




概述
Join Reorder是数据库优化领域中最为经典备受关注的问题。Join Reorder的问题可以描述为给定一条多表Join的SQL,输出一个最优的Join顺序,使得查询性能最优。在不同的数据库实现中Join Reorder的具体算法各有不同,本文会总结各种流行数据库中Join Reorder的实现方式及其优劣势,最后引出PolarDB-X基于规则变换的Join Reorder实现算法及其背后的思考。
基本概念
我们以TPCH Q9作为例子阐述一下理解Join Reorder的基本概念,它是一条6表Join的SQL
SELECT nation, o_year, sum(amount) AS sum_profit FROM (SELECT n_name AS nation, extract(YEAR FROM o_orderdate) AS o_year, l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity AS amount FROM part, supplier, lineitem, partsupp, orders, nation WHERE s_suppkey = l_suppkey AND ps_suppkey = l_suppkey AND ps_partkey = l_partkey AND p_partkey = l_partkey AND o_orderkey = l_orderkey AND s_nationkey = n_nationkey AND p_name LIKE '%green%') AS profit GROUP BY nation, o_year ORDER BY nation, o_year DESC;复制
Query Graph
Query Graph是个无向图,其中图上每个节点代表每一张表,节点间的边代表两张表有Join连接。
一般多表Join的SQL查询可以根据Query Graph的形状归类为链式Join,星型Join,全连接Join等等。
TPCH Q9的Query Graph如下:

Join Tree
基本上数据库实现一个Join算法的时候只会实现两个输入的情况。Join Tree是一棵二叉树,其中树上的叶子节点代表需要被连接的表,非叶子节点代表Join算子。
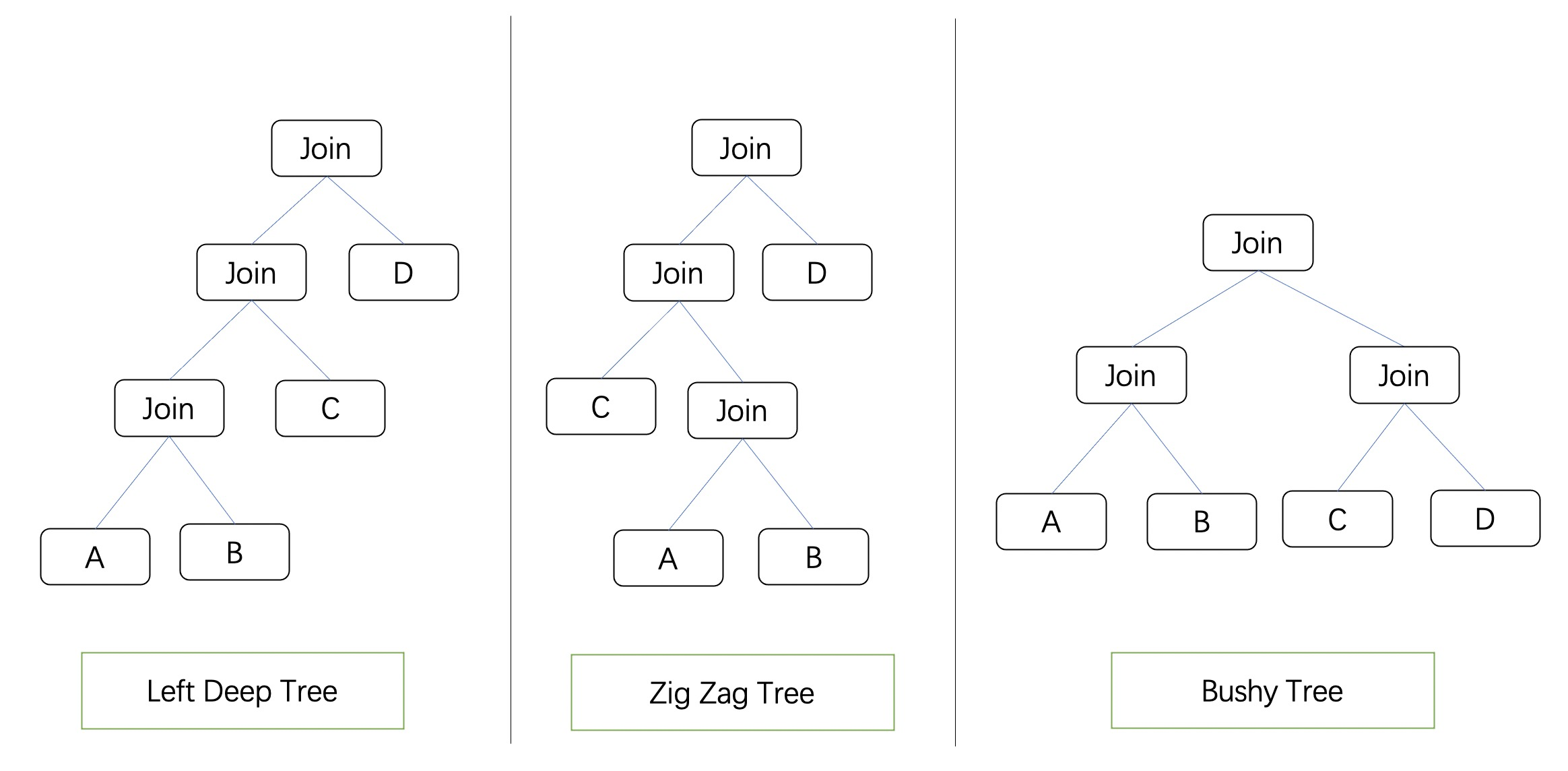
根据Join Tree的形状,我们可以将其归类为Left Deep Tree, ZigZag Tree, Bushy Tree。
Left Deep Tree,就是大名鼎鼎的左深树,Join节点的右侧只能是一个叶子节点,很多数据库都会默认将左深树作为Join Reorder的搜索空间。
ZigZag Tree,可以理解为左深树的基础上可以进行左右节点的交换。
Bushy Tree,结构最为自由,表可以按照任意顺序Join。

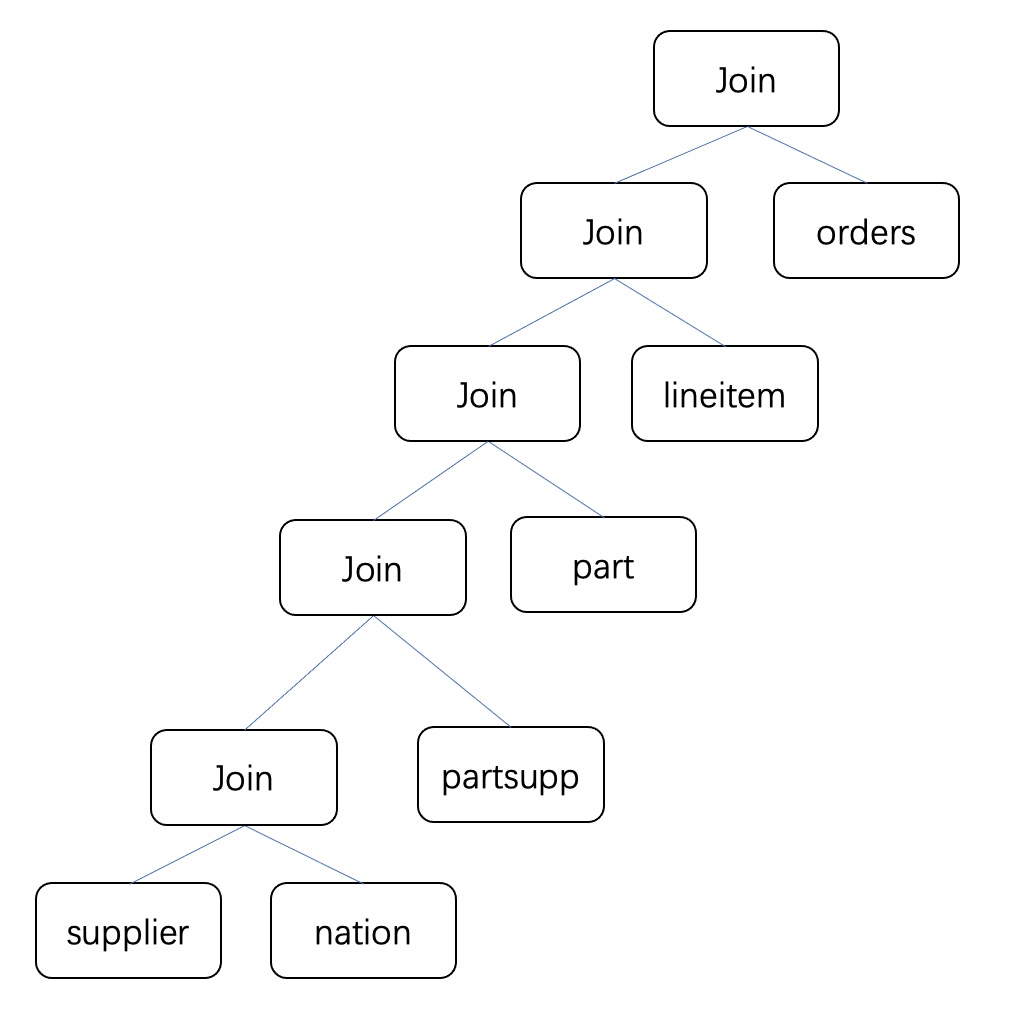
不同的Join Reorder算法会生成不一样的Join Tree,Join Tree刻画了每个表之间具体按照什么顺序做Join。
其中TPCH Q9的一种可能Join Tree形状如下:

Join Cardinality
Join Cardinality代表Join算子输出中间结果集的大小,它是所有Join Reorder算法进行顺序选择的重要依据。直观来看Join输出的中间结果集越小,越有利于后续Join的执行性能。
单个表大小很好估算,可以通过表的行数和每行的平均长度估算出。表上有过滤条件可以通过直方图或Sketch等方法估算出过滤后的行数。
而Join中间结果集的行数估算一般采用以下公式:
LeftRowCount * RightRowCount / MAX(LeftCardinality, RightCardinality)复制
其中LeftRowCount,RightRowCount分别代表Join左和右输入的行数,LeftCardinality代表左输入Join列的NDV(Number Of Distinct Value)值,RightCardinality同理。特别的,没有Join条件的Cross Join结果行数为LeftRowCount * RightRowCount。
Join Cost
数据库实现中,不同的Join算法一般都会有多种实现,场景的Join算法有NestedLoop Join, Index NestedLoop Join, Hash Join,Sort Merge Join。不同的Join算法会有对应的代价,以CPU代价De为例:
HashJoin的执行代价
CPU代价 = Probe权重 * Probe端数据量 + Build权重 * Build端数据量复制
Nested Loop Join的执行代价
CPU代价 = Join权重 * 左端数据量 * 右端数据量复制
Sort Merge Join的执行代价
CPU代价 = 左端输入数据排序代价 + 右端输入排序代价 + Merge代价复制
常见Join Reorder算法
常见的Join Reorder算法可以分为:
- 贪心启发式算法,因为速度很快,此类算法适合Join数目较多的情况。
- 全枚举算法,适合Join数目较少的情况。
一般数据库都会根据Join数目,使用这两大类的算法在优化时间和搜索空间大小上取得平衡。
单序列贪心启发式Join Reorder算法
从一张表逐渐到N张表,贪心地选出使得当前Join输出RowCount最小的表加入。按照选出的表序列构建出左深树。[1]
算法流程
搜索空间为左深树,假定输入为N张表,从一张表逐渐到N张表构建出完整的JoinOrder
- 首先第1层计算出每张表的RowCount
- 第2层从第1层中选出RowCount最小的表,Join其它N-1张表,计算出每两个Join的输出RowCount
- 第K层从第K-1层中选出RowCount最小的Join,Join其它N-K+1张表,计算出K张表Join的输出RowCount
