以下文章来源于何先振,责编小何

MySQL从8.0版本开始支持窗口函数。
窗口函数的作用类似于查询中对数据进行分组,不同的是,分组操作会把分组的结果聚合成一条记录。而窗口函数是将结果置于每一条数据记录中。
常见的窗口函数:
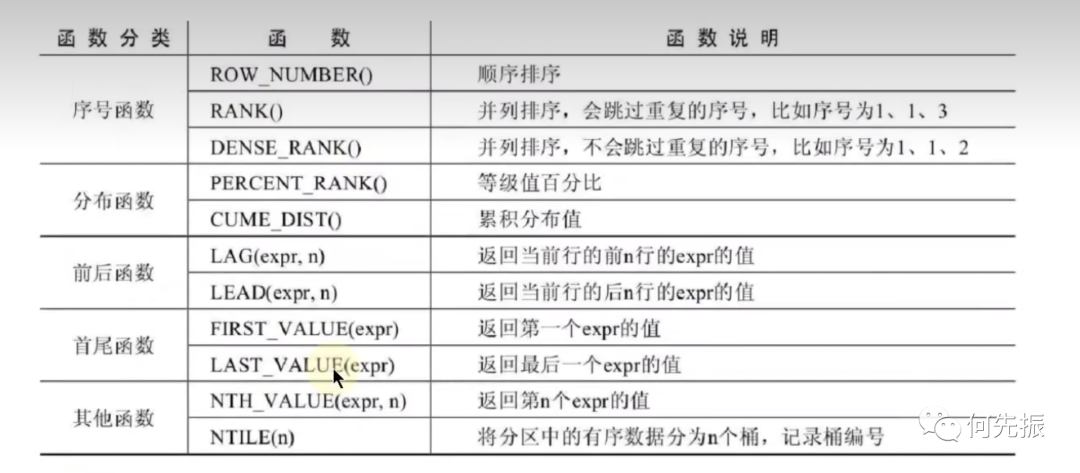
row_number()函数的介绍
举栗子1:
创建商品表
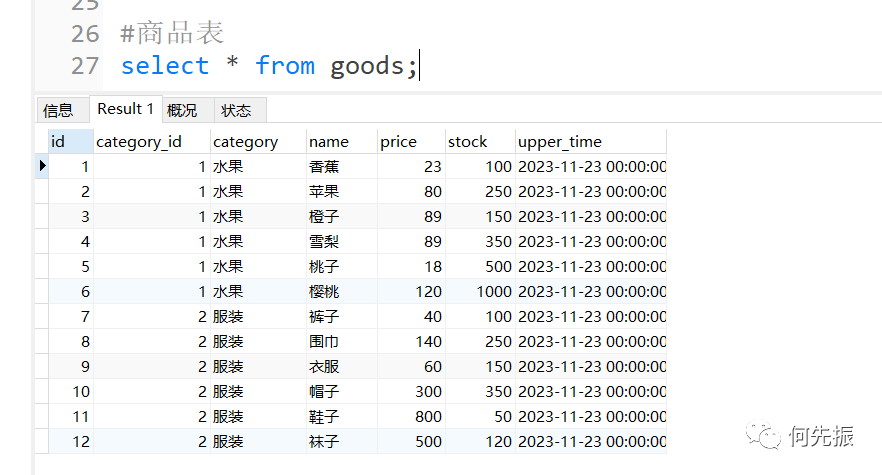
查询goods 数据表中每个商品分类下价格降序排列的各个商品信息。
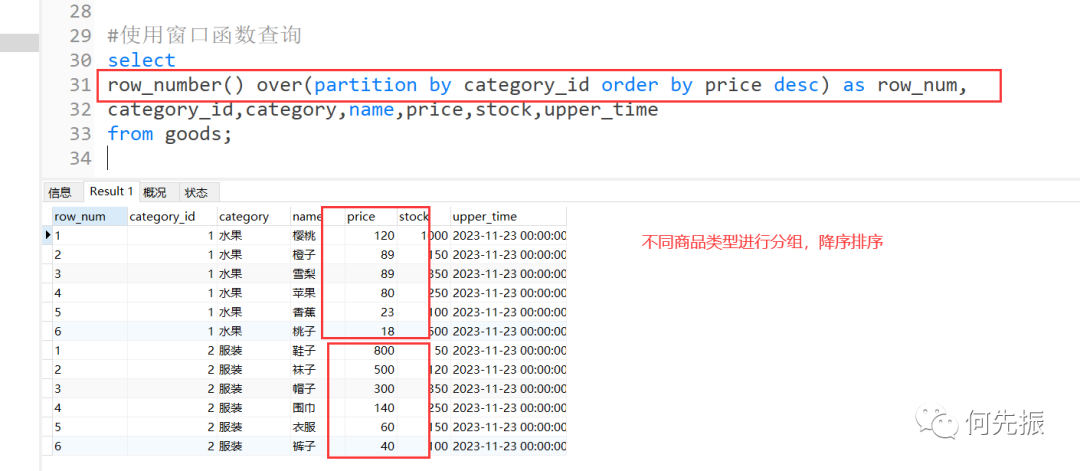
#使用窗口函数查询selectrow_number() over(partition by category_id order by price desc) as row_num,category_id,category,name,price,stock,upper_timefrom goods;复制
row_number()函数,对同一种商品类型标序号。
over(partition by 分类字段 order by 排序字段 排序方式)
举栗子2:
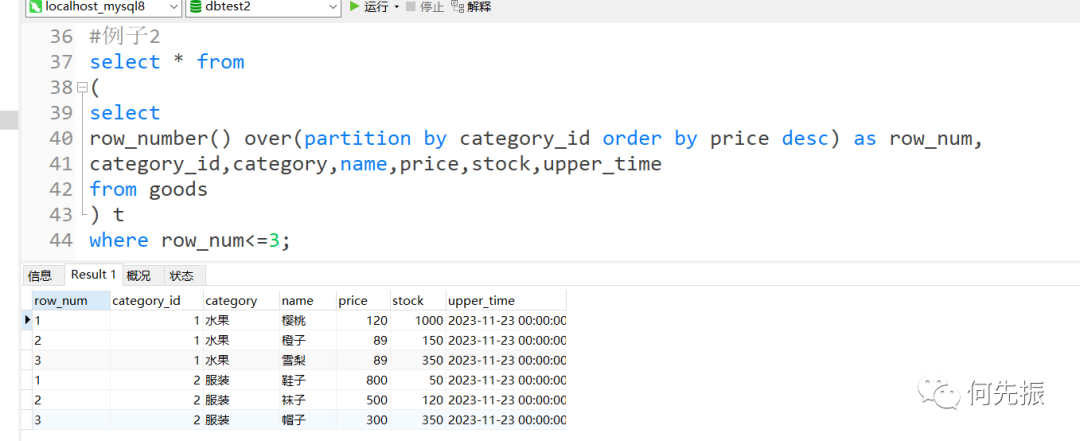
查询商品表中每个商品分类下价格最高的3种商品信息。
