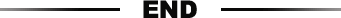以下文章来源于何先振,责编小何

多行查询:内查询返回了多行数据。
多行操作符:IN 等于列表中的任意一个。
IN的举例:
查询哪些员工等于公司部门的最低工资。
多行操作符:ANY
需要和单行比较操作符一起使用,和子查询返回的某一个值比较。任何一个满足条件就可以。
多行操作符:ALL
需要和单行比较操作符一起使用,和子查询返回的所有值进行比较,都要都满足条件才可以。
SOME 实际上是ANY的别名,作用相同,一般使用ANY
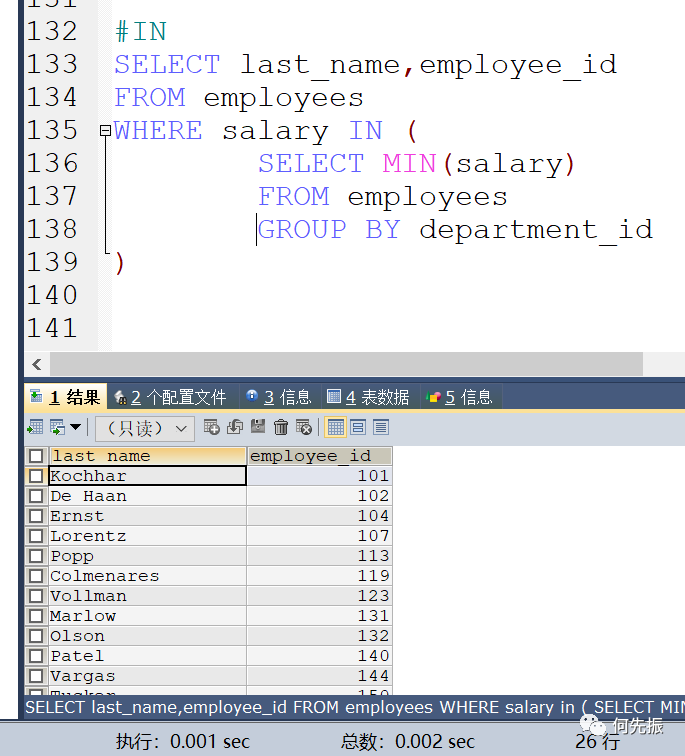
ANY的举例:
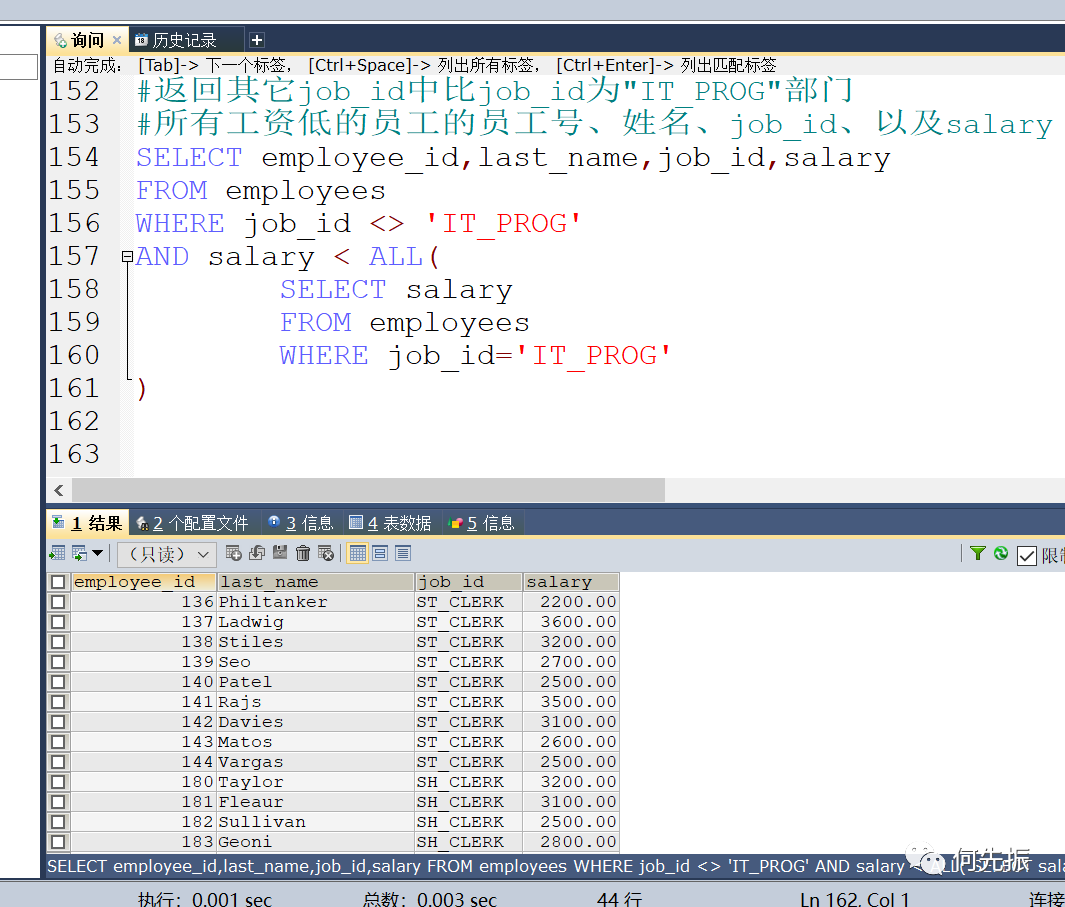
返回其它job_id中比job_id为"IT_PROG"部门任一工资低的员工的员工号、姓名、job_id、以及salary