- 当K=N时,算法结束
这类算法有一个缺点是贪心地选择第一张表会对整个Join Order有较大的影响,容易陷入局部最优解。
采用此Join Reorder算法的数据库有TiDB。
多序列贪心启发式Join Reorder算法
多序列贪心启发式左深树Join Reorder算法[1]:(算法支持SemiJoin,Outer Join,为了算法简洁下面只考虑InnerJoin)
Idea为对于输入的N张表,可以启发式生成N个Join顺序(每个序列的第一张表都不一样)构造成左深树,比较N个Join顺序的Cost,选择最好的一个。下面以N = 5为例,启发式生成5个顺序,选择Cost最低的一个。
[1,4,5,2,3]
[2,5,1,3,4]
[3,1,5,2,4]
[4,5,3,1,4]
[5,3,2,1,4]
算法流程
假定输入为N张表的inner join
- 设置权重Weight[i][j],其中i为第i张表,j为第j张表。权重越大,这两张表应该越先Join。
Weight[i][j] = 3,如果i,j存在等值join条件
Weight[i][j] = 2,如果i,j存在非等值join条件(>, >=, <, <=, !=)
Weight[i][j] = 1, 其它情况(i和j可能是笛卡尔集)
- 假定序列第一张表为X,第二张表Y选取规则如下
- 优先考虑Weight[X][Y]大的Y
- 如果Weight值相等,则考虑Y Join X中Y的Join条件所对应列的Cardinality值,Cardinality越大越优先考虑。(PS:Cardinality越大Join的结果集越小)
- 第K张表的选择如此类推
- 最终N张表按照上述选择顺序构造出左深树
- 选择Cost最低的一个Join顺序
注意到多序列的贪心启发式Join Reorder算法是有考虑多个Join序列,并选择出Cost最小的序列。这里的Cost可以是任何自定义的代价。
采用此Join Reorder算法的系统有Flink和Drill。
GOO算法
GOO(Greedy Operator Ordering)[1]
- 针对上面贪心启发式只能构造左深树的场景,GOO可以构造出BushyTree。
- 贪心启发式算法只考虑了JoinTree和一张表做Join。GOO则考虑了JoinTree和JoinTree可以做Join
算法流程
假定输入N张表
令T = N张表的集合
- while |T| > 1
a. 找到T中两个JoinTree, T[i]和T[j]使得它们的Join结果集最小
b. T = (T \ T[i] \ T[j])
c. T = T U {T[i] join T[j]}
- 最终T中唯一元素就是Bushy Tree空间上贪心搜到的JoinOrder
遗传算法(GEQO)
PostgreSQL在表数目较多(>= 12)情况下采用的Genetic Query Optimization (GEQO) 算法
假定输入N张表
- 每张表可以看作一个基因
- N个不同基因组成一条染色体
- 因此Join Reorder可以看成是找到最优秀的染色体(代价最低)
模拟基因遗传的特点,选择父染色体和母染色体,交换部分片段生成孩子染色体。淘汰不优秀的染色体,在优秀的染色体中迭代若干代,得到一个Order。
算法流程
假定输入为N张表,初始化染色体池大小为PoolSize。以及染色体迭代次数generation。(默认为2^(N-1))
- 随机生成PoolSize个有效的染色体.(例如可以限定某些条件)
- 给染色体池子按照染色体的优秀程度排序
- 开始迭代第1,2,..k,...generation轮
- 先从染色体池子按照特定分布取出两条染色作为父和母染色体(这个分布的概率会偏向选择优秀的染色体)
- 父和母染色体采取一定的重组策略生成孩子染色体。(重组策略有很多种,最简单的是随机取父染色体的一段连续基因片段,之后按照母染色体顺序添加缺失的基因)
- 将孩子染色体放入染色体池中,并淘汰最差的染色体
- 染色体的优秀程度通过将染色体构造成Join树后通过CBO评估出代价,代价越低越优秀
- 持续迭代至要求的迭代次数,选择出池子中最优秀的基因构建出Join,这里的Join一般是LeftDeep的。(PG做了Bushy)
遗传算法有一个缺点是每次结果执行计划会不一样导致性能不稳定,这对于追求每次查询结果性能稳定的场景来说是比较糟糕的。
深度优先枚举Join Reorder算法
Mysql数据库诞生至今已经二十多年,作为一个面向OLTP的数据库,它的Join Reorder是Left Deep Tree枚举算法。其中Join Reorder会考虑索引来使用Index NestedLoop Join。
算法流程
- 表 <= 7时,完全遍历,搜索空间为Left Deep Tree,深度优先遍Join每个顺序(N!复杂度)。考虑每一个序列的代价。
- 表 >7时,通过遍历的深度控制搜索空间。
- Join Reorder同时考虑AccessPath索引选择
- 索引选择先通过规则匹配出完全匹配主键、唯一键的等值条件。最后再通过cost比较其它未完全匹配的索引及全表扫描。
Bottom-Up枚举的Join Reorder算法
Bottom-Up枚举的Join Reorder算法采用了动态规划的技术,可以避免了中间结果的重复计算,可枚举Bushy Tree空间。
下面采用CCP(csg-cmp-pair)概念来描述算法[3]。
假定输入N张表,且Query Graph是连通的。
对于N张表组成的集合S
定义CCP(S1, S2):
- S1是Query Graph上的连通子图
- S2是Query Graph上的连通子图
- S1和S2无交集
- S1和S2之间存在边
我们可以从1张表到N张表显式遍历CCP逐步找到BestPlan。
PS:CCP的数目和Query Graph的形状是有关系的,例如全连接的Query Graph的CCP数目就会大于星型的Query Graph,而链式的Query Graph的CCP数目会更少