select * from(selectrow_number() over(partition by category_id order by price desc) as row_num,category_id,category,name,price,stock,upper_timefrom goods) twhere row_num<=3;复制
rank()函数的介绍
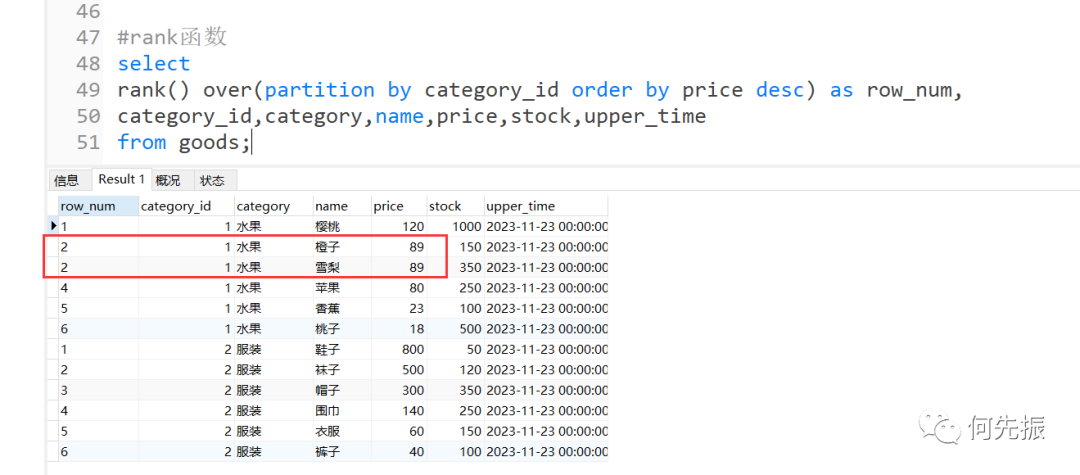
和row_number()函数一样,对同一种商品类型标序号。不同点是排序字段一样的时候序号是一样的。下一个不一样的序号不跟一样的序号连续。
举栗子1:
#rank函数selectrank() over(partition by category_id order by price desc) as row_num,category_id,category,name,price,stock,upper_timefrom goods;复制
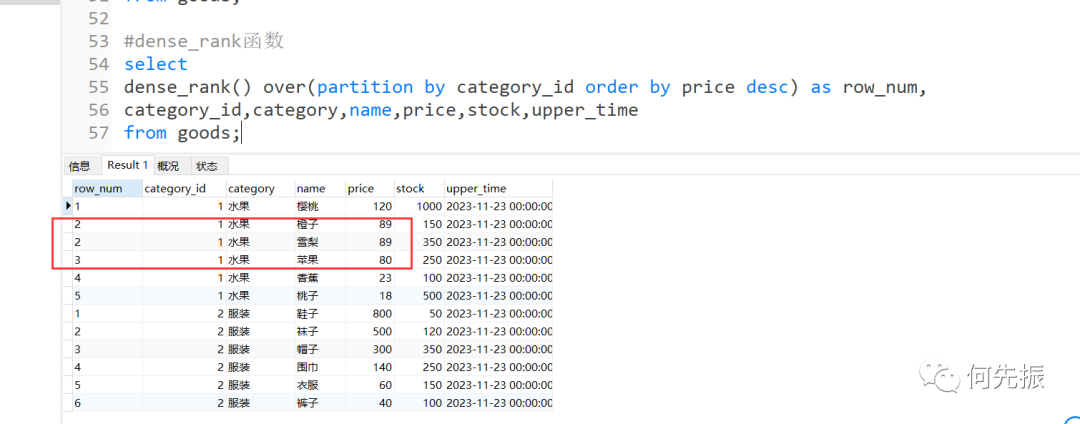
dense_rank()函数的介绍
和rank()函数一样,对同一种商品类型标序号。相同点是排序字段一样的时候序号是一样的。不同点下一个不一样的序号跟一样的序号连续。
percent_rank()函数的介绍
是等级值百分比函数,按照如下方式计算
(rank-1)/(rows-1)复制