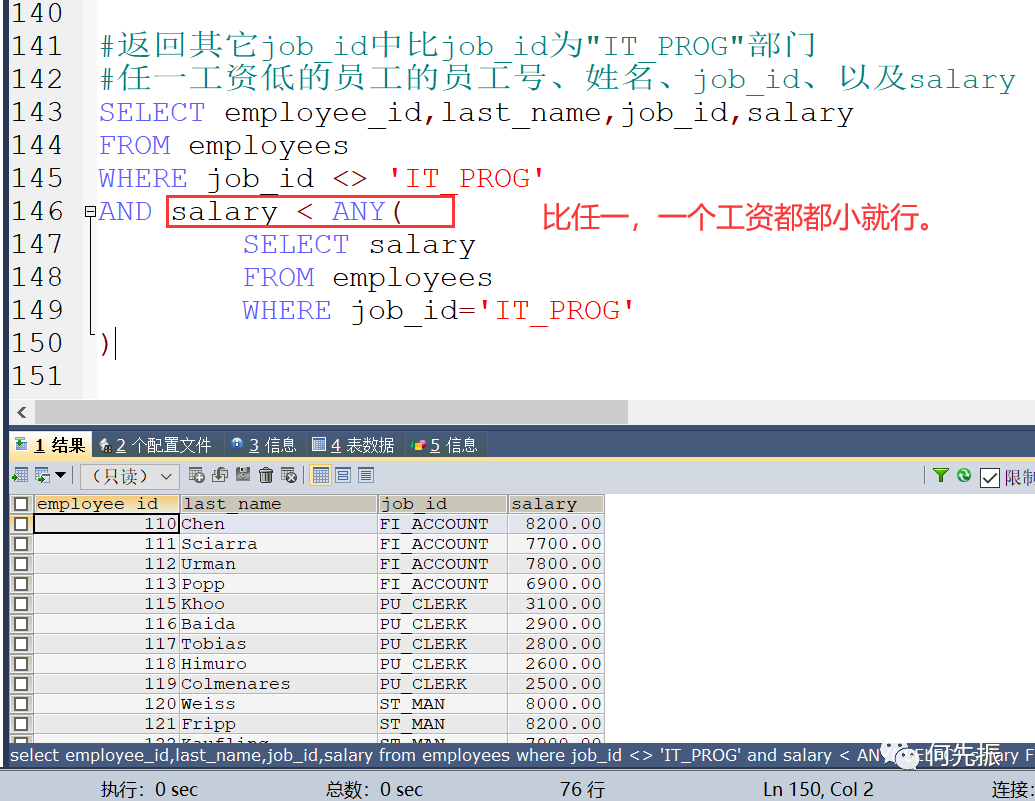
IT_PROG的部门员工工资,最小是4200
ALL的举例:
返回其它job_id中比job_id为"IT_PROG"部门所有工资低的员工的员工号、姓名、job_id、以及salary,都小于4200
from关键字使用子查询:
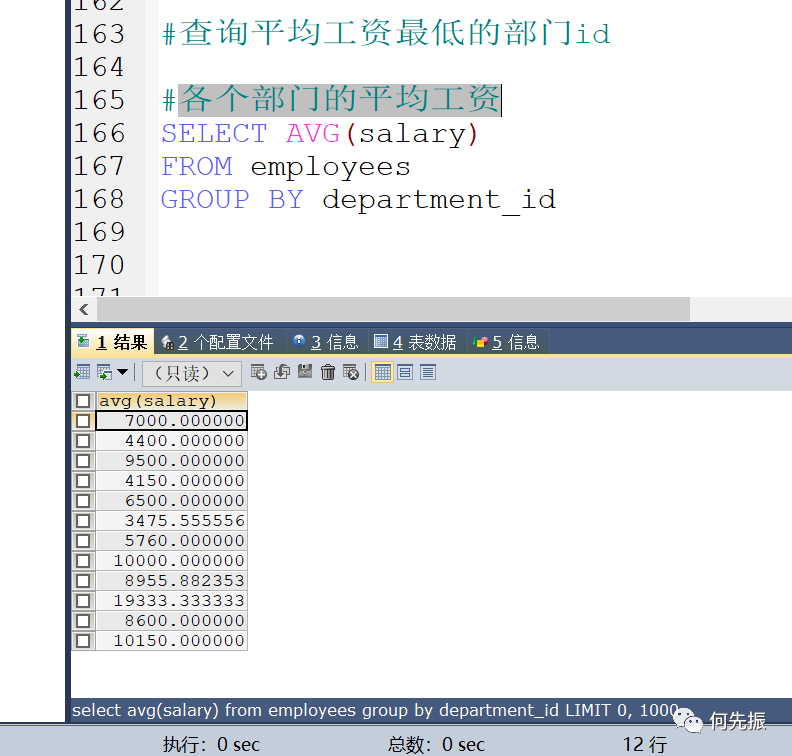
查询平均工资最低的部门id
先求各个部门的平均工资
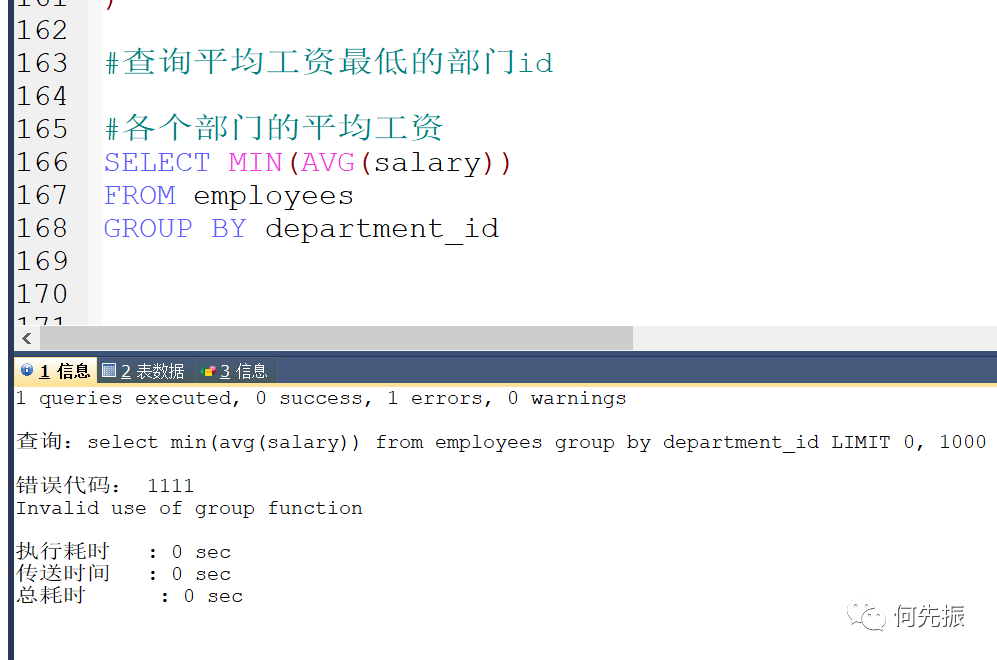
mysql中聚合函数无法嵌套,Oracle可以
可以将查询结果单独看成一张表,然后套聚合函数MIN
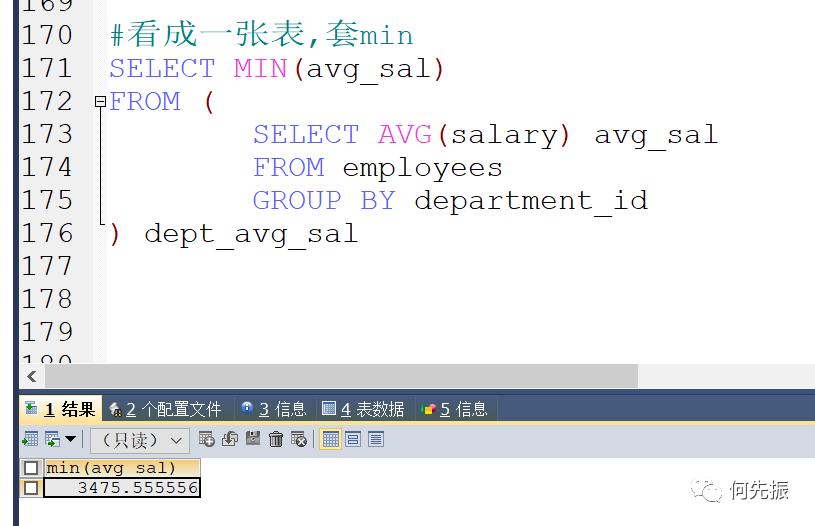
多种方式实现查询需求:
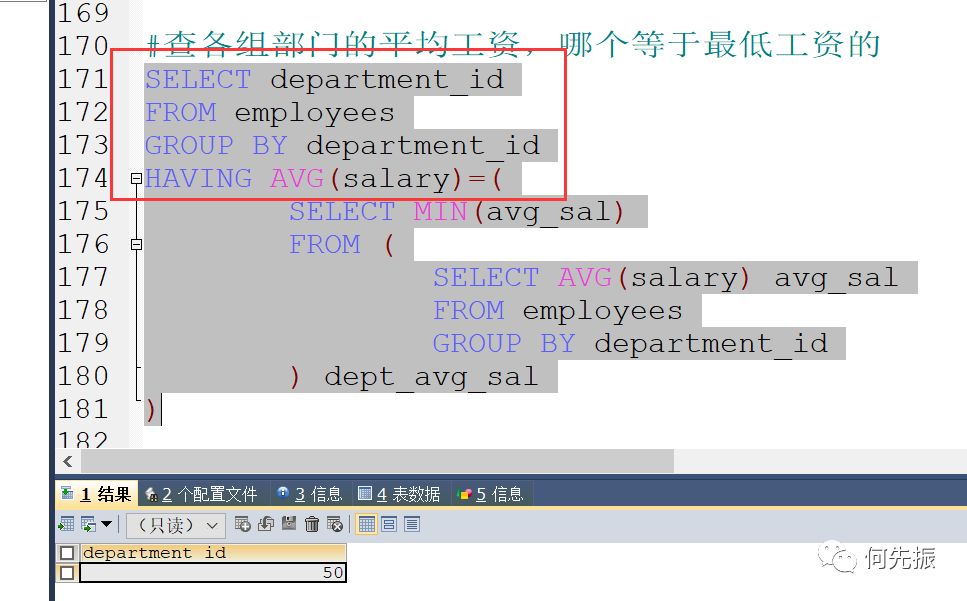
方式一:having 关键字使用子查询:
查各组部门的平均工资,哪个部门的平均工资最低
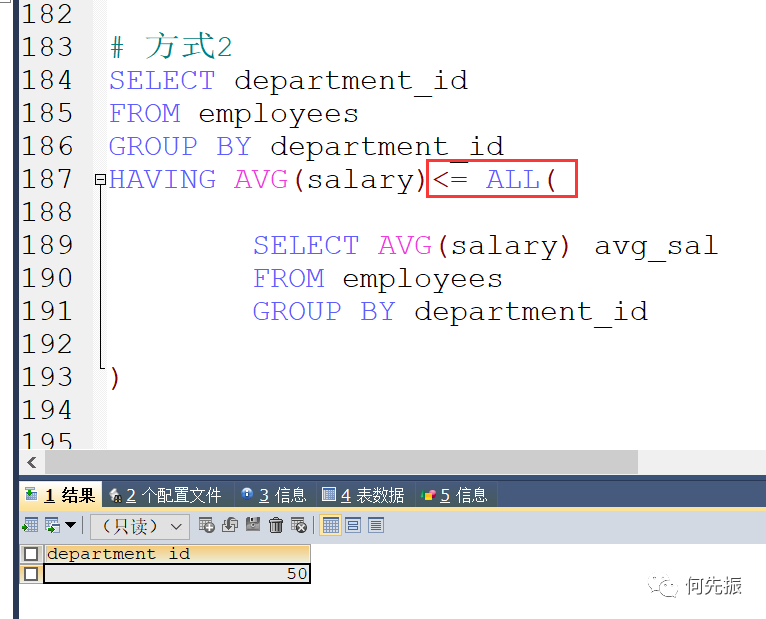
方式二:使用ALL,查询小于等于这些所有的,就是找最小的。
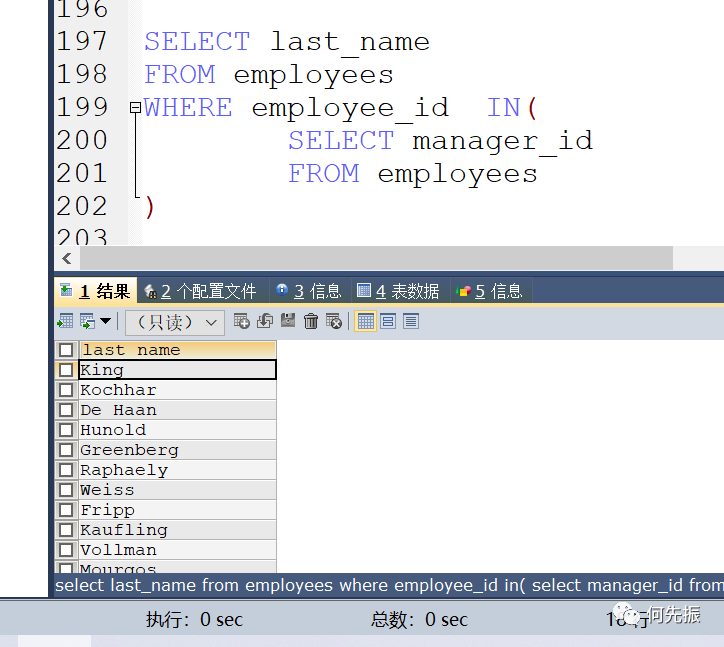
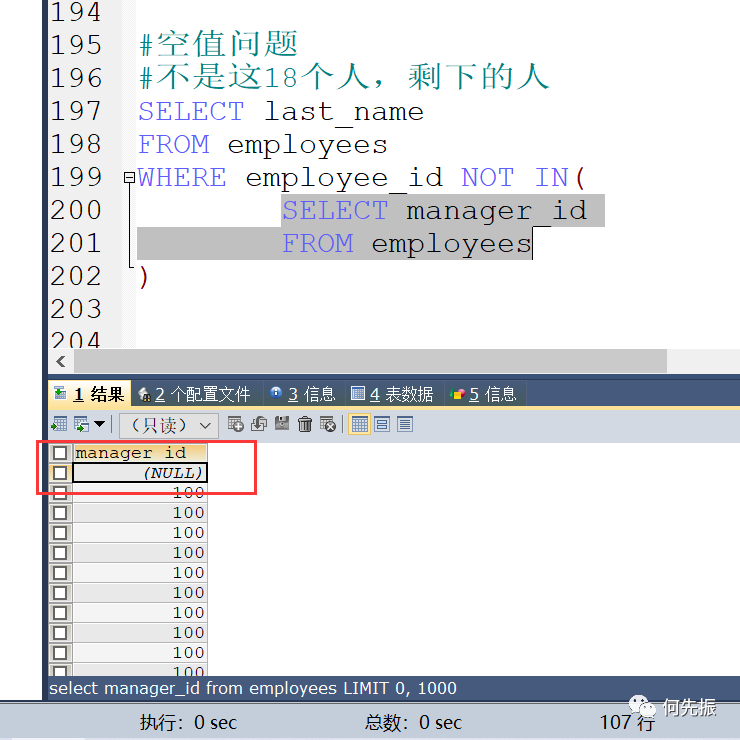
空值问题排除的举例:
先查18个管理者
查除了这18个管理者的其他人
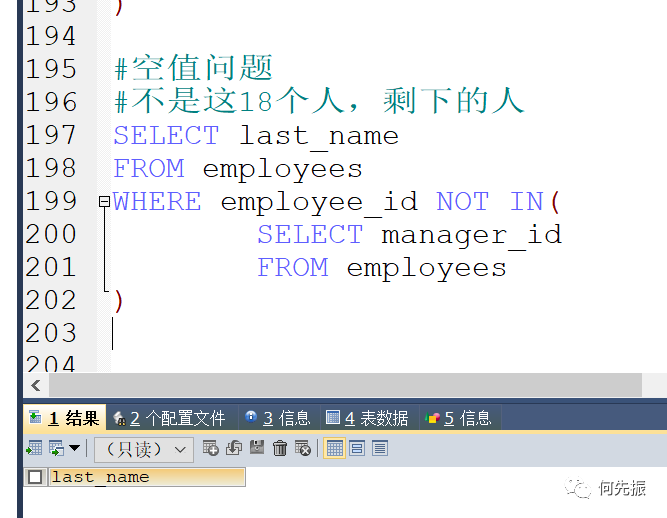
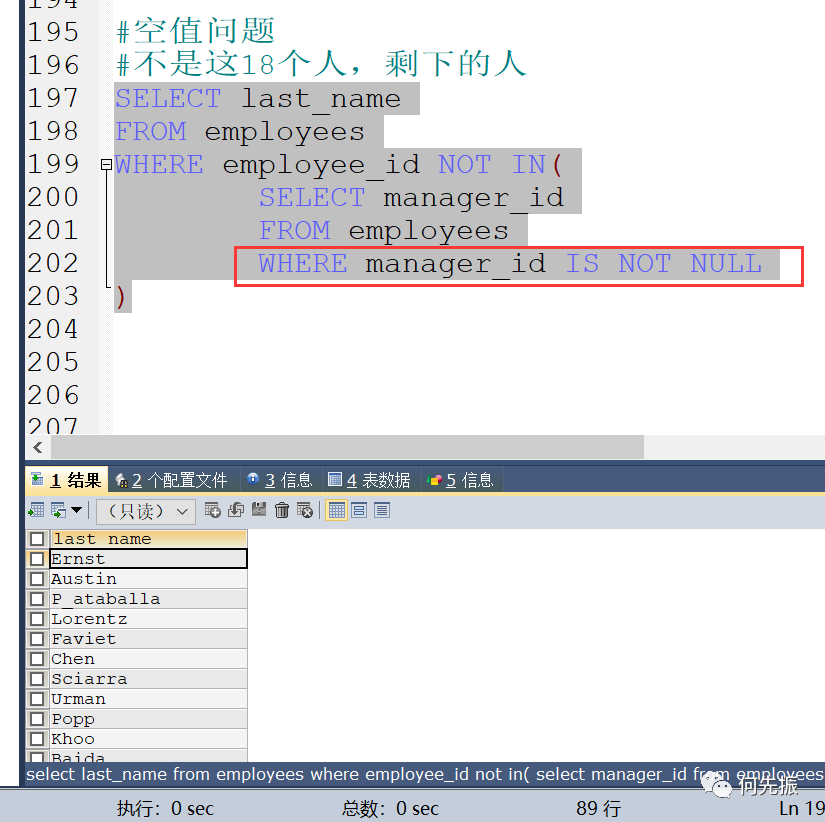
返回的不是这18个人剩下的人,是因为manager_id有一个为null