算法流程
- 初始化单表R的BestPlan(R) = R
- (自底向上)遍历每个CCP(S1,S2),S = S1 U S2 (有不同的遍历策略[3]可以有DPsize,DPsub等,最好的策略是无Duplicate的DPccp)
- 计算出S1,S2的BestPlan p1 = BestPlan(S1),p2 = BestPlan(S2),当S1是一张表时,选择该表的最优的AccessPath
- CurrPlan = CreateJoinTree(p1,p2),根据已有的Join算法,生成不同的Join来连接p1,p2两个子执行计划。
- BestPlan(S) = minCost(CurrPlan,BestPlan(S) )
- 最终获取BestPlan(N张表)即是BushyTree空间上最优的JoinOrder
Bottom-Up枚举的Join Reorder算法可以有效处理Bushy Tree空间枚举的问题,并能够利用动态规划来解决中间结果重复计算的问题。而这类算法只能够处理Join Reorder这一特定问题,如果希望在Join Reorder过程中再加入更多的优化获取全局最优解,例如Agg和Join的Transpose,这类算法就做不到。
采用此类算法的数据库有PostgreSQL,OceanBase,Oracle。
基于规则变换Top-Down枚举的Join Reorder算法
基于规则变换Join Reorder算法是需要配合Top-Down的Cascades优化框架来实现[4]的。关于PolarDB-X优化器中的Cascades框架的介绍,可以参考PolarDB-X CBO 优化器技术内幕
Join Reorder通过一系列的Join转换规则实现。计划空间搜索引擎将Join规则应用直到动态规划求解完成,此时规则对应的Join(顺序)空间也就遍历完成。可以看出一组Join Reorder规则会对应一个Join空间,而不同的Join Reorder规则对应不同的Join空间。
Join Reorder规则支持多种Join类型的Reorder,包括Inner/Outer/Semi/Anti Join。这些Join Reorder的规则已经有论文[5][6]归纳出(如下图),e代表table、a与b代表Join、p代表Join条件。下面表格主要描述了两个不同类型的Join之间可以作转换的情况(assoc、l-asscom、r-asscom)。另外还有一个只适用于Inner Join的Join交换律(comm),即左右表交换。

不同的规则集合对应不同的搜索空间:
Left Deep Tree:
bottom comm规则 : A⨝B → B⨝A, 只应用于左深树的最底下两表
l-asscom规则: (A⨝B)⨝C → (A⨝C)⨝B
Zig-Zag Tree:
comm规则 : A⨝B → B⨝A
l-asscom规则 : (A⨝B)⨝C → (A⨝C)⨝B
Bushy Tree:
comm规则 : A⨝B → B⨝A
assoc规则: (A⨝B)⨝C → A⨝(B⨝C)
直观地来看通过交换律和结合律就能够枚举整个Bushy Tree的搜索空间。
这类算法的优点是可以利用Cascades引擎Top-Down动态规划的过程中通过Branch and Bound进行空间剪枝,同时通过物理属性驱动搜索的方式更加优雅高效地处理Interesting Order问题。还有可以将Join Reorder的优化规则和其他任何类型的优化规则放入Cascades搜索引擎中获得全局最优解。
采用此类算法的数据库有SQL Server, CockroachDB, PolarDB-X
PolarDB-X Join Reorder算法
PolarDB-X采用的Join Reorder算法为基于规则变换Top-Down的Join Reorder算法。
Duplicate Free Join Reorder Rule Set
PolarDB-X为了提升优化效率会采用Duplicate-Free的Join Reorder规则[7][8], Duplicate-Free意味着这组规则不存在generate duplicate的情况,并且可以遍历同样完整的空间。核心思路就是通过记录算子转换的“历史路径信息”,从而避免generate duplicate
下面给出两个空间的Duplicate-Free规则集合
Left Deep Tree:
Rule1 (l-asscom) : (A⨝0B)⨝1C → (A⨝2C)⨝3B , Rule1不能再次作用于⨝3
Rule2 (comm) : A⨝0B → B⨝1A,Rule2不能再以作用于⨝1
Bushy Tree:
Rule1 (comm): A⨝0B → B⨝1A, Rule1,2,3,4均不在再次作用于⨝1
Rule2 (r-assoc): (A⨝0B)⨝1C → A⨝2(B⨝3C), Rule2,3,4均不在再次作用于⨝2
Rule3 (l-assoc): A⨝0(B⨝1C) → (A⨝2B)⨝3C , Rule2,3,4均不在再次作用于⨝3
Rule4 (exchange): (A⨝0B)⨝1(C⨝2D) → (A⨝3C)⨝4(B⨝5D) , Rule1,2,3,4均不在再次作用于⨝4
可以看见Duplicate-Free规则因为记录了“历史路径信息”导致变得复杂,“历史路径信息”实际编码在了Join算子里面,每次转换Join算子会更改对应的信息。每次规则匹配也需要检查额外条件。Zig-Zag Tree可以对Left Deep Tree的思路类似给出。
Adaptive Search Space
搜索空间大小:Bushy Tree > Zig-Zag Tree > Left Deep Tree
搜索空间越大或Join越多,优化搜索时间就越久,为了让优化时间维持在一定时间以内,PolardB-X采用了Adaptive Search Space,即根据Join的目决定搜索空间的大小。
表数目 | 搜索空间 |
<= 4 | Bushy Tree |
