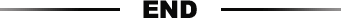以下文章来源于何先振,责编小何

聚合函数:聚合函数作用于一组数据,并对一组数据返回一个值。
常用的聚合函数:
AVG/SUM :平均值,求总和
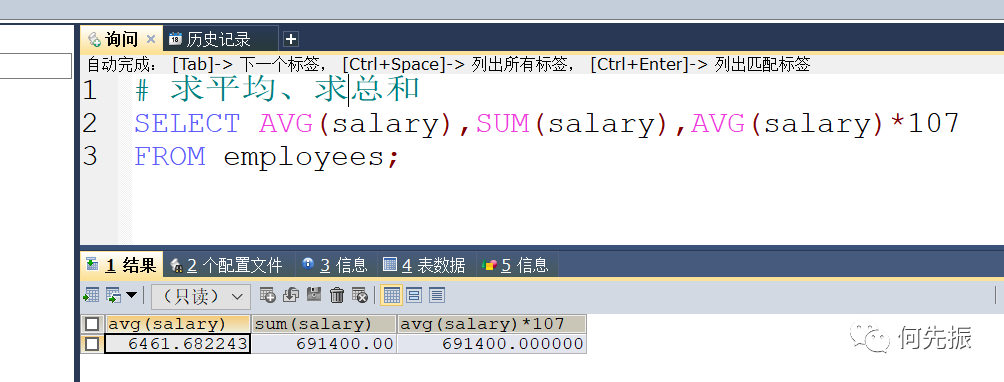
只适用于数值类型的字段或者变量
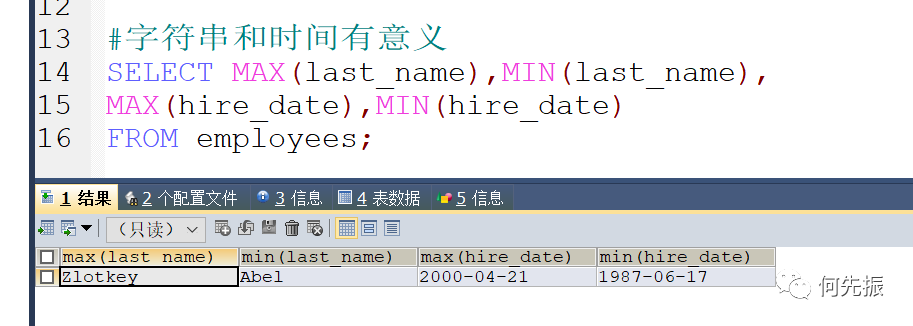
MAX/MIN:求最大值和最小值
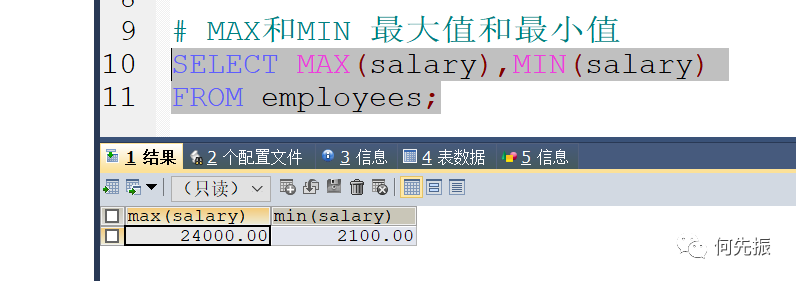
适用于数值类型、字符串类型、日期时间类型的字段(或变量)
