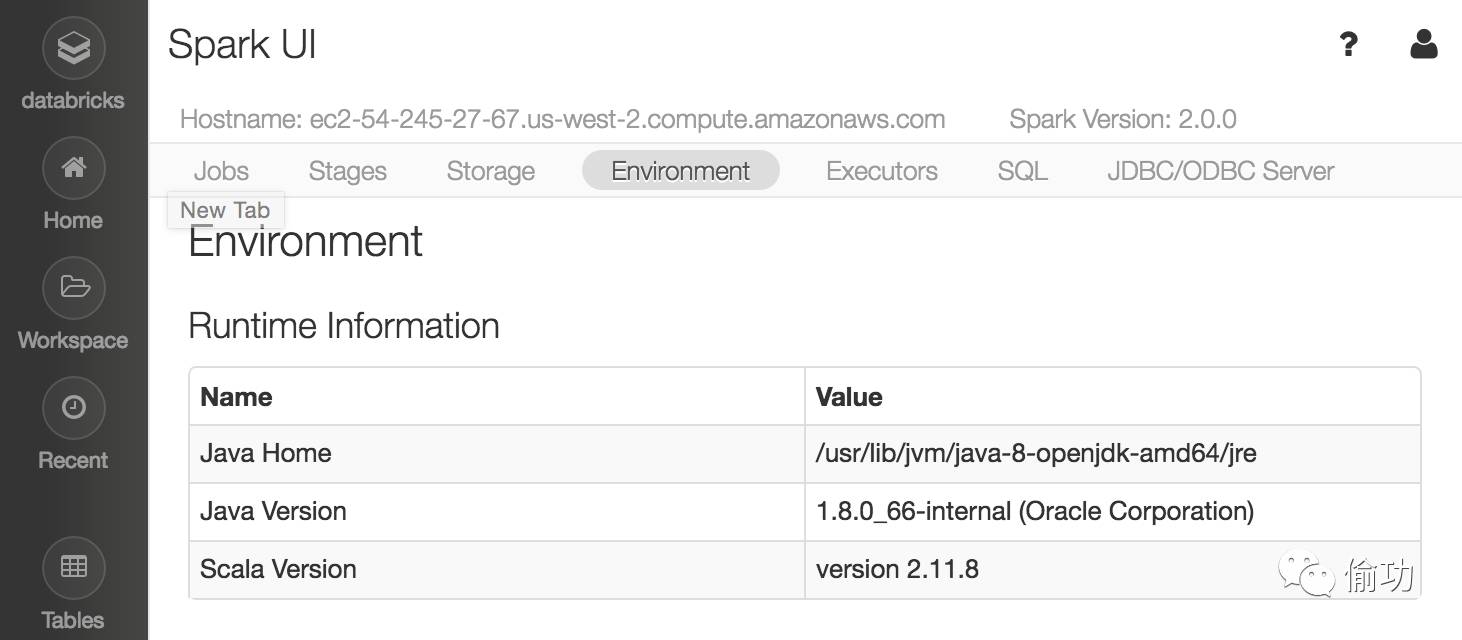
5. Intellij会创建一个信息的工程结构和一个构建文件build.sbt。打开该构建文件,如下所示:
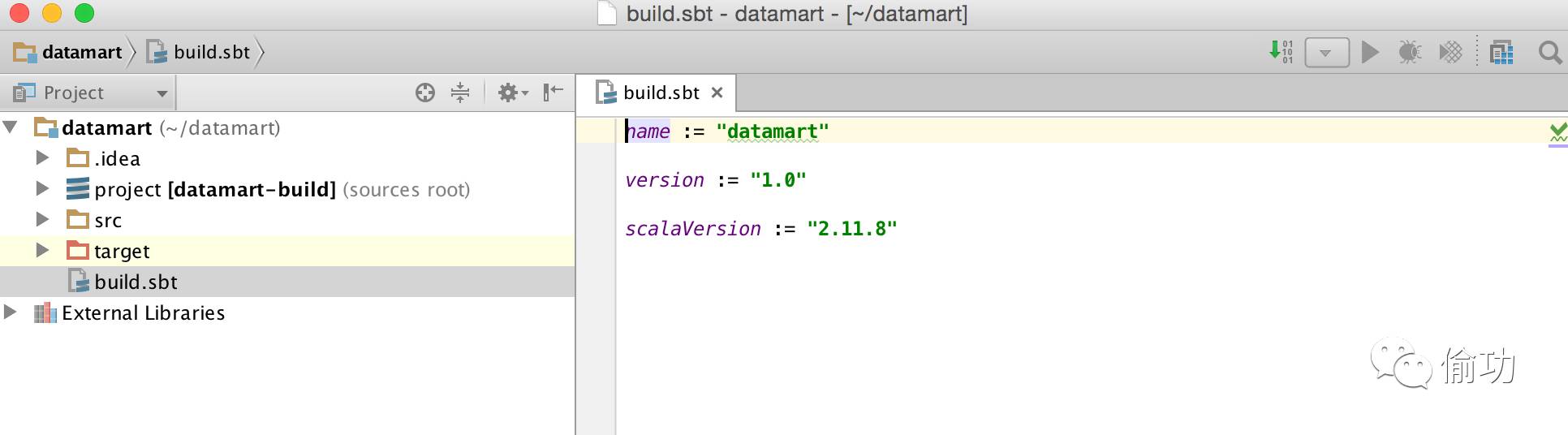
6. 下一步,为你的构建文件夹添加组织信息,添加Spark SQL的依赖类库。在添加Spark 类库时要确保使用%provided%。该选项是假设当你将你的JAR包 绑定到集群上时,在Databricks的classpath上已经有了该依赖类库,这样可以在编译为JAR时避免将该依赖类库打包进去。示例如下:
可以查看Maven仓库获取SBT的依赖类库信息。参考链接:https://mvnrepository.com/artifact/org.apache.spark/spark-sql_2.11/2.0.0
name := "datamart"
version := "1.0"
scalaVersion := "2.11.8"
organization := "com.databricks.blog"
libraryDependencies ++= Seq( "org.apache.spark" % "spark-sql_2.11" % "2.0.0" % "provided") |
4 以包(package)的形式重新组织原型代码