<= 6 | Zig-Zag Tree |
<= 8 | Left Deep Tree |
>=9 | Heuristic |
在表数>=9个的时候,PolarDB-X会采用多序列贪心启发式Join Reorder算法加速Join Reorder的过程。
Join Reorder与其他规则
PolarDB-X的Join Reorder会和其他关键的优化规则一起组成更大的搜索空间并获取全局最优解。
Join算法规则
Join的顺序选择和具体的Join算子物理算法息息相关,因为不同的Join算子物理算法会有不同的代价。目前PolarDB-X支持HashJoin, Sort Merge Join, NestedLoop Join, BKA Join(分布式的Index Nested Join)。Join算法规则会和Join Reorder规则一起构成搜索空间。
Join下推规则
因为PolarDB-X支持Join下推,因此Join的下推规则会和Join Reorder规则一起构成搜索空间。
Agg与Join交换规则
因为Agg和Join的交换有机会大大减少Join处理的数据量[9],因此这类规则也会和Join Reorder规则一起构成搜索空间。
索引选择规则
因为PolarDB-X支持全局二级索引,不同的全局二级索引会影响Join的下推和Join算法规则,因此这类规则也会和Join Reorder规则一起构成搜索空间。
Branch And Bound空间剪枝
空间剪枝是Top-Down动态规划中非常棒的一个特性,它可以保证剪枝完后的空间也一定能够找到最优解。这是相对于Bottom-Up动态规划的重要优势。以三表Join为例子来看如何进行空间剪枝。

ABC的三表Join如果按照最开始的顺序优化出来了A、B、C依次使用Index Nested Loop Join,计算出代价值例如是10,之后通过Join Reorder的规则构造出了B Join C但是我们看到B Join C的最低代价也要1000, 因为是两张大表做Join,既然[ABC]等价集合中已经有了一个代价为10的执行计划。那么可以直接裁剪掉[BC]不再去为它们生成物理执行计划,因为它们无论选择什么物理执行计划都不会比10低。这就是Branch And Bound空间剪枝。
这里规则的应用顺序可以看出如果从上到下应用物理转换规则那我们有机会做到剪枝,不需要去搜索部分空间。一般来说会通过特定的启发式方法来指导搜索引擎应用物理转化规则,尽快找到一个代价低的执行计划,并利用其代价去进行空间剪枝。
总结
本文总结了数据库领域中常见的Join Reorder算法,包含:
Join Reorder算法 | 默认使用的数据库 | INFO |
单序列贪心启发式Join Reorder算法 | TiDB | Left Deep Tree |
多序列贪心启发式Join Reorder算法 | Flink, Drill, PolarDB-X | Left Deep Tree,可以比较N个Join序列,选出代价较低的 |
遗传算法 | PostgreSQL | 只有表数目大于12张时候才会开启,每次Join顺序不稳定 |
深度优先枚举Join Reorder算法 | MySQL | Left Deep Tree,表数目<=7张算法复杂度为N!,没有利用动态规划 |
Bottom-Up枚举的Join Reorder算法 | PostgreSQL, OceanBase | Bottom Up动态规划枚举Left Deep Tree或Bushy Join Tree搜索空间 |
基于规则变换Top-Down枚举的Join Reorder算法 | PolarDB-X, SQLServer, CockroachDB | TopDown动态规划枚举Left Deep Tree或Bushy Join Tree, 可以做空间剪枝,与其他优化规则一起混合做全局优化 |
PolarDB-X在表数据较多时(>=9)采用多序列贪心启发式Join Reorder算法。
PolarDB-X在表数目较少时(<9)采用基于规则变换的Top-Down的Join Reorder算法,它有如下的优点
- 使用了Duplicate Free的Join Reorder规则提升Reorder效率
- 通过Adaptive Search Space来控制搜索空间大小
- 通过Join Reorder规则和Join算法规则、Join下推规则、Agg与Join交换规则、索引选择规则一起构建搜索空间,获取全局最优解。
- 利用Top-Down搜索进行空间剪枝。
参考文献
概述
Join Reorder是数据库优化领域中最为经典备受关注的问题。Join Reorder的问题可以描述为给定一条多表Join的SQL,输出一个最优的Join顺序,使得查询性能最优。在不同的数据库实现中Join Reorder的具体算法各有不同,本文会总结各种流行数据库中Join Reorder的实现方式及其优劣势,最后引出PolarDB-X基于规则变换的Join Reorder实现算法及其背后的思考。
基本概念
我们以TPCH Q9作为例子阐述一下理解Join Reorder的基本概念,它是一条6表Join的SQL
SELECT nation, o_year, sum(amount) AS sum_profit FROM (SELECT n_name AS nation, extract(YEAR FROM o_orderdate) AS o_year, l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity AS amount FROM part, supplier, lineitem, partsupp, orders, nation WHERE s_suppkey = l_suppkey AND ps_suppkey = l_suppkey AND ps_partkey = l_partkey AND p_partkey = l_partkey AND o_orderkey = l_orderkey AND s_nationkey = n_nationkey AND p_name LIKE '%green%') AS profit GROUP BY nation, o_year ORDER BY nation, o_year DESC;复制