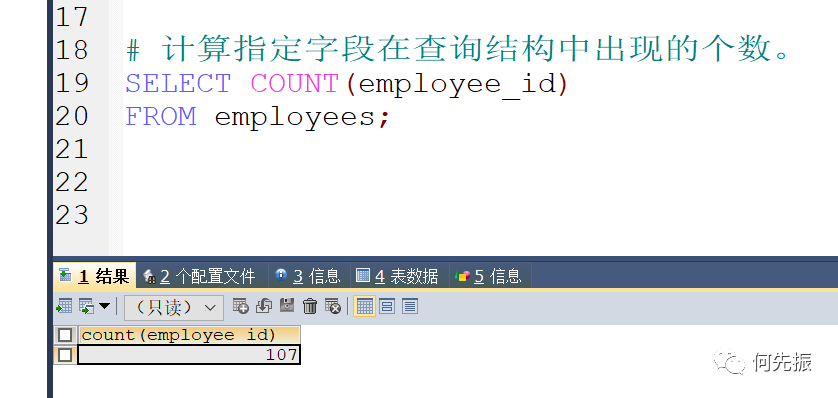
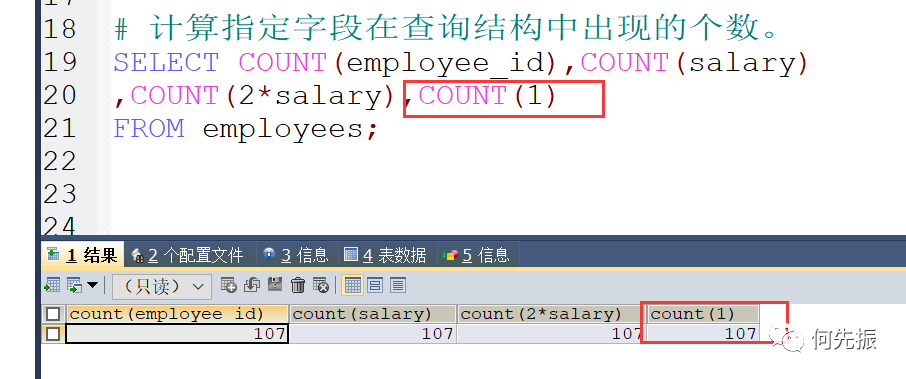
COUNT:计算指定字段在查询结构中出现的个数。
通过字段进行统计个数。count(具体字段)
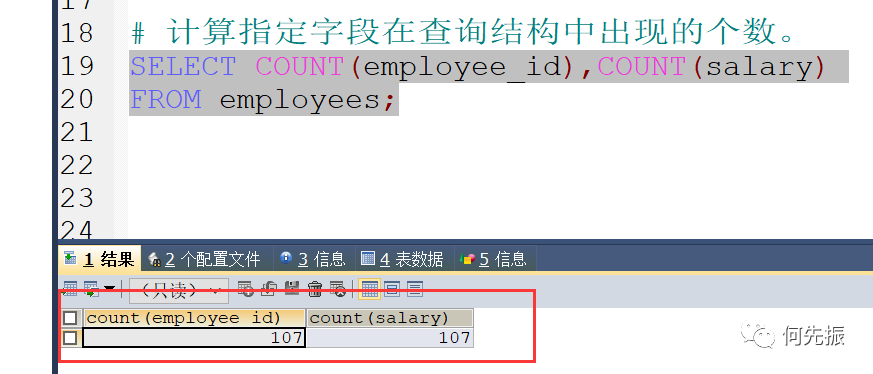
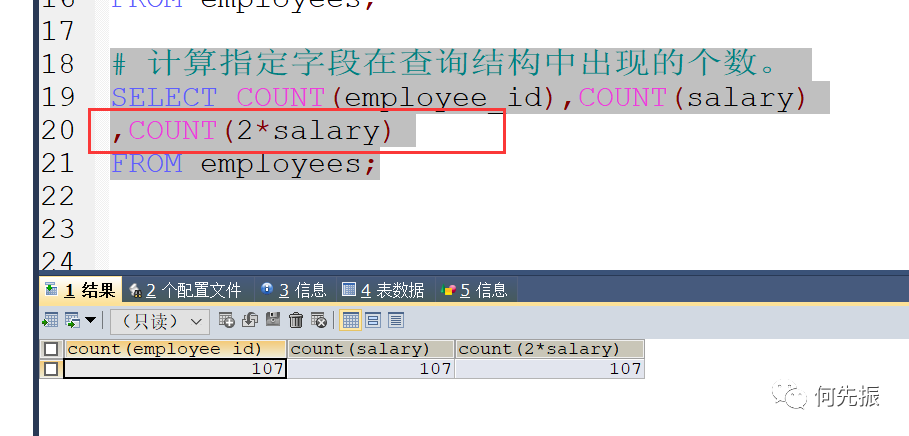
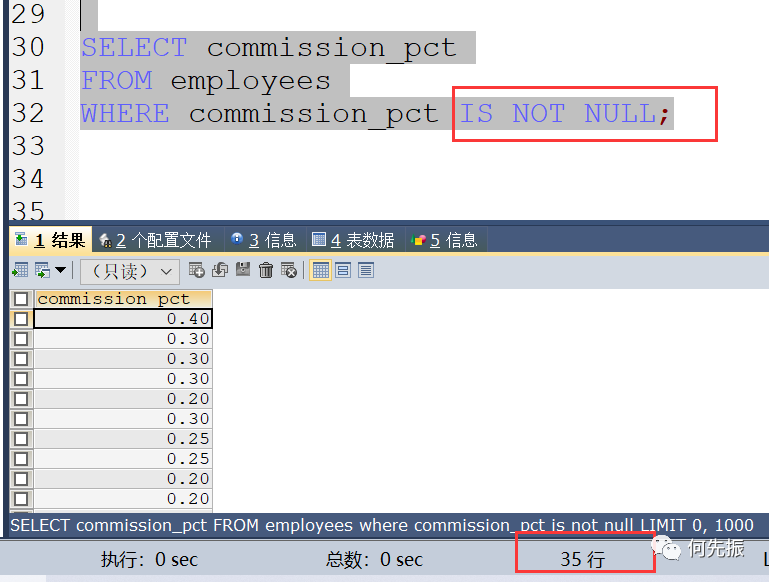
不一定统计对,因为具体字段是不包括空值的。