其中,rank的值为rank()函数产生的序号,rows的值为当前窗口的总记录数。
举栗子1:
window用于声明一个窗口w(一组数据),这个窗口根据category_id进行分组,价格降序进行排序。
rank()函数统计窗口的序号
percent_rank()函数,计算百分比值。
over关键字,使用声明的窗口w。
select rank() OVER w as r,percent_rank() OVER w as pr,category_id,category,name,price,stock,upper_timefrom goodswhere category_id=1 WINDOW w as (partition by category_id order by price desc);复制
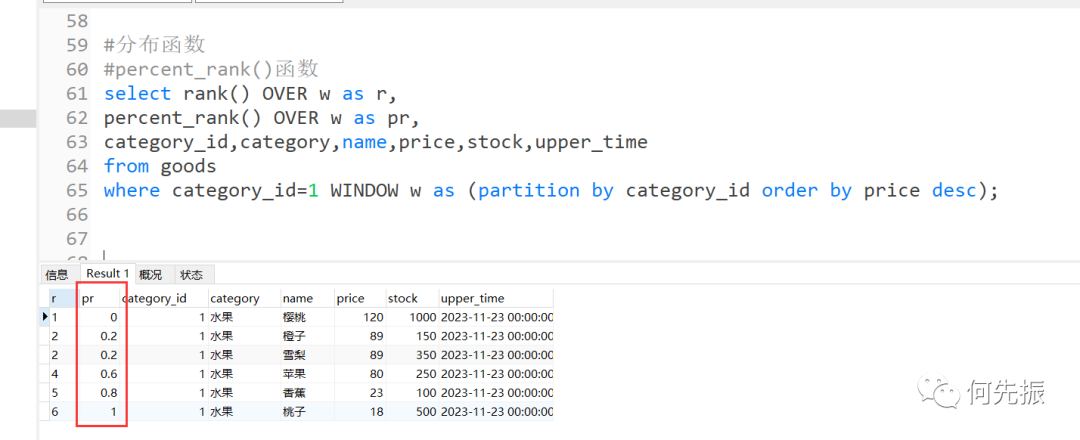
红框中第一行百分比为0,是因为根据百分比的计算公式:1-1/6-1=0
红框中第二行百分比为0.2,是因为根据百分比的计算公式:2-1/6-1=0.2,其中2是r列序号,6是窗口的总记录数为6条数据。
cume_dist()函数的介绍
主要用于查询某个值的比例,降序是小于等于,升序是大于等于。
举栗子:
select cume_dist() OVER w as cd,category_id,category,name,price,stock,upper_timefrom goodswhere category_id=1 WINDOW w as(partition by category_id order by price desc);复制