排除之后就可以出来了
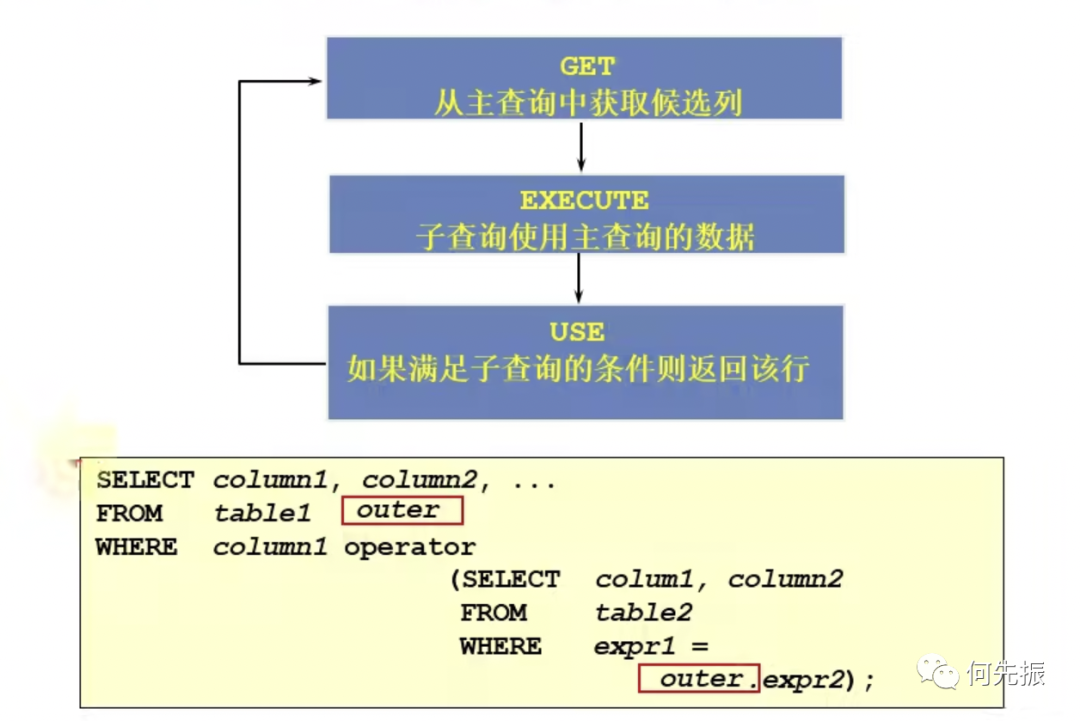
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联。
因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询称之为关联子查询。
举例一:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id。
方式1:
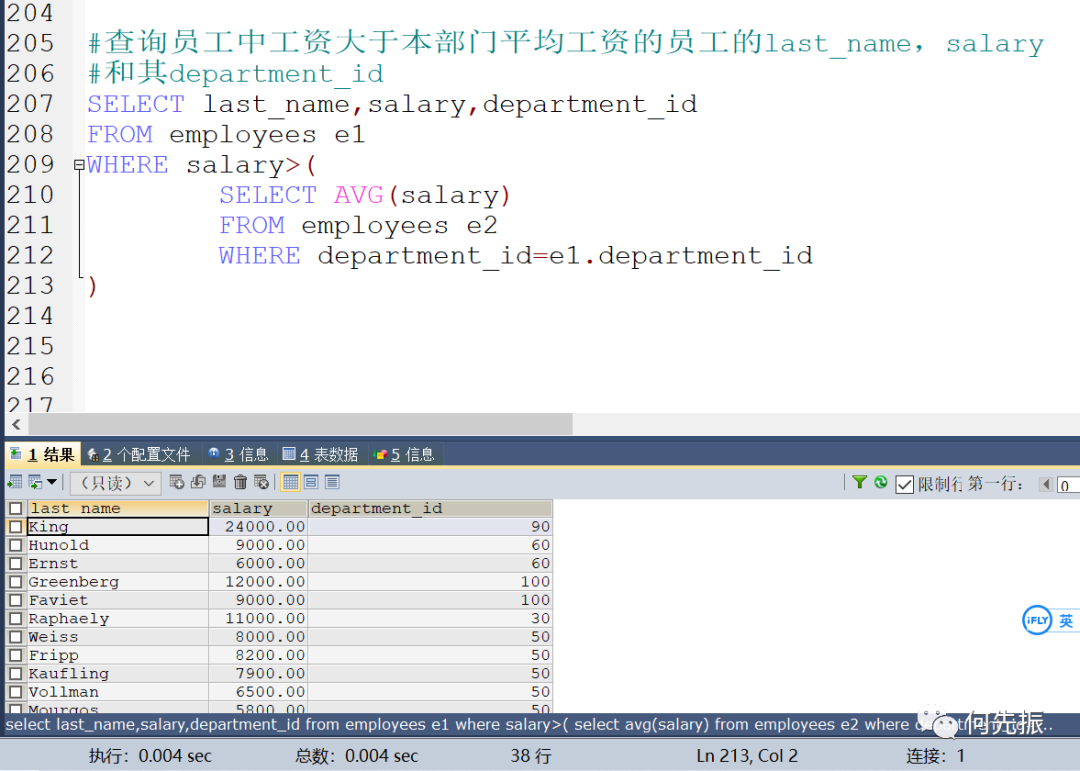
思路:外查询先查出部门id,然后传给内查询,内查询根据外查询传的部门id,计算部门的平均工资,然后跟外查询的这一行记录进行比较,满足就查询出来。
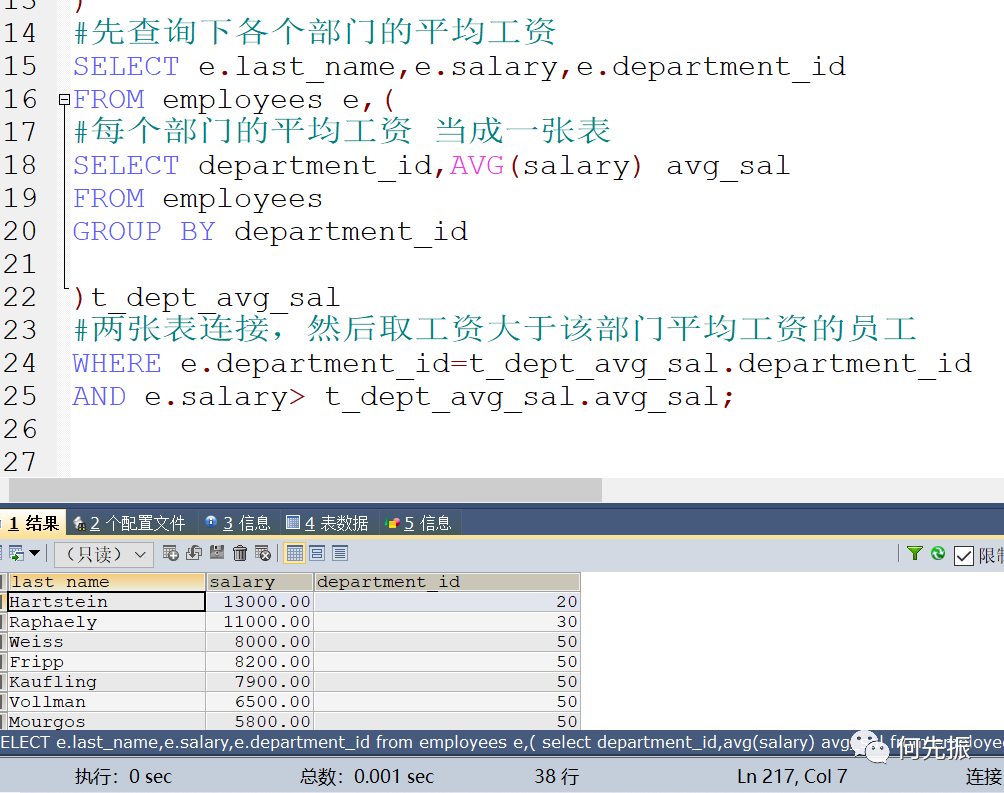