Query Graph
Query Graph是个无向图,其中图上每个节点代表每一张表,节点间的边代表两张表有Join连接。
一般多表Join的SQL查询可以根据Query Graph的形状归类为链式Join,星型Join,全连接Join等等。
TPCH Q9的Query Graph如下:
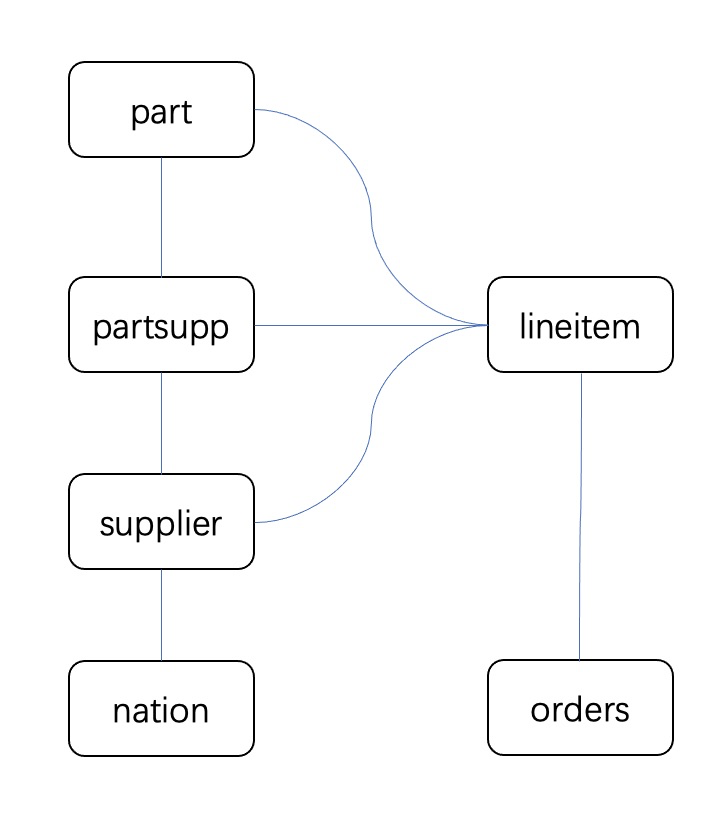
Join Tree
基本上数据库实现一个Join算法的时候只会实现两个输入的情况。Join Tree是一棵二叉树,其中树上的叶子节点代表需要被连接的表,非叶子节点代表Join算子。
根据Join Tree的形状,我们可以将其归类为Left Deep Tree, ZigZag Tree, Bushy Tree。
Left Deep Tree,就是大名鼎鼎的左深树,Join节点的右侧只能是一个叶子节点,很多数据库都会默认将左深树作为Join Reorder的搜索空间。
ZigZag Tree,可以理解为左深树的基础上可以进行左右节点的交换。
Bushy Tree,结构最为自由,表可以按照任意顺序Join。
不同的Join Reorder算法会生成不一样的Join Tree,Join Tree刻画了每个表之间具体按照什么顺序做Join。
其中TPCH Q9的一种可能Join Tree形状如下:
Join Cardinality
Join Cardinality代表Join算子输出中间结果集的大小,它是所有Join Reorder算法进行顺序选择的重要依据。直观来看Join输出的中间结果集越小,越有利于后续Join的执行性能。
单个表大小很好估算,可以通过表的行数和每行的平均长度估算出。表上有过滤条件可以通过直方图或Sketch等方法估算出过滤后的行数。
而Join中间结果集的行数估算一般采用以下公式:
LeftRowCount * RightRowCount / MAX(LeftCardinality, RightCardinality)复制
其中LeftRowCount,RightRowCount分别代表Join左和右输入的行数,LeftCardinality代表左输入Join列的NDV(Number Of Distinct Value)值,RightCardinality同理。特别的,没有Join条件的Cross Join结果行数为LeftRowCount * RightRowCount。
Join Cost
数据库实现中,不同的Join算法一般都会有多种实现,场景的Join算法有NestedLoop Join, Index NestedLoop Join, Hash Join,Sort Merge Join。不同的Join算法会有对应的代价,以CPU代价De为例:
HashJoin的执行代价
CPU代价 = Probe权重 * Probe端数据量 + Build权重 * Build端数据量复制
Nested Loop Join的执行代价
CPU代价 = Join权重 * 左端数据量 * 右端数据量复制
Sort Merge Join的执行代价
CPU代价 = 左端输入数据排序代价 + 右端输入排序代价 + Merge代价复制
常见Join Reorder算法
常见的Join Reorder算法可以分为:
- 贪心启发式算法,因为速度很快,此类算法适合Join数目较多的情况。
- 全枚举算法,适合Join数目较少的情况。
一般数据库都会根据Join数目,使用这两大类的算法在优化时间和搜索空间大小上取得平衡。
单序列贪心启发式Join Reorder算法
从一张表逐渐到N张表,贪心地选出使得当前Join输出RowCount最小的表加入。按照选出的表序列构建出左深树。[1]
算法流程
搜索空间为左深树,假定输入为N张表,从一张表逐渐到N张表构建出完整的JoinOrder
- 首先第1层计算出每张表的RowCount
- 第2层从第1层中选出RowCount最小的表,Join其它N-1张表,计算出每两个Join的输出RowCount
- 第K层从第K-1层中选出RowCount最小的Join,Join其它N-K+1张表,计算出K张表Join的输出RowCount
- 当K=N时,算法结束
这类算法有一个缺点是贪心地选择第一张表会对整个Join Order有较大的影响,容易陷入局部最优解。
采用此Join Reorder算法的数据库有TiDB。
多序列贪心启发式Join Reorder算法
多序列贪心启发式左深树Join Reorder算法[1]:(算法支持SemiJoin,Outer Join,为了算法简洁下面只考虑InnerJoin)
Idea为对于输入的N张表,可以启发式生成N个Join顺序(每个序列的第一张表都不一样)构造成左深树,比较N个Join顺序的Cost,选择最好的一个。下面以N = 5为例,启发式生成5个顺序,选择Cost最低的一个。
[1,4,5,2,3]
[2,5,1,3,4]
[3,1,5,2,4]
[4,5,3,1,4]
[5,3,2,1,4]
算法流程
假定输入为N张表的inner join
- 设置权重Weight[i][j],其中i为第i张表,j为第j张表。权重越大,这两张表应该越先Join。
Weight[i][j] = 3,如果i,j存在等值join条件
Weight[i][j] = 2,如果i,j存在非等值join条件(>, >=, <, <=, !=)
Weight[i][j] = 1, 其它情况(i和j可能是笛卡尔集)
- 假定序列第一张表为X,第二张表Y选取规则如下
- 优先考虑Weight[X][Y]大的Y
- 如果Weight值相等,则考虑Y Join X中Y的Join条件所对应列的Cardinality值,Cardinality越大越优先考虑。(PS:Cardinality越大Join的结果集越小)