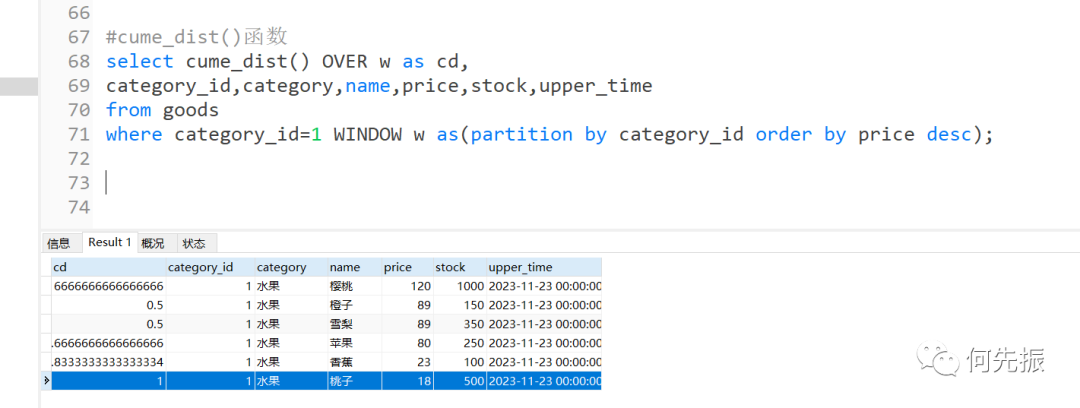
cd列为1是因为当前价格price为18,窗口数据中的所有价格(图中6条记录的价格)都大于或等于这个值,所以为1。
cd列为0.5是因为当前价格的price为89,窗口数据中的所有价格都大于或等于这个值的数据有3条,一共有6条记录所以是0.5。
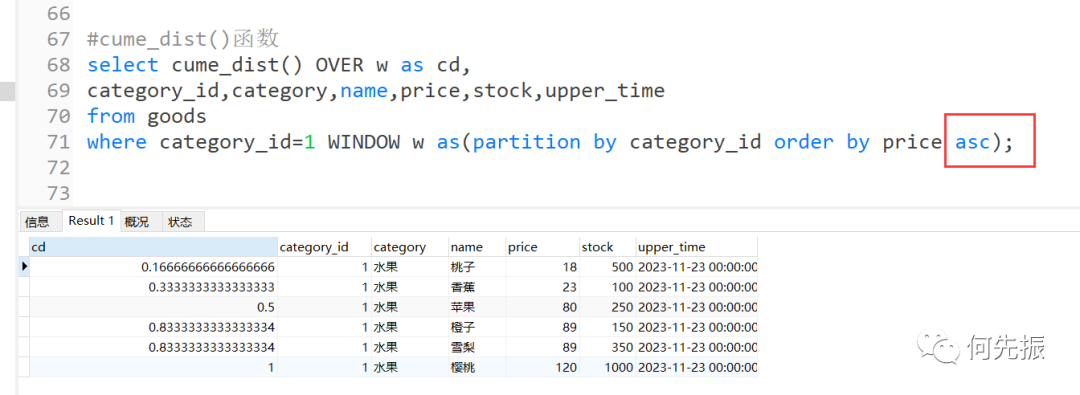
如果改成降序,就是小于或等于。
lag(expr,n) 函数的介绍
返回当前行的前n行的expr值。
举栗子:
selectcategory_id,category,name,price,lag(price,1) OVER w as price_lag,stock,upper_timefrom goodswindow w as(partition by category_id order by price desc);复制
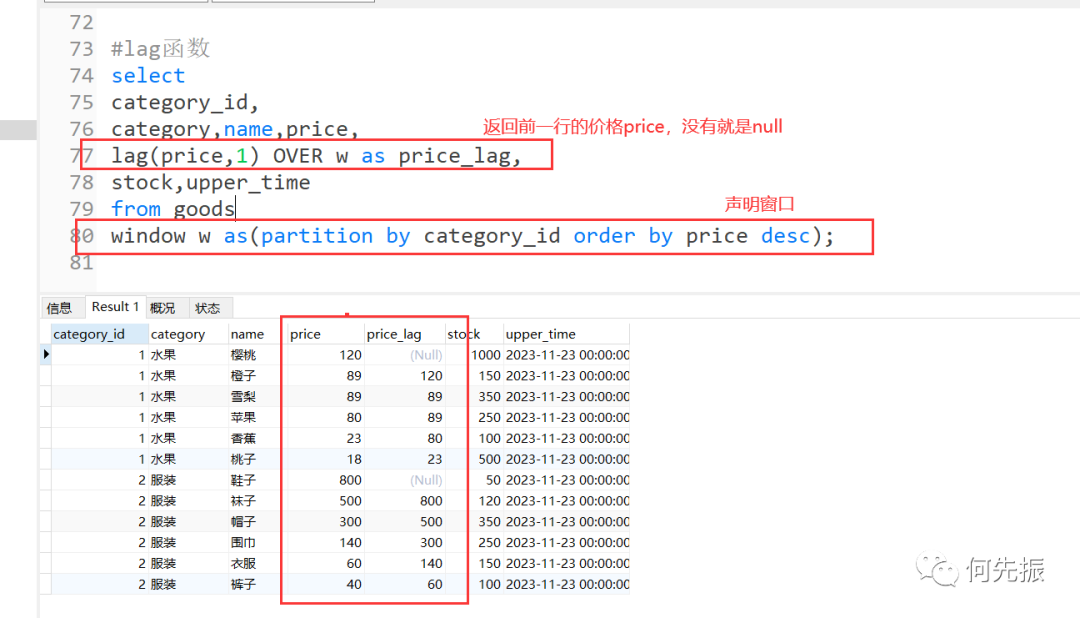
这样封装成一张表,就可以计算前一条数据的价格和当前数据的价格的差值。
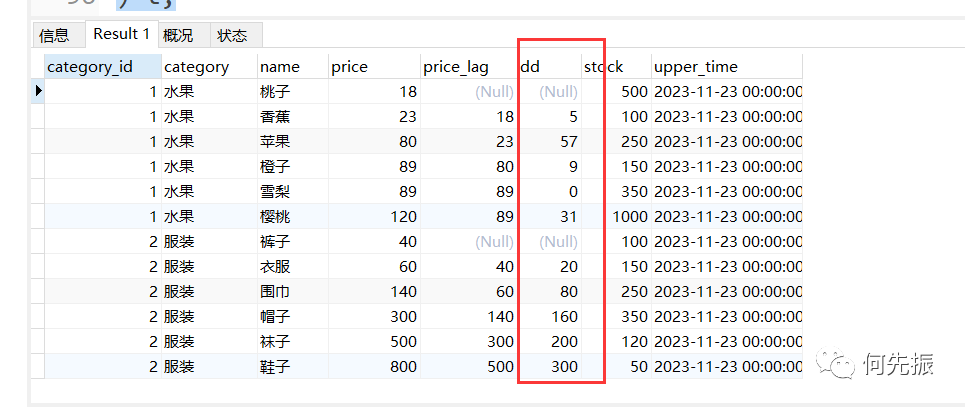