方式2:在from中声明子查询
先查询下各个部门的平均工资
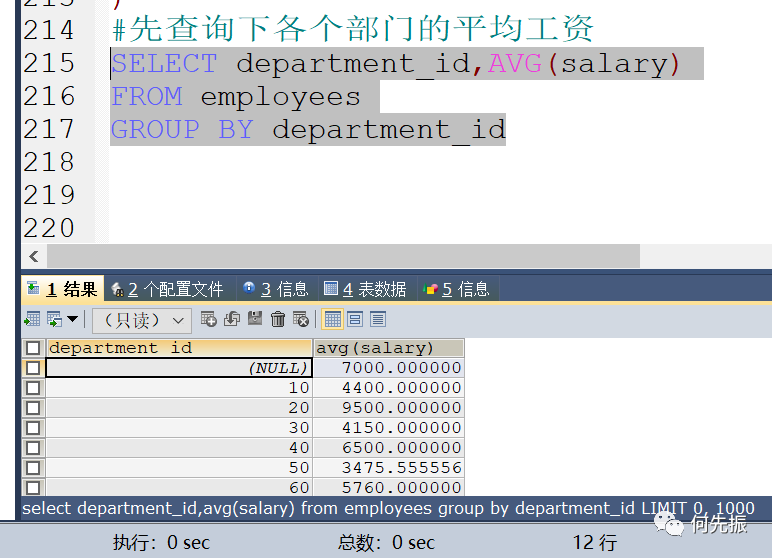
每个部门的平均工资 当成一张表,两张表连接,然后取工资大于该部门平均工资的员工
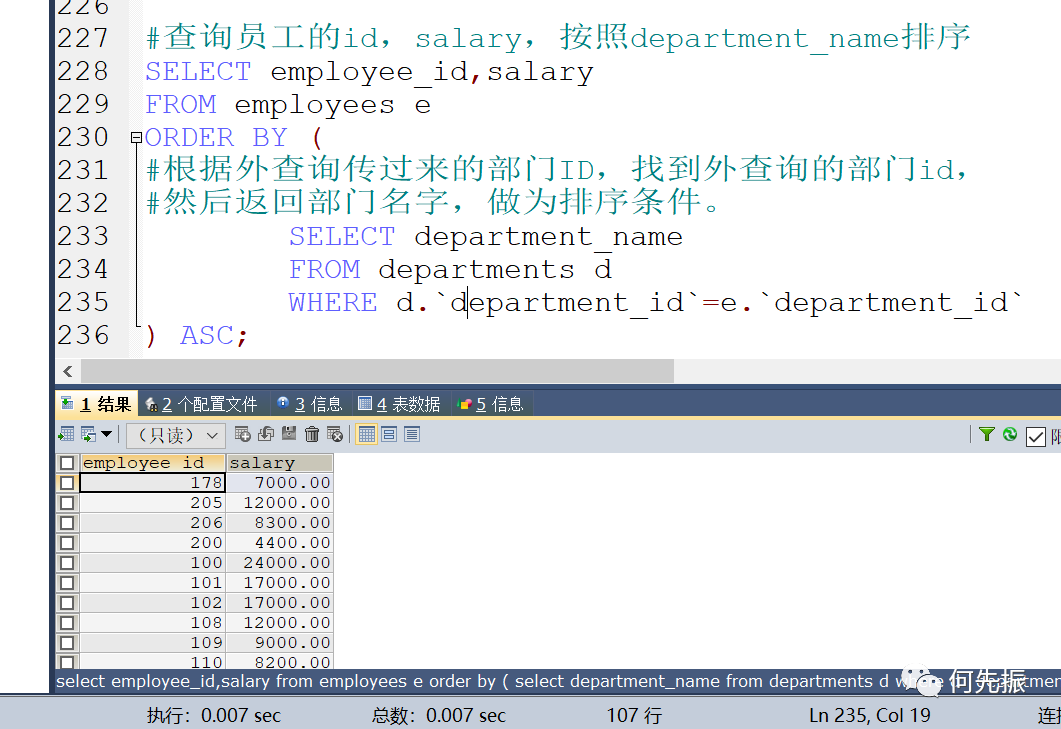
举例二:查询员工的id,salary,按照department_name排序
根据外查询传过来的部门ID,找到外查询的部门id,然后返回部门名字,作为排序条件。
结论:
除了group by 和limit 之外,其他位置都可以声明子查询
在select中可以写子查询
在from中可以写子查询
where中也写过子查询
having中也写过子查询
order by也可以写子查询
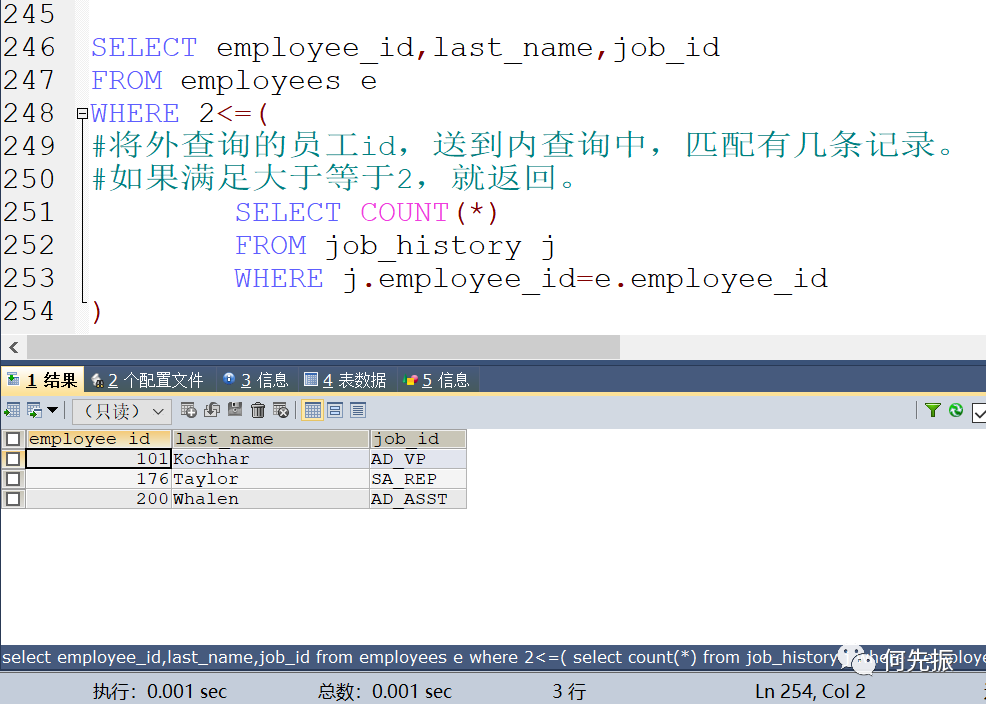
