




引言
开发Web应用时,相信很多读者经常要加上搜索功能。甚至还不知能要搜什么,就在草图上画了一个放大镜。
搜索是项非常重要的功能,所以你可能需要来点轻量级的,但又足够好的搜索工具。今天我们来探讨一下PostgreSQL如何实现全文检索。
一、需求
临时接到一个需求,需要从数据库(多个分表)中,根据输入的关键词模糊查询出对应的记录。
和产品明确需求后,具体是这样的:合作公司会定时同步数据到指定的表中,并按时间戳进行分表,5至7天会生成一张新表,每张表的数量大概在500万-1000万行左右,数据库使用的是PostgreSQL,现在需要按照时间范围和输入的关键词到text列中进行模糊搜索,并将匹配的搜索结果分页返回。
二、过程
基于以上的需求,想到了两种方案:
1、直接使用like查询
2、同步ElasticSearch
先看第一个方案,直接对text列进行like查询,需求要求是两边匹配,即%{查询内容}%,而不是左匹配,所以text列的索引是无效的,在navicat上试着查了下,500万左右的like查询大概需要10-15秒左右,这样的方案显然无法满足业务需求,直接否定掉。
再看下同步ElasticSearch的方案,最初的想法是单独写一个Job服务,按一定周期(比如每1分钟)轮询每张表,将产生的新记录同步至ElasticSearch,用ElasticSearch做全文检索。此方法能彻底解决需求,并能支持各种维度查询,为以后留下很大扩展余地,但相应地,实现的复杂度和开发成本也会增加很多。
那还有没有更加简单的方案呢?我们将目光转移回到PostgreSQL数据库上,说句实话,以前只听说过PostgreSQL,但并没有实践过,也不清楚这种数据库的特性。作为开发,遇到问题的时候一般都会百度,这里也不例外,话不多说,先百度下,果然搜到了,如下图:
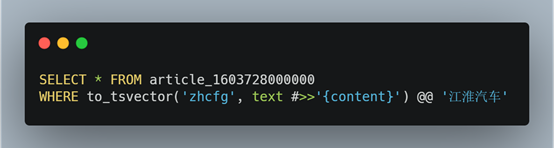
点了几篇文章阅读后,大概了解了PostgreSQL的一些特性,这个数据库虽然是关系型数据库,但它也支持一些文档数据库(NoSQL)的特性,同时也支持全文检索!经过一番折腾和试错,终于完成了需求,最终的成果只有下面的一句SQL,但它可以将原本两到三天的工作量减少至30分钟,查询速度也很快,单表五百万的数据量下进行模糊查询且union多张表,大概在50毫秒左右,SQL如下:
三、分析
至此,我们根据上面的SQL做一些分页和其他业务整合,很快完成了需求,但还是有必要对上面的SQL进行一些说明。
首先,将上图的SQL中可能不明白的两个地方抽出来,即:to_tsvector('zhcfg', text #>>'{content}')、@@ '江淮汽车',接下来,我们对其说明。
1、to_tsvector('zhcfg', text#>>'{content}')
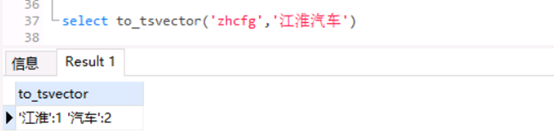
在PostgreSQL中,原始内容在被构建索引之前需要进行向量化,向量化后的内容才能进行全文检索,且字段的类型变为tsvector,PostgreSQL中提供了to_tsvector函数进行文本向量化,tsvector类型是由元组(词、词序)组成的列表,对“江淮汽车”进行向量化即得到两个元组,如下:
‘zhcfg’是分词器的名称,PostgreSQL目前并不支持中文分词,如果需要对中文分词,则需要安装中文分词器,现在最流行的是zhparser,安装过程如下:
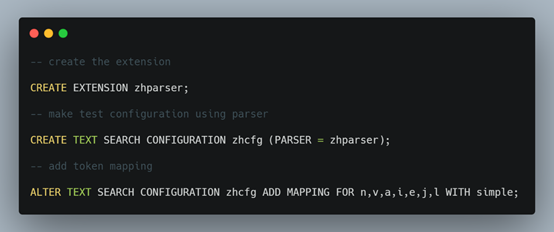
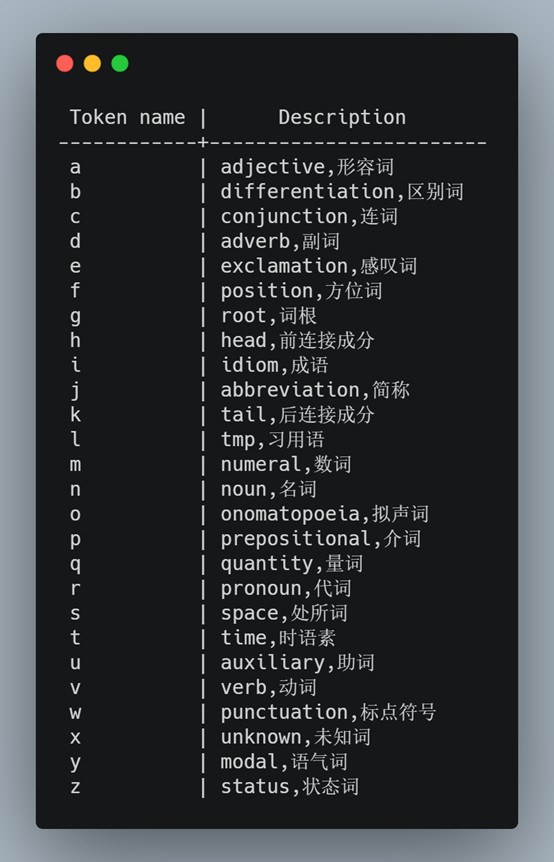
最后一句中n,v,a,i,e,j,l几个字母分别表示一种token策略,即分词策略,其代表含义如下:
text #>>'{content}'是对jsonb字段类型的访问方式,jsonb是PostgreSQL的一种数据类型,用于存储json格式的数据,#>>是用来访问json中某个字段。在我们需求中,text字段的格式为:{"content":"我喜欢江淮汽车,真心不错!"},所以要对text中content进行操作就可以写为:text #>>'{content}'。
2、@@ '江淮汽车'
对原始内容进行向量化以后,我们需要对tsvector类型的字段(或创建一个新字段)进行索引,在PostgreSQL中有两种索引类型,分别为gin和gist,一般推荐使用gin,gin索引查询速度优于gist,但创建过程比较慢,且索引占用的磁盘量比较高。创建语句如下:
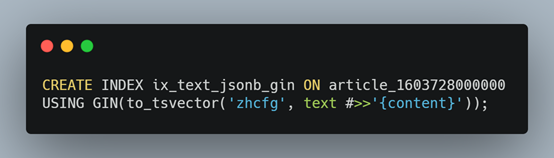
创建索引以后,就可以对这个字段进行全文检索了。@@表示对向量化后的元组结果进行查询,后面是查询的内容,我们现在是已经明确查询内容,所以可以直接使用这种写法,即@@ ‘江淮汽车’,如果你想实现复杂的查询,可以使用to_tsquery函数,to_tsquery函数将搜索词组织成tsquery向量,然后通过向量去搜索,比如查询内容中同时出现“江淮”和“汽车”的记录,可以像下面这样写:

如果要查询内容中出现“江淮”或“汽车”的记录,可以像下面这样写:

最后简单介绍一下什么是倒排索引,假如有下面一张记录表:
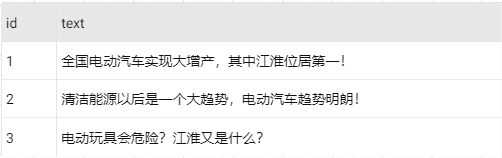
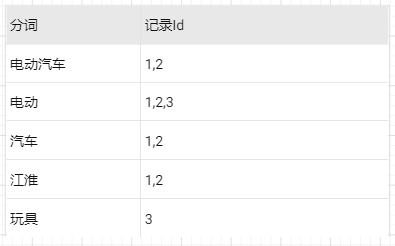
对text字段建立倒排索引如下,大家一看就明白,就不多说了。
四、PostgreSQL vs MySQL
PostgreSQL声称是最先进的数据库,除了传统的当关系型数据库使用外,它还可以当缓存、消息队列、文档数据库(NoSQL)、地理数据库、空间数据库、时序数据库、图数据库、全文检索等,原来需要很多组件才能实现的功能,使用PostgreSQL基本全部能够支持。MySQL声称是最流行的数据库,相对PostgreSQL的丰富功能,MySQL强调的是简单易用。
如果搭建一个新项目时该如何选型呢?
从应用场景来选的话,PostgreSQL更适合企业应用场景,比如ERP、CRM、金融、财务等,MySQL更加适合逻辑相对简单、数据要求比较彽的互联网场景。
从技术方面来选的话,MySQL在国内流行了很多年,比如说之前都是MySQL和SqlServer的比较,很少有人提及PostgreSQL。相对来说,技术人员对MySQL的熟悉程度远远超过PostgreSQL,踩过的坑也比PostgreSQL多很多。
从运维方面来选的话,MySQL也比PostgreSQL维护起来更简单,且有很多成熟的解决方案。参考下图:
基于以上比较,一般的应用还是选择MySQL比较靠谱,毕竟MySQL现在已经成为业界标准,不管做什么业务,MySQL都是第一选择,跳槽跳来跳去的开发也对MySQL最熟悉。但如果需要解决一些比较小众的业务需求,则可以考虑使用PostgreSQL做为辅助。其实怎么选,还是要看业务需求和实现场景。
五、总结
PostgreSQL可以实现小规模数据量的全文检索功能,当你有千万级别数据量全文搜索的需求时,又不想搭建ElasticSearch这样的重量级搜索服务器,可以考虑使用PostgreSQL。
最后再回顾下PostgreSQL全文检索使用过程:
安装中文分词器,比如zhparser、pg_jieba
使用to_tsvector函数对查询列进行向量化,类型为tsvector,然后对字段创建gin索引
使用to_tsquery对搜索关键字进行向量化,类型为tsquery,使用@@对tsvector字段检索
参考资料
https://www.postgresql.org/docs/current/textsearch.html
http://www.postgres.cn/docs/9.4/textsearch-indexes.html
https://www.imooc.com/wiki/sqlbase/sqlpractice6.html
还有一件事