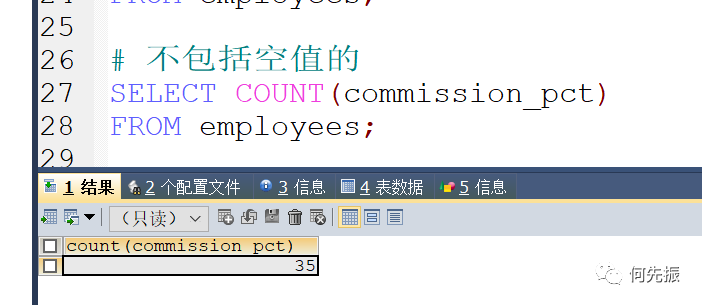
count(1):一行数据代表一个1,表示这个有几行数据。
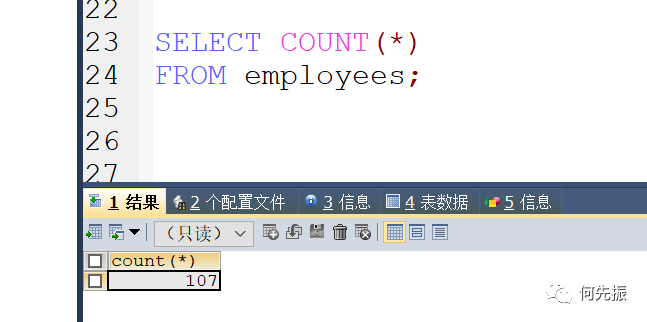
count(*):通过*代表一行数据,表示这个表有几行数据
AVG=SUM/COUNT
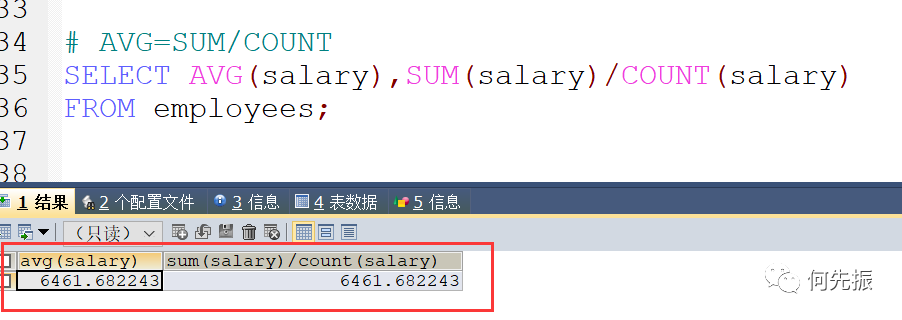
SUM和AVG也会过滤null
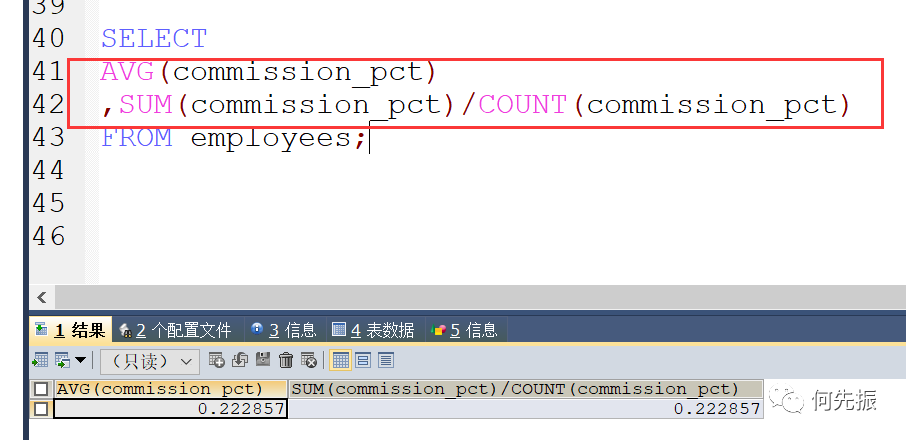
分子大,除出来的数小
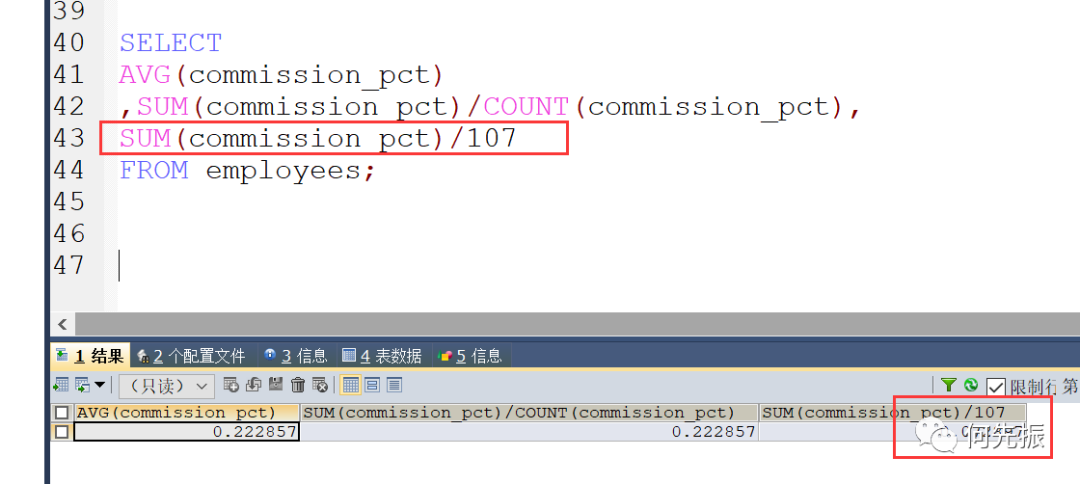