作者在编写原型时,类似于与单一职责一样,一个Notebook做一件事,这也便于测试。但在将这些打包成类库时,会将代码模块化到各个类和包中。作者创建了一个类DateDimension (source code)。
5 推送到Git 仓库
(Harli:Databricks提供的平台支持与Git仓库的交互,不过免费版本不支持…),这里介绍了将代码库推送到Git仓库之前需要设置.gitignore文件,以便用户指定包含和不包含的文件。(harli:这块内容参考git的参考文档就行)。案例:example .gitignore file
6 编译、打包类库
如果熟悉SBT的话,可以在工程根目录下,在命令终端运行 sbt package 命令。这将会在./target目录中构建一个JAR文件。
./target/scala-2.11/datamart_2.11-1.0.jar |
你可以在Databricks上用该JAR文件创建一个类库(Library),并绑定到一个集群,将包导入到一个Notebook然后使用。这些手动操作的步骤可以参考Databricks 平台的文档,下面会介绍如何将这些步骤自动化。
7 自动部署到Databricks
当你开始在Intellij中开发类库时,你会不断地迭代编码、上传到Databricks、通过Notebook重新测试这一过程。Databricks已经开发了一个SBT插件(SBT plugin)使该过程可以无缝结合。在配置后,你可以运行单个命令进行编译、上传、绑定类库到一个命名集群上,并重启该集群。如何安装该插件可以参考Databricks documentation.