select category_id,category,name,price, price_lag,price-price_lag as dd,stock,upper_timefrom(selectcategory_id,category,name,price,lag(price,1) OVER w as price_lag,stock,upper_timefrom goodswindow w as(partition by category_id order by price asc)) t;复制
lead(expr,n)函数的介绍
返回当前行的后n行的expr值。跟lag函数一样,不同点就是lag函数返回的是当前行的前n行,lead函数返回的是当前行的后n行。
first_value(expr)函数的介绍
返回第一个expr的值,没有时为null。
举栗子:
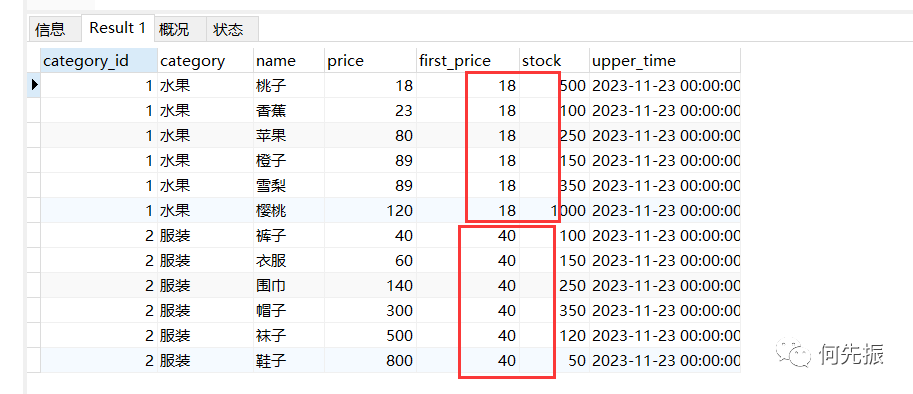
不同窗口的第一个price值。
#first_value函数selectcategory_id,category,name,price,first_value(price) OVER w as first_price,stock,upper_timefrom goodswindow w as(partition by category_id order by price asc);复制