举例三:若employees表中的employee_id与job_history表中employee_id相同的数目不小于2。
输出这些相同id的员工的employee_id,last_name和其他job_id
job_history 为公司调岗表,在哪个时间段,在哪个岗位工作。
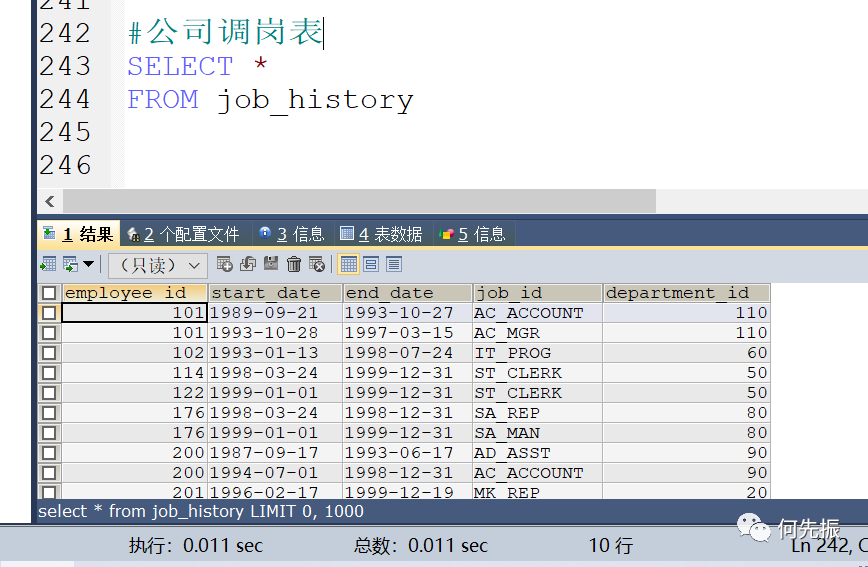
将外查询的员工id,送到内查询中,匹配有几条记录,如果满足大于等于2,就返回。
exists(存在)与not exists (不存在)关键字:
关联子查询通常也会和exists操作符一起使用,用来检查在子查询中是否存在满足条件的行。
如果在子查询中不存在满足条件的行,条件返回false,继续在子查询中查找
如果在子查询中存在满足条件的行,不在子查询中继续查找,条件返回true
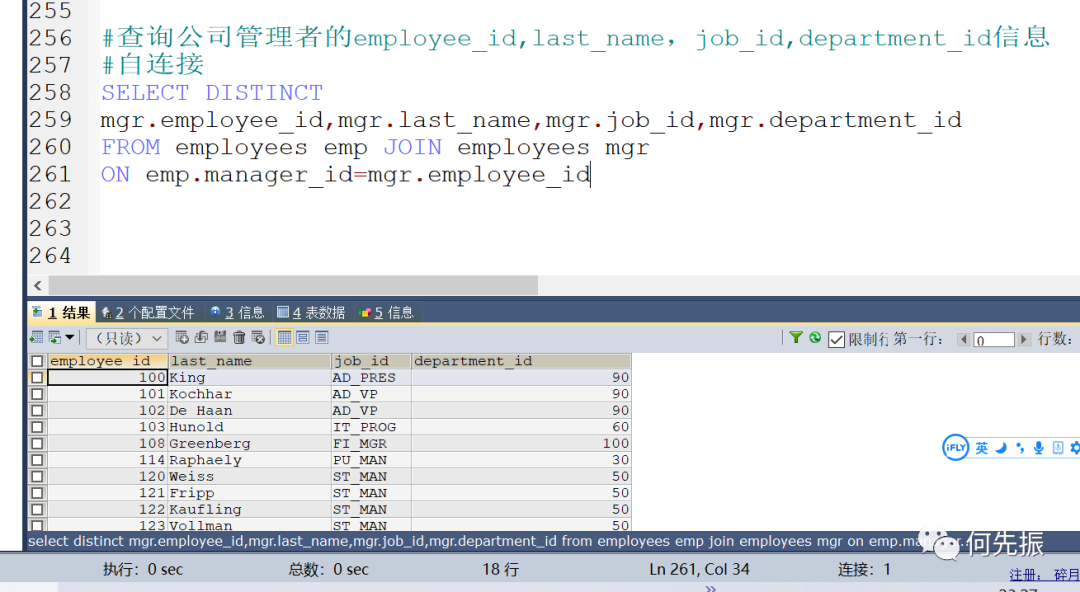