8 创建Notebook并连接到GitHub
在类库绑定到Databricks上的一个集群后,作者创建了一个新的Notebook,可以在加载date dimension (时间维度)的调度Job中使用,参考 (see the notebook here)。
(harli :Databricks上可以构建Job,并对该Job进行调度)。
连接到Github 仓库:
最佳实践,将Notebook代码视作一个Apache Spark应用程序的一个入口点,并和打包到JAR中的源代码的位置隔离开来。作者的偏好位置,即将Notebook的代码放置于./src/main/notebook,相当于和./src/main/java或./src/main/scala平行,但同时不属于JAR打包所需的源代码路径。
使用内建的GitHub集成,可以很容易地同步Databricks和你仓库中的Notebook 。具体参考 GitHub Databricks Version Control Documentation。
9 使用单元测试
为确保类库的质量和可维护性,需要创建单元测试,并在每次构建的时候运行。作者利用了开源的spark-testing-base SBT插件来使代码更容易测试。利用该插件的步骤如下:
1. 在build.sbt文件中添加一个类库依赖项(libraryDependencies):
"com.holdenkarau" %% "spark-testing-base" % "2.0.0_0.4.7" % "test" |
2. 在build.sbt文件中添加一行:
parallelExecution in Test := false |
提供的版本依赖于你构建类库时所使用的Spark版本。在依赖后面添加的% “test” 是告诉SBT仅仅在测试时的classpath中包含该类库(harli:参考MVN的scope),而在最终构建的JAR包中不会包含该类库。需要注意的是该插件使用的ScalaTest版本可能会比你期望的更低。
spark-testing-base 插件的完整文档链接:
https://github.com/holdenk/spark-testing-base
3. 在和你的DateDimension 类相对应的/src/test路径中创建包结构和Scala测试类 (source code here):
4. 在项目的根目录下,可以在终端运行 sbt test 命令来执行测试。输出会类似于:
16/10/07 15:22:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 16/10/07 15:22:58 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect. [info] DateDimensionTest: [info] - test DateDimension default does NOT generate duplicate date_value [info] ScalaCheck [info] Passed: Total 0, Failed 0, Errors 0, Passed 0 [info] ScalaTest [info] Run completed in 5 seconds, 396 milliseconds. [info] Total number of tests run: 1 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0 [info] All tests passed. [info] Passed: Total 1, Failed 0, Errors 0, Passed 1 [success] Total time: 9 s, completed Oct 7, 2016 3:23:03 PM |
10 发布类库
编译、测试通过之后,就可以将snapshot版本正式发布了,发布的版本可以遵循SemanticVersioning。作者使用了sbt-release 插件更好的管理类库的版本发布。步骤如下:
1. 在project/plugins.sbt文件中添加一行:
addSbtPlugin("com.github.gseitz" % "sbt-release" % "1.0.3") |
2. 在工程根目录下创建version.sbt 文件,并添加:
version := "0.1.0-SNAPSHOT" |
3. 从build.sbt文件中移除一样的版本赋值语句。
在sbt-release插件构建一个发布版本之前,首先需要一个build.sbt 文件,通过设置publishTo变量来发布到仓库。
SBT使用publish 动作上传编译后JAR到工件仓库(artifact repository),可以在publishing with SBT at this link查看完整文档。
如果没有工件仓库的话,也可以通过在build.sbt 文件中添加以下代码,将构建好的JAR发布到本地的Maven仓库中:
publishTo := Some(Resolver.file("file", new File(Path.userHome.absolutePath+"/.m2/repository"))) |
sbt-release插件执行一系列的检查并要求所有的修改都要在检查通过后才能提交、推送到git上的远程跟踪分支。
新建一个发布版本,在工程根目录下运行sbt release命令即可。
sbt-release插件会提示首先指定发布版本为[0.1.0],然后指定下一个开发版本为[0.1.1-SNAPSHOT]。你可以直接回车使用默认版本,也可以自己指定版本。
插件可以编辑、打包、运行单元测试,更新版本号,并要求将修改内容提交和推送到git。如果成功的话,你可以看到versions.sbt文件中的版本号已经更新为新版本号,分支也会以当前版本标识,并且所有的提交都会推送到远程跟踪分支。
11 下一步
本博客介绍构建spark类库的步骤。首先在Databricks的Notebook上构建原型。这些代码拷贝到本地Intellij工程上并为其编写单元测试。利用一些SBT插件来自动化Databricks部署,运行单元测试,以及发布类库版本。创建一个Databricks Notebook,导入类库,并作为一个Job进行调度。内建的GitHub集成可以将该Notebook提交到类库源码所在的Git仓库中。
Databricks提供的免费版本或联系方式:sign-upfor a free trial 或 contact us。