- 第K张表的选择如此类推
- 最终N张表按照上述选择顺序构造出左深树
- 选择Cost最低的一个Join顺序
注意到多序列的贪心启发式Join Reorder算法是有考虑多个Join序列,并选择出Cost最小的序列。这里的Cost可以是任何自定义的代价。
采用此Join Reorder算法的系统有Flink和Drill。
GOO算法
GOO(Greedy Operator Ordering)[1]
- 针对上面贪心启发式只能构造左深树的场景,GOO可以构造出BushyTree。
- 贪心启发式算法只考虑了JoinTree和一张表做Join。GOO则考虑了JoinTree和JoinTree可以做Join
算法流程
假定输入N张表
令T = N张表的集合
- while |T| > 1
a. 找到T中两个JoinTree, T[i]和T[j]使得它们的Join结果集最小
b. T = (T \ T[i] \ T[j])
c. T = T U {T[i] join T[j]}
- 最终T中唯一元素就是Bushy Tree空间上贪心搜到的JoinOrder
遗传算法(GEQO)
PostgreSQL在表数目较多(>= 12)情况下采用的Genetic Query Optimization (GEQO) 算法
假定输入N张表
- 每张表可以看作一个基因
- N个不同基因组成一条染色体
- 因此Join Reorder可以看成是找到最优秀的染色体(代价最低)
模拟基因遗传的特点,选择父染色体和母染色体,交换部分片段生成孩子染色体。淘汰不优秀的染色体,在优秀的染色体中迭代若干代,得到一个Order。
算法流程
假定输入为N张表,初始化染色体池大小为PoolSize。以及染色体迭代次数generation。(默认为2^(N-1))
- 随机生成PoolSize个有效的染色体.(例如可以限定某些条件)
- 给染色体池子按照染色体的优秀程度排序
- 开始迭代第1,2,..k,...generation轮
- 先从染色体池子按照特定分布取出两条染色作为父和母染色体(这个分布的概率会偏向选择优秀的染色体)
- 父和母染色体采取一定的重组策略生成孩子染色体。(重组策略有很多种,最简单的是随机取父染色体的一段连续基因片段,之后按照母染色体顺序添加缺失的基因)
- 将孩子染色体放入染色体池中,并淘汰最差的染色体
- 染色体的优秀程度通过将染色体构造成Join树后通过CBO评估出代价,代价越低越优秀
- 持续迭代至要求的迭代次数,选择出池子中最优秀的基因构建出Join,这里的Join一般是LeftDeep的。(PG做了Bushy)
遗传算法有一个缺点是每次结果执行计划会不一样导致性能不稳定,这对于追求每次查询结果性能稳定的场景来说是比较糟糕的。
深度优先枚举Join Reorder算法
Mysql数据库诞生至今已经二十多年,作为一个面向OLTP的数据库,它的Join Reorder是Left Deep Tree枚举算法。其中Join Reorder会考虑索引来使用Index NestedLoop Join。
算法流程
- 表 <= 7时,完全遍历,搜索空间为Left Deep Tree,深度优先遍Join每个顺序(N!复杂度)。考虑每一个序列的代价。
- 表 >7时,通过遍历的深度控制搜索空间。
- Join Reorder同时考虑AccessPath索引选择
- 索引选择先通过规则匹配出完全匹配主键、唯一键的等值条件。最后再通过cost比较其它未完全匹配的索引及全表扫描。
Bottom-Up枚举的Join Reorder算法
Bottom-Up枚举的Join Reorder算法采用了动态规划的技术,可以避免了中间结果的重复计算,可枚举Bushy Tree空间。
下面采用CCP(csg-cmp-pair)概念来描述算法[3]。
假定输入N张表,且Query Graph是连通的。
对于N张表组成的集合S
定义CCP(S1, S2):
- S1是Query Graph上的连通子图
- S2是Query Graph上的连通子图
- S1和S2无交集
- S1和S2之间存在边
我们可以从1张表到N张表显式遍历CCP逐步找到BestPlan。
PS:CCP的数目和Query Graph的形状是有关系的,例如全连接的Query Graph的CCP数目就会大于星型的Query Graph,而链式的Query Graph的CCP数目会更少
算法流程
- 初始化单表R的BestPlan(R) = R
- (自底向上)遍历每个CCP(S1,S2),S = S1 U S2 (有不同的遍历策略[3]可以有DPsize,DPsub等,最好的策略是无Duplicate的DPccp)
- 计算出S1,S2的BestPlan p1 = BestPlan(S1),p2 = BestPlan(S2),当S1是一张表时,选择该表的最优的AccessPath
- CurrPlan = CreateJoinTree(p1,p2),根据已有的Join算法,生成不同的Join来连接p1,p2两个子执行计划。
- BestPlan(S) = minCost(CurrPlan,BestPlan(S) )
- 最终获取BestPlan(N张表)即是BushyTree空间上最优的JoinOrder
Bottom-Up枚举的Join Reorder算法可以有效处理Bushy Tree空间枚举的问题,并能够利用动态规划来解决中间结果重复计算的问题。而这类算法只能够处理Join Reorder这一特定问题,如果希望在Join Reorder过程中再加入更多的优化获取全局最优解,例如Agg和Join的Transpose,这类算法就做不到。
采用此类算法的数据库有PostgreSQL,OceanBase,Oracle。
基于规则变换Top-Down枚举的Join Reorder算法
基于规则变换Join Reorder算法是需要配合Top-Down的Cascades优化框架来实现[4]的。关于PolarDB-X优化器中的Cascades框架的介绍,可以参考PolarDB-X CBO 优化器技术内幕