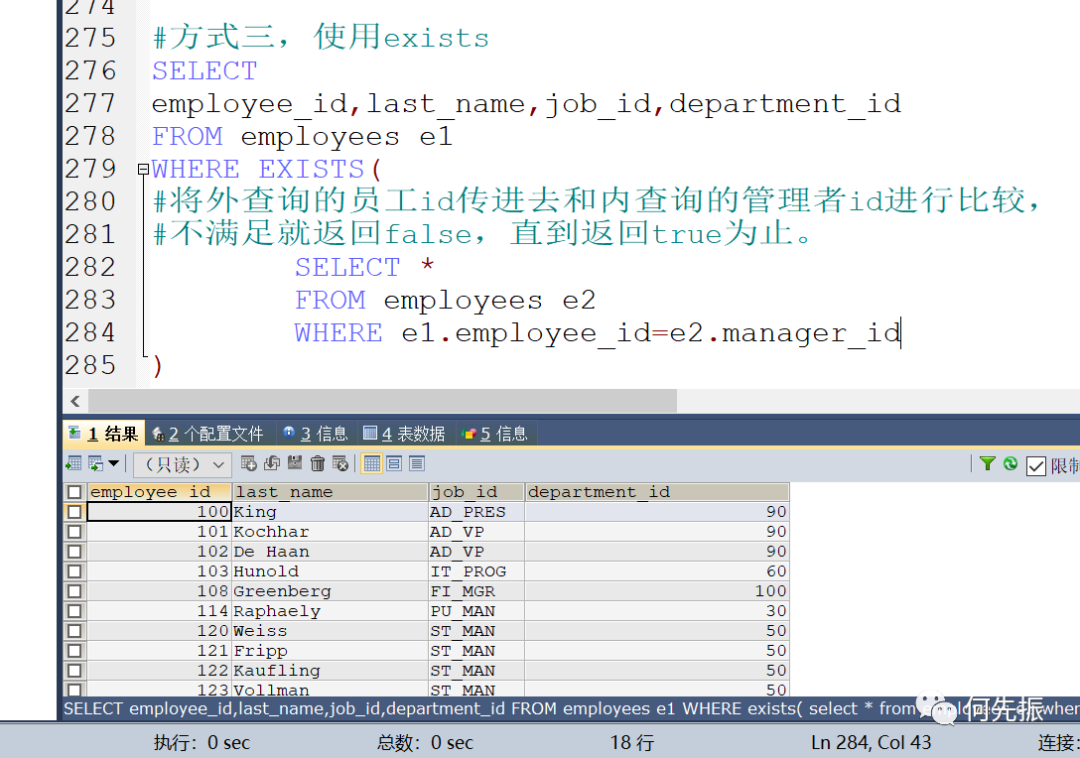
举例一:查询公司管理者的employee_id,last_name,job_id,department_id信息
方式1:自连接,然后用distinct去重
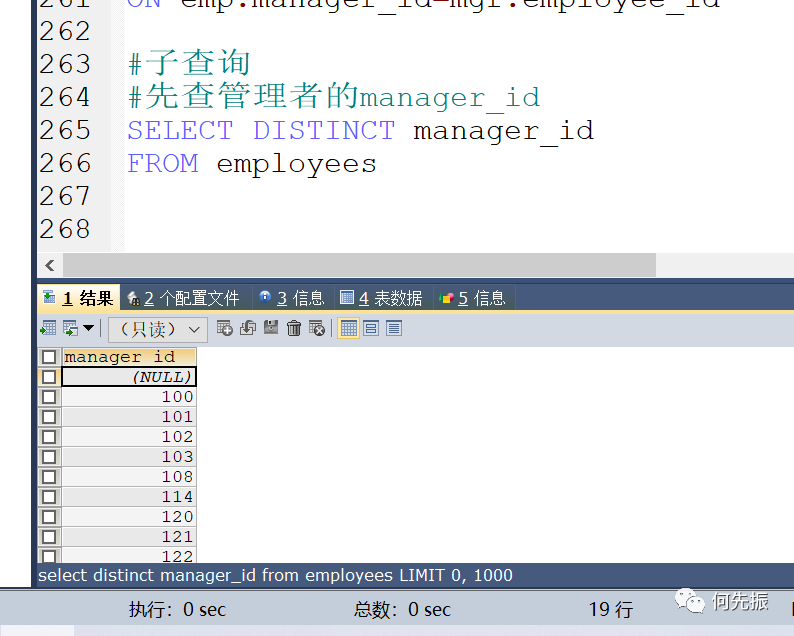
方式2:子查询
先查管理者的manager_id
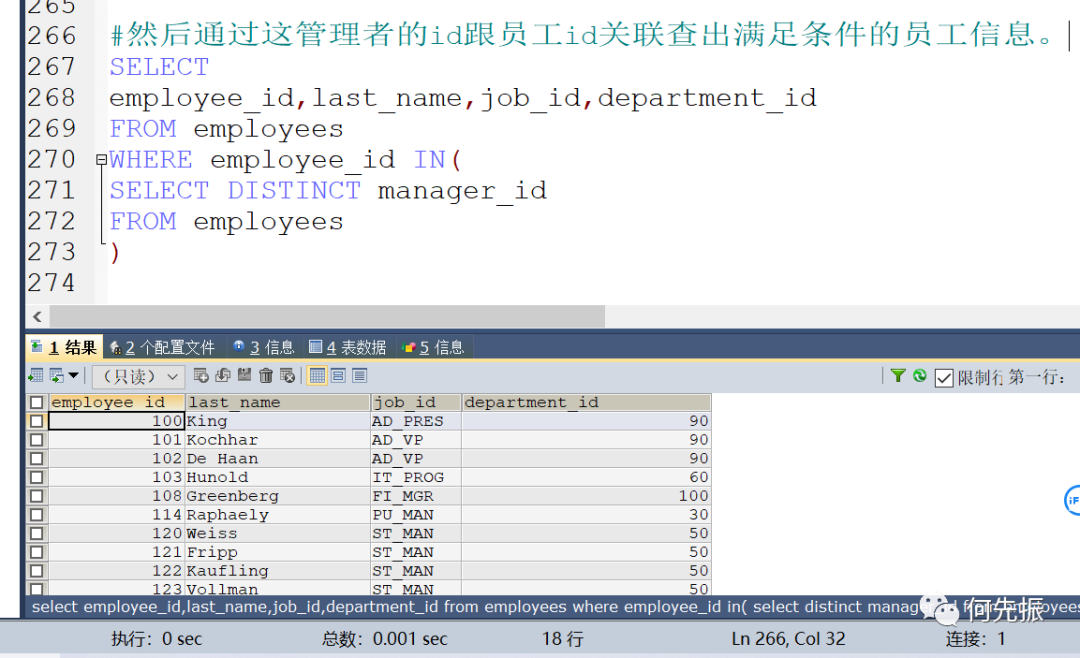
管理者的manager_id就是department_id,然后通过这管理者的id跟员工id关联查出满足条件的员工信息。
方式3:使用exists
将外查询的员工id传进去和内查询的管理者id进行比较,不满足就返回false,直到返回true为止。