last_value(expr)函数的介绍
跟first_value函数一样,区别是返回最后一个expr的值。
nth_value(expr,n)函数的介绍
返回第n个expr的值,没有时为null
举栗子:
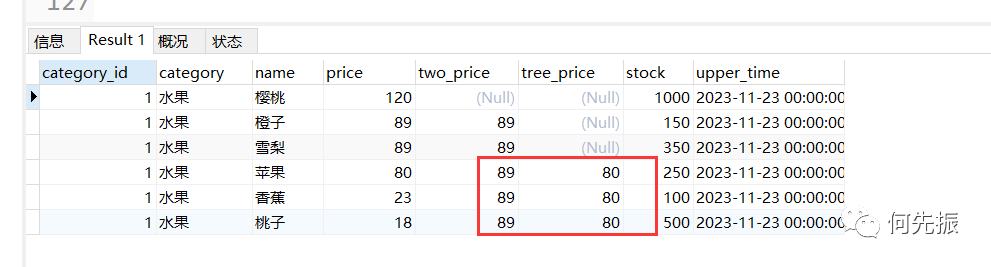
selectcategory_id,category,name,price,nth_value(price,2) OVER w as two_price,nth_value(price,4) OVER w as tree_price,stock,upper_timefrom goodswhere category_id =1window w as(partition by category_id order by price desc );复制
ntile(n)函数的介绍
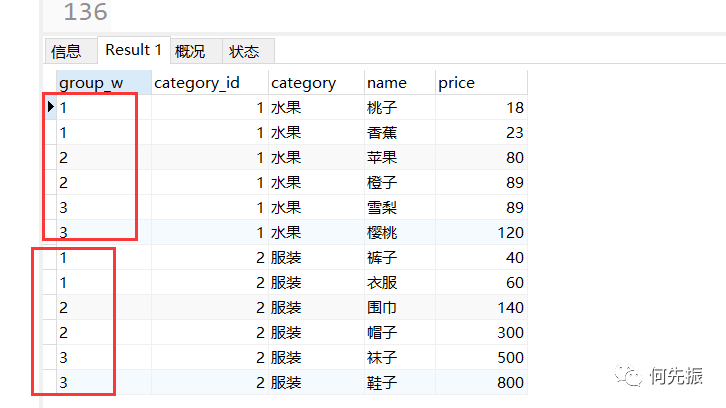
将每个窗体的数据进行分组,记录组的编号。
举栗子:
#ntile函数(n)selectntile(3) over(partition by category_id order by price) as group_w,category_id,category,name,pricefrom goods;复制
窗口函数的特点是可以分组,而且可以在分组内排序。并且不会因为分组减少原表中的数据。