Join Reorder通过一系列的Join转换规则实现。计划空间搜索引擎将Join规则应用直到动态规划求解完成,此时规则对应的Join(顺序)空间也就遍历完成。可以看出一组Join Reorder规则会对应一个Join空间,而不同的Join Reorder规则对应不同的Join空间。
Join Reorder规则支持多种Join类型的Reorder,包括Inner/Outer/Semi/Anti Join。这些Join Reorder的规则已经有论文[5][6]归纳出(如下图),e代表table、a与b代表Join、p代表Join条件。下面表格主要描述了两个不同类型的Join之间可以作转换的情况(assoc、l-asscom、r-asscom)。另外还有一个只适用于Inner Join的Join交换律(comm),即左右表交换。
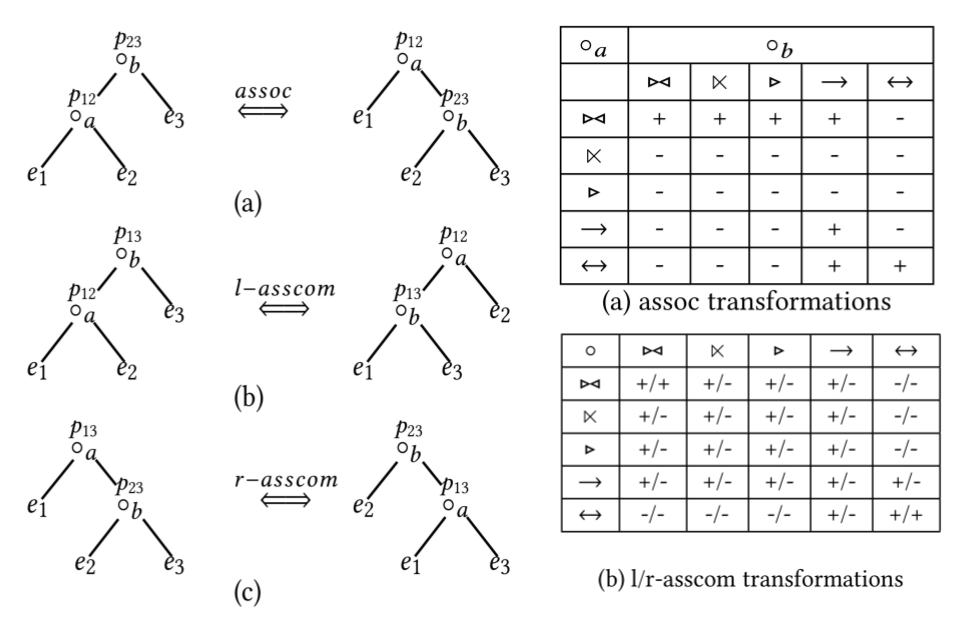
不同的规则集合对应不同的搜索空间:
Left Deep Tree:
bottom comm规则 : A⨝B → B⨝A, 只应用于左深树的最底下两表
l-asscom规则: (A⨝B)⨝C → (A⨝C)⨝B
Zig-Zag Tree:
comm规则 : A⨝B → B⨝A
l-asscom规则 : (A⨝B)⨝C → (A⨝C)⨝B
Bushy Tree:
comm规则 : A⨝B → B⨝A
assoc规则: (A⨝B)⨝C → A⨝(B⨝C)
直观地来看通过交换律和结合律就能够枚举整个Bushy Tree的搜索空间。
这类算法的优点是可以利用Cascades引擎Top-Down动态规划的过程中通过Branch and Bound进行空间剪枝,同时通过物理属性驱动搜索的方式更加优雅高效地处理Interesting Order问题。还有可以将Join Reorder的优化规则和其他任何类型的优化规则放入Cascades搜索引擎中获得全局最优解。
采用此类算法的数据库有SQL Server, CockroachDB, PolarDB-X
PolarDB-X Join Reorder算法
PolarDB-X采用的Join Reorder算法为基于规则变换Top-Down的Join Reorder算法。
Duplicate Free Join Reorder Rule Set
PolarDB-X为了提升优化效率会采用Duplicate-Free的Join Reorder规则[7][8], Duplicate-Free意味着这组规则不存在generate duplicate的情况,并且可以遍历同样完整的空间。核心思路就是通过记录算子转换的“历史路径信息”,从而避免generate duplicate
下面给出两个空间的Duplicate-Free规则集合
Left Deep Tree:
Rule1 (l-asscom) : (A⨝0B)⨝1C → (A⨝2C)⨝3B , Rule1不能再次作用于⨝3
Rule2 (comm) : A⨝0B → B⨝1A,Rule2不能再以作用于⨝1
Bushy Tree:
Rule1 (comm): A⨝0B → B⨝1A, Rule1,2,3,4均不在再次作用于⨝1
Rule2 (r-assoc): (A⨝0B)⨝1C → A⨝2(B⨝3C), Rule2,3,4均不在再次作用于⨝2
Rule3 (l-assoc): A⨝0(B⨝1C) → (A⨝2B)⨝3C , Rule2,3,4均不在再次作用于⨝3
Rule4 (exchange): (A⨝0B)⨝1(C⨝2D) → (A⨝3C)⨝4(B⨝5D) , Rule1,2,3,4均不在再次作用于⨝4
可以看见Duplicate-Free规则因为记录了“历史路径信息”导致变得复杂,“历史路径信息”实际编码在了Join算子里面,每次转换Join算子会更改对应的信息。每次规则匹配也需要检查额外条件。Zig-Zag Tree可以对Left Deep Tree的思路类似给出。
Adaptive Search Space
搜索空间大小:Bushy Tree > Zig-Zag Tree > Left Deep Tree
搜索空间越大或Join越多,优化搜索时间就越久,为了让优化时间维持在一定时间以内,PolardB-X采用了Adaptive Search Space,即根据Join的目决定搜索空间的大小。
表数目 | 搜索空间 |
<= 4 | Bushy Tree |
<= 6 | Zig-Zag Tree |
<= 8 | Left Deep Tree |
>=9 | Heuristic |
在表数>=9个的时候,PolarDB-X会采用多序列贪心启发式Join Reorder算法加速Join Reorder的过程。
Join Reorder与其他规则
PolarDB-X的Join Reorder会和其他关键的优化规则一起组成更大的搜索空间并获取全局最优解。
Join算法规则
Join的顺序选择和具体的Join算子物理算法息息相关,因为不同的Join算子物理算法会有不同的代价。目前PolarDB-X支持HashJoin, Sort Merge Join, NestedLoop Join, BKA Join(分布式的Index Nested Join)。Join算法规则会和Join Reorder规则一起构成搜索空间。
Join下推规则
因为PolarDB-X支持Join下推,因此Join的下推规则会和Join Reorder规则一起构成搜索空间。
Agg与Join交换规则
因为Agg和Join的交换有机会大大减少Join处理的数据量[9],因此这类规则也会和Join Reorder规则一起构成搜索空间。
索引选择规则
因为PolarDB-X支持全局二级索引,不同的全局二级索引会影响Join的下推和Join算法规则,因此这类规则也会和Join Reorder规则一起构成搜索空间。
Branch And Bound空间剪枝