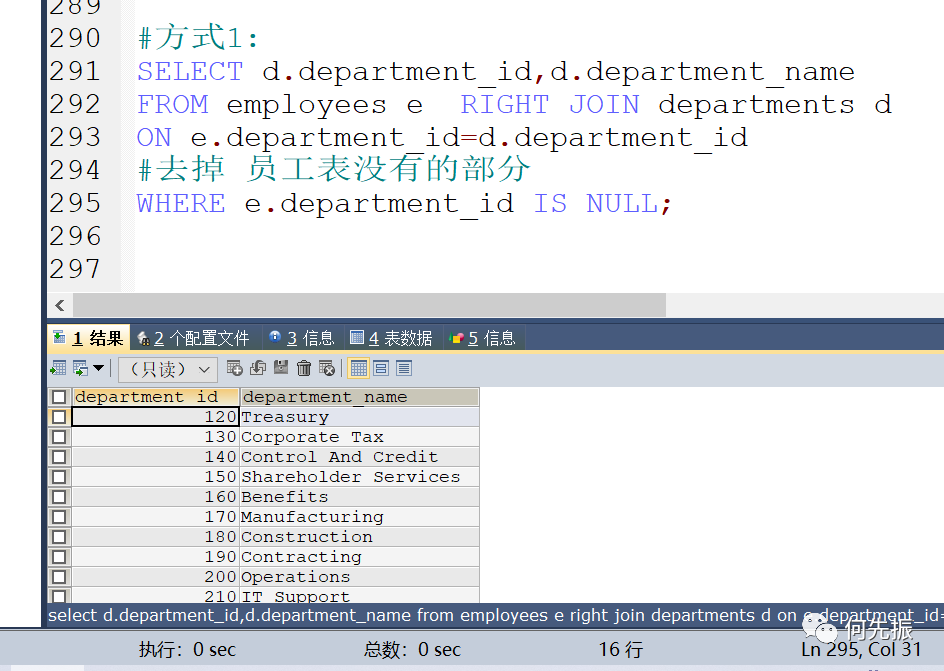
举例二:查询departments表中,不存在于employees表中的部门的department_id和department_name
方式1:
员工表和部门表,右连接,然后查询出员工department_id为空的部分。
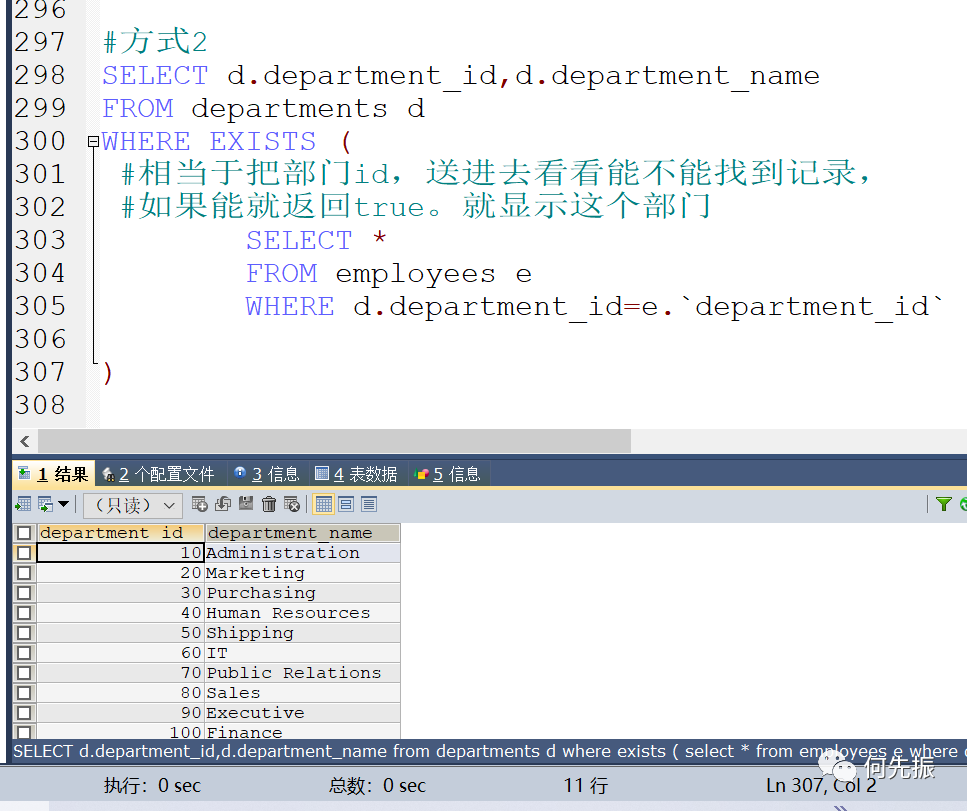
方式2:
相当于把部门id,送进去看看能不能找到记录,如果能就返回true。就显示这个部门,查出11个部门是有员工的。恰好相反,我们要找那16个没员工的部门。
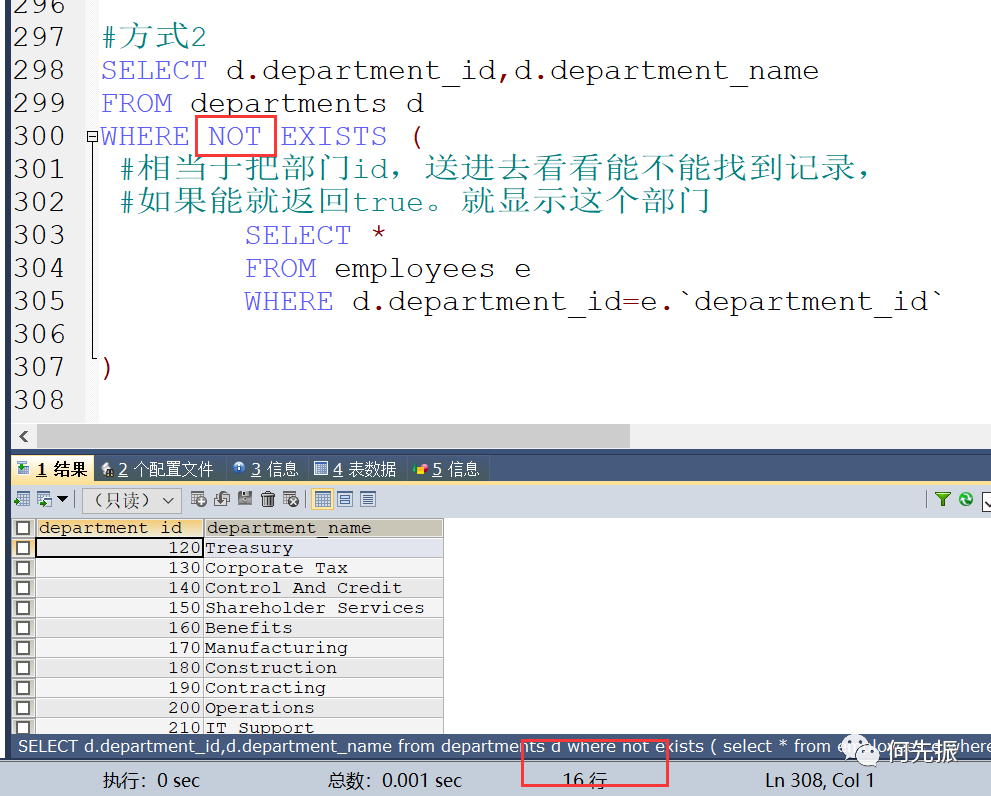
只需要加个not 就可以了,表示都不存在返回true,找到就不要。
思考题:
这么多方式,有子查询、有多表连接,那么使用多表连接好,还是子查询好。
答案:多表连接好,欲听原因后期揭晓。