求平均奖金率
错误写法:
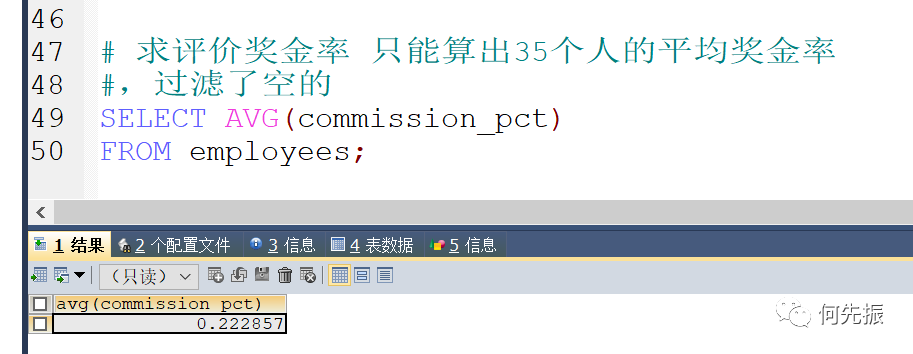
正确写法:
方式一:通过count和控制函数的嵌套
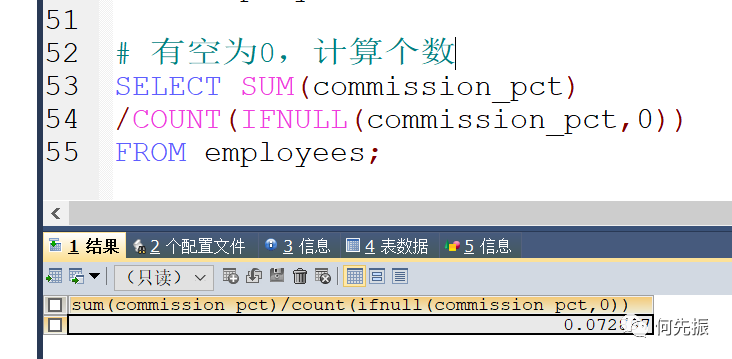
方式二:直接看有多少行数据
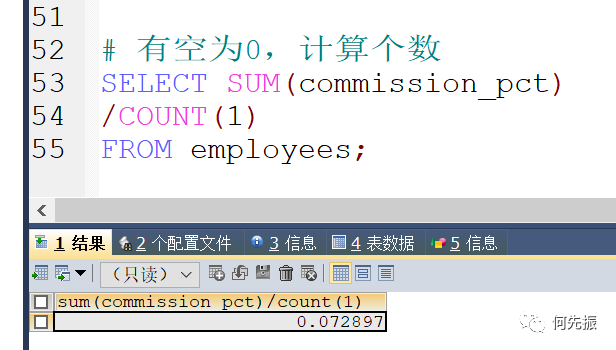
方式三,平均函数和控制函数的嵌套
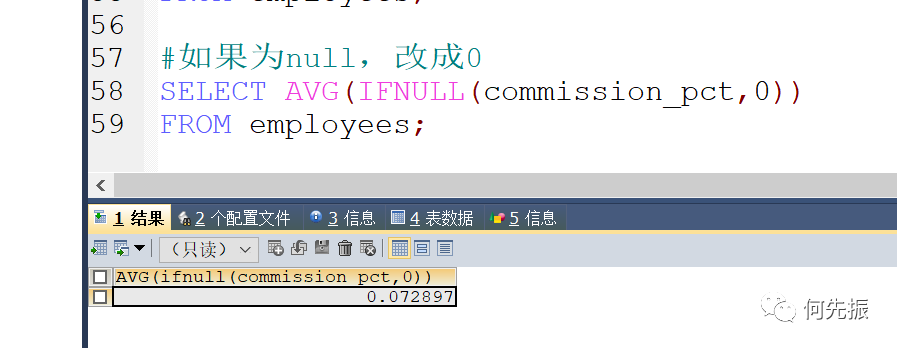
如果需要统计表中的记录数,使用cont(*)、count(1)、count(具体字段) 哪个效率更高呢?