空间剪枝是Top-Down动态规划中非常棒的一个特性,它可以保证剪枝完后的空间也一定能够找到最优解。这是相对于Bottom-Up动态规划的重要优势。以三表Join为例子来看如何进行空间剪枝。
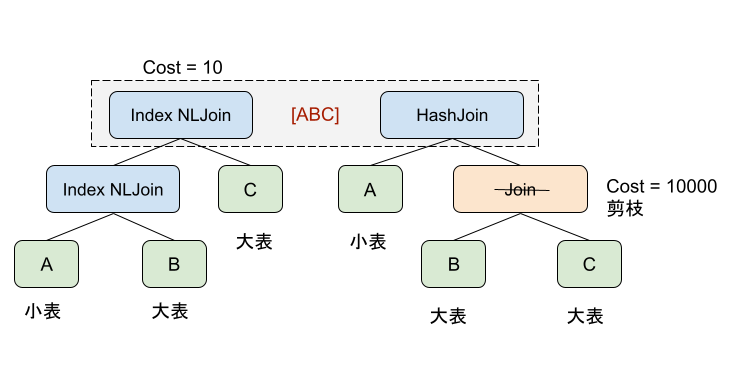
ABC的三表Join如果按照最开始的顺序优化出来了A、B、C依次使用Index Nested Loop Join,计算出代价值例如是10,之后通过Join Reorder的规则构造出了B Join C但是我们看到B Join C的最低代价也要1000, 因为是两张大表做Join,既然[ABC]等价集合中已经有了一个代价为10的执行计划。那么可以直接裁剪掉[BC]不再去为它们生成物理执行计划,因为它们无论选择什么物理执行计划都不会比10低。这就是Branch And Bound空间剪枝。
这里规则的应用顺序可以看出如果从上到下应用物理转换规则那我们有机会做到剪枝,不需要去搜索部分空间。一般来说会通过特定的启发式方法来指导搜索引擎应用物理转化规则,尽快找到一个代价低的执行计划,并利用其代价去进行空间剪枝。
总结
本文总结了数据库领域中常见的Join Reorder算法,包含:
Join Reorder算法 | 默认使用的数据库 | INFO |
单序列贪心启发式Join Reorder算法 | TiDB | Left Deep Tree |
多序列贪心启发式Join Reorder算法 | Flink, Drill, PolarDB-X | Left Deep Tree,可以比较N个Join序列,选出代价较低的 |
遗传算法 | PostgreSQL | 只有表数目大于12张时候才会开启,每次Join顺序不稳定 |
深度优先枚举Join Reorder算法 | MySQL | Left Deep Tree,表数目<=7张算法复杂度为N!,没有利用动态规划 |
Bottom-Up枚举的Join Reorder算法 | PostgreSQL, OceanBase | Bottom Up动态规划枚举Left Deep Tree或Bushy Join Tree搜索空间 |
基于规则变换Top-Down枚举的Join Reorder算法 | PolarDB-X, SQLServer, CockroachDB | TopDown动态规划枚举Left Deep Tree或Bushy Join Tree, 可以做空间剪枝,与其他优化规则一起混合做全局优化 |
PolarDB-X在表数据较多时(>=9)采用多序列贪心启发式Join Reorder算法。
PolarDB-X在表数目较少时(<9)采用基于规则变换的Top-Down的Join Reorder算法,它有如下的优点
- 使用了Duplicate Free的Join Reorder规则提升Reorder效率
- 通过Adaptive Search Space来控制搜索空间大小
- 通过Join Reorder规则和Join算法规则、Join下推规则、Agg与Join交换规则、索引选择规则一起构建搜索空间,获取全局最优解。
- 利用Top-Down搜索进行空间剪枝。
参考文献
[1] https://db.in.tum.de/teaching/ws1415/queryopt/chapter3.pdf
[2] https://www.postgresql.org/docs/9.1/geqo-pg-intro.html
[3] Analysis of Two Existing and One New Dynamic Programming Algorithm for the Generation of Optimal Bushy Join Trees without Cross Products
[4] The Cascades Framework for Query Optimization
[5] On the Correct and Complete Enumeration of the Core Search Space
[6] Improving Join Reorderability with Compensation Operators
[7] The Complexity of Transformation-Based Join Enumeration
[8] Measuring the Complexity of Join Enumeration in Query Optimization
[9] eager aggregation and lazy aggregation[1] https://db.in.tum.de/teaching/ws1415/queryopt/chapter3.pdf
[2] https://www.postgresql.org/docs/9.1/geqo-pg-intro.html
[3] Analysis of Two Existing and One New Dynamic Programming Algorithm for the Generation of Optimal Bushy Join Trees without Cross Products
[4] The Cascades Framework for Query Optimization
[5] On the Correct and Complete Enumeration of the Core Search Space
[6] Improving Join Reorderability with Compensation Operators
[7] The Complexity of Transformation-Based Join Enumeration
[8] Measuring the Complexity of Join Enumeration in Query Optimization
[9] eager aggregation and lazy aggregation