如果使用MYISAM搜索引擎,则三者效率相同,都是o(1) 5.6版本
如果使用InnoDB 存储引擎,则三者效率:count(*)=count(1)>count(字段) 5.7、8.0
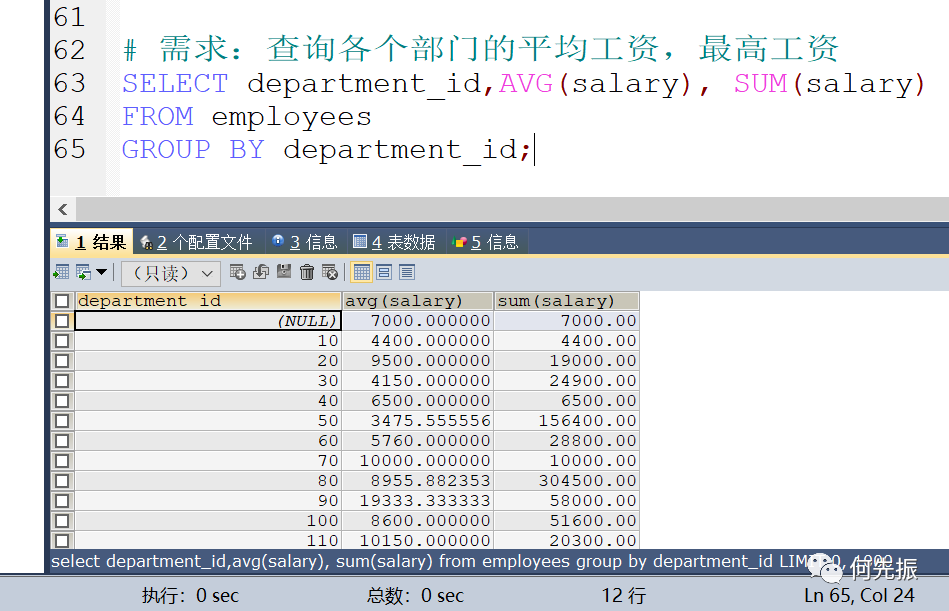
分组,查询某个部门的平均工资、以及最高工资的部门
使用多个列进行分组,查询各个部门,不同工种的平均工资
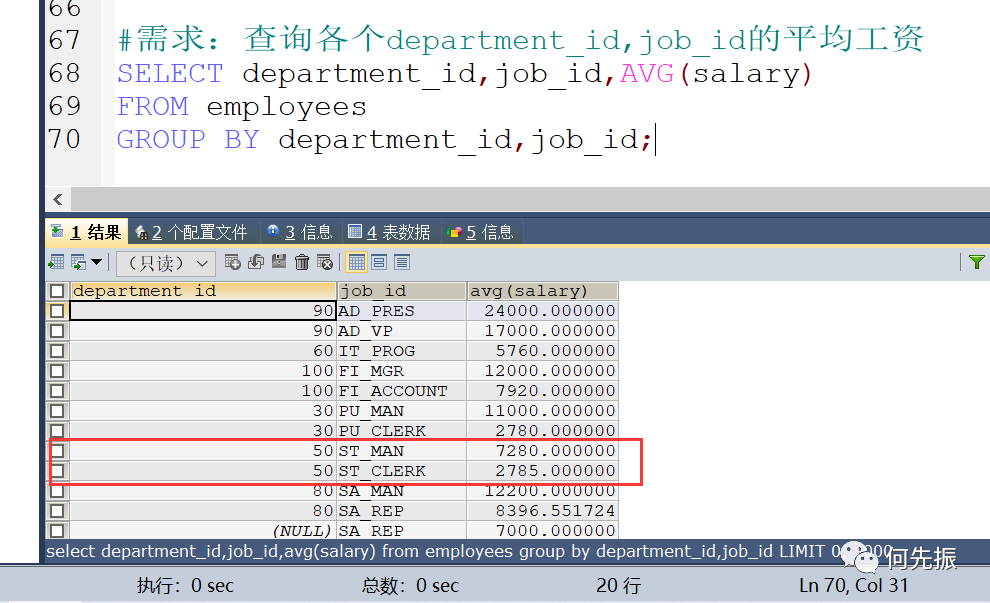
分组条件反过来顺序相同,因为都满足同一个部门,同一个工种
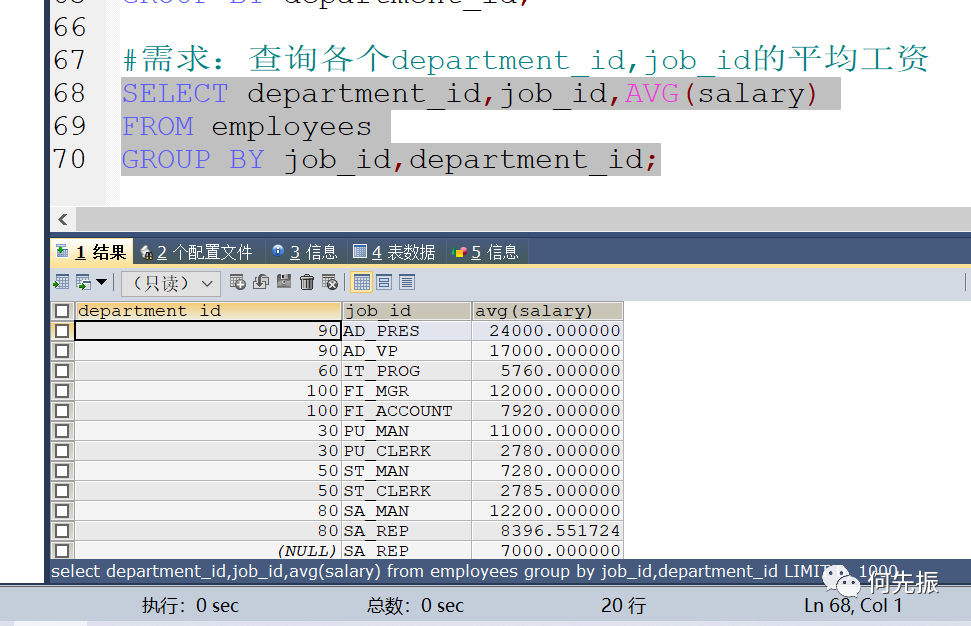
错误的写法:
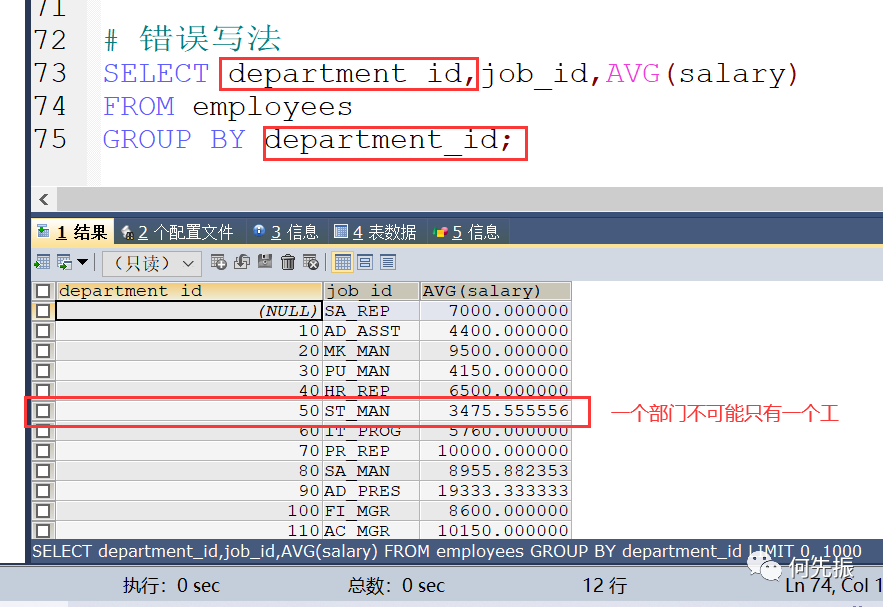
结论:
select 中出现的非组函数的字段必须声明在group by 中。反之group by 中声明的字段可以不出现在select中。
group by 声明在from后面、where后面、order by 前面、limit 前面。
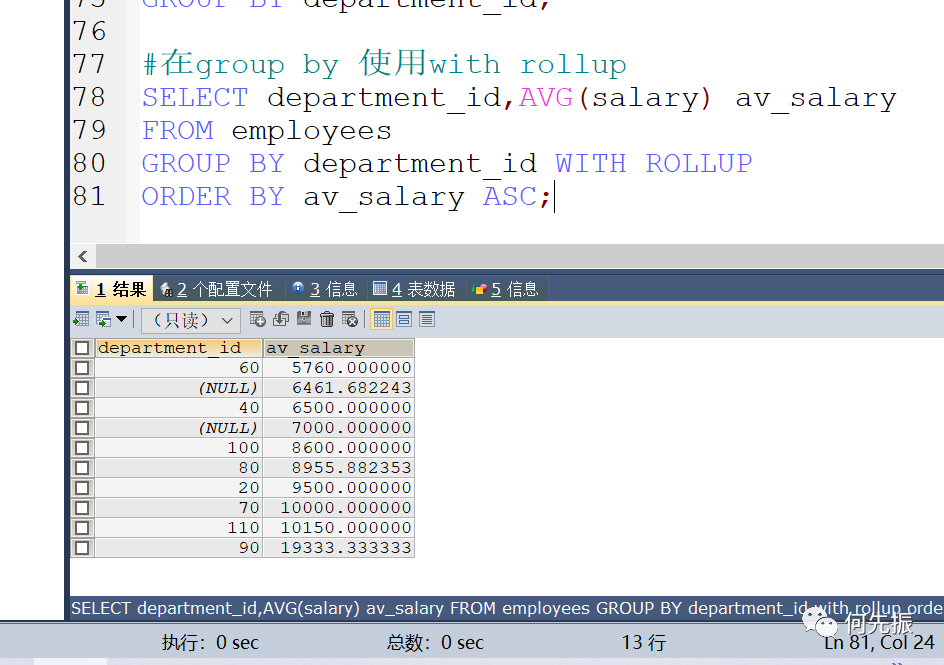
MySQL中GROUP BY 中使用WITH ROLLUP 之后,在所查询的分组记录中增加一条记录,该记录查询所有记录的总和,例如计算这12个部门的平均工资。
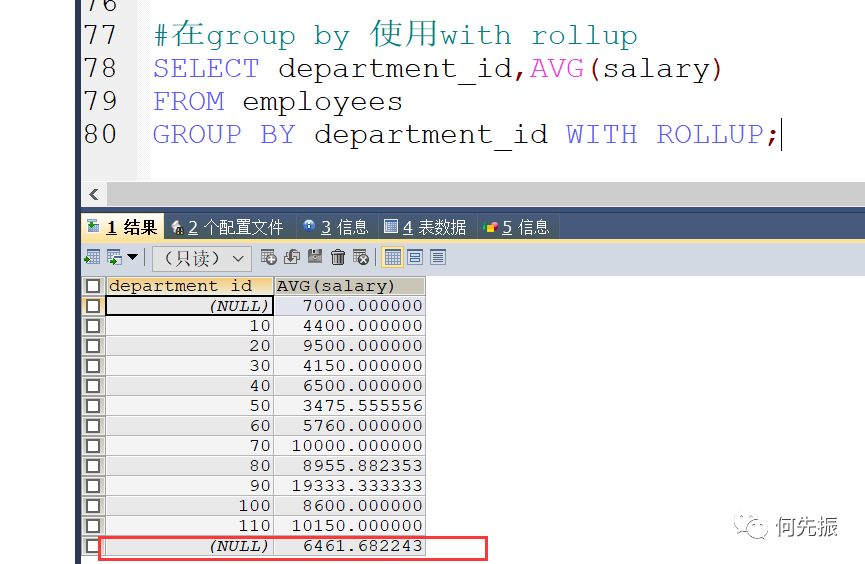
当使用 with rollup 时,不能同时使用order by子句进行结果排序,即rollup 和order by 是互相排斥的,即使可以排,也会把总体的那条记录进行排序。
作用:用来过滤数据的。
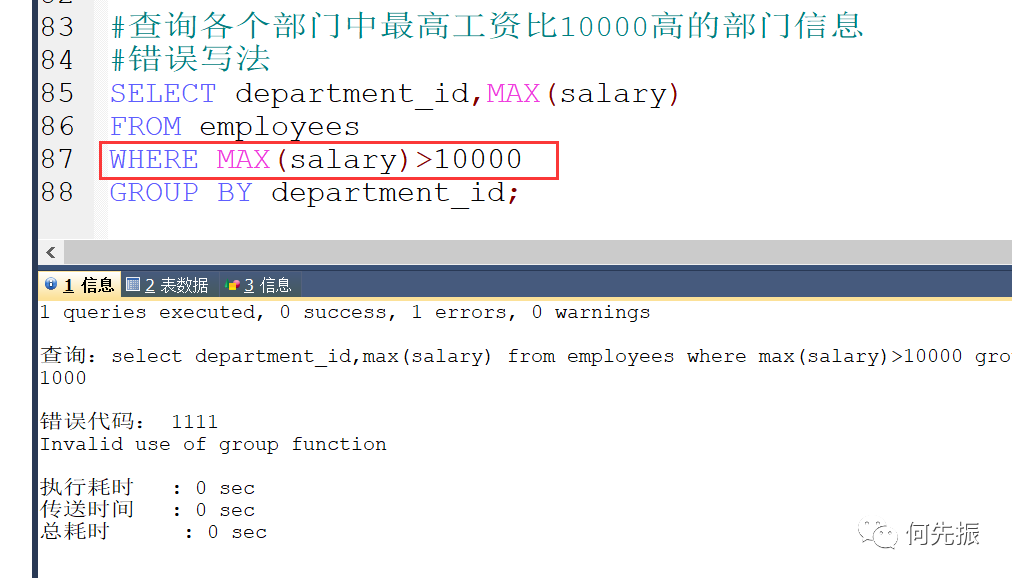
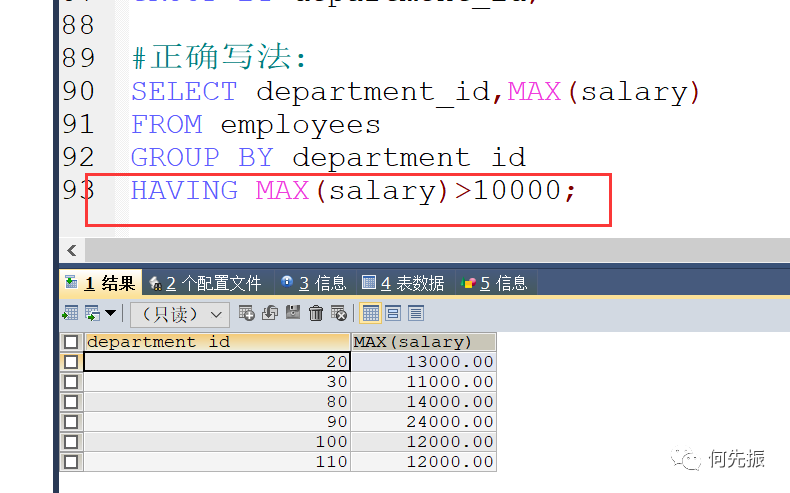
要求:如果过滤条件使用了聚合函数,则必须使用HAVING来替换WHERE。否则会报错。
HAVING 必须声明在 GROUP BY 的后面。
开发中我们使用HAVING的前提是SQL中使用了GROUP BY
查询各个部门中最高工资比10000高的部门信息
错误写法:
正确写法:
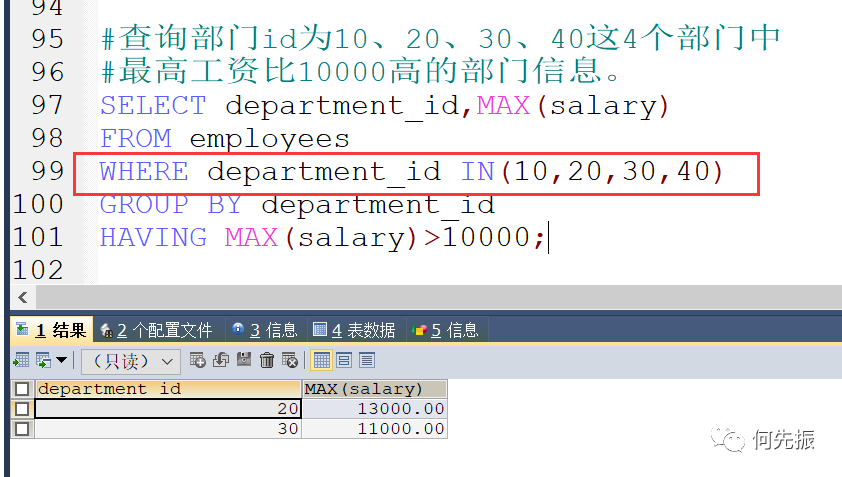
查询部门id为10、20、30、40这4个部门中最高工资比10000高的部门信息。
方式一写法:
方式二写法:
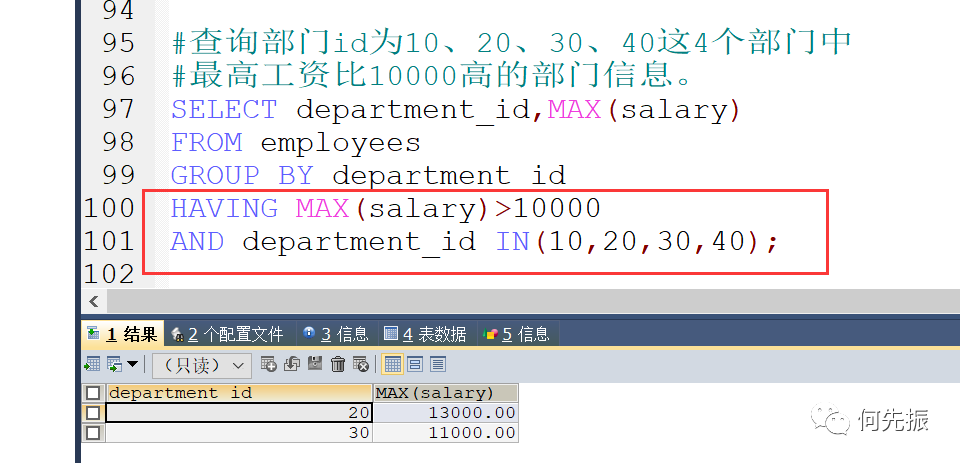
推荐使用方式1,执行效率高于方式2
结论:
当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中。
当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE中或HAVING中都可以,但是,建议大家声明在WHERE中。
WHERE 和HAVING的对比:
从适用范围上来讲,HAVING的适用范围更广。例如支持分组函数的过滤条件,WHERE不支持。
如果过滤条件中没有聚合函数:这种情况下,WHERE的执行效率要高于HAVING。WHERE先筛选后分组,HAVING先分组后筛选。
SELECT 语句的完整结构:
SQL92语法

SQL99语法

SELECT 语句的执行过程:
分序号:

执行过程:
先执行FROM.... ,.....(先是笛卡尔连接)---->on(通过连接条件过滤很多数据)---->(LEFT/RIGHT JOIN) 补一些空的数据--->
再执行WHERE(过滤数据) ----->
再执行GROUP BY(按照哪个数据进行分组) ----->
再执行HAVING(过滤组函数) ----->
最后select 列的过滤---->DISTINCT 去重复数据----> ORDER BY(排序)----->limit( 分页)
可以解释的现象:
WHERE先筛选后分组,HAVING先分组后筛选。所以WHERE效率高。
过滤函数为啥不能用在WHERE这,因为WHERE先于GROUP BY执行前,没有GROUP BY分组是无法使用分组函数的。
别名为什么不能在WHERE条件中使用而可以在ORDER BY中使用?
因为别名是在SELECT中起的,SELECT在WHERE之后,所以WHERE使用时没有别名,所以不能使用别名,
ORDER BY是在SELECT之后的,所以可以使用别名。