




闲聊
本来不想更的,状态不大对,有点像感冒的意思。。。最近沉迷口琴不能自拔,吹了快一个月,才发现琴上标的1不是真正的1,真正的do是在4上吹,真正的re也不在2上,真正的re是在4上吸气。我说咋吹起来怪怪的。。。
kafka的数据可靠性
Kafka 里边有几种基本角色,每个角色具体职责是什么 Kakfa 为什么那么快? Kafka 里怎么保证高可用性 Kafka 里的 rebalance 是怎么回事,怎么触发 Kafka 怎么保证数据可靠性? 怎么实现 Exactly-Once ? Kafka 选主怎么做的? Kafka 与 rabbitmq区别 Kafka 分区怎么同步的 Kafka 怎么保证不丢消息的 Kafka 怎么避免重复消费 Kafka 为什么可以扛住这么高的qps 还是沿着那个任务条来更。
稍微调整一下问题列表,有很多问题其实有些重叠了,数据可靠性在之前的高可用性里提到过,每个问题回答的侧重点不一样。
数据同步ISR队列
基础概念
在之前高可用那篇提过,kafka的高可用依赖于强大的副本机制,每个topic下有多个partation,其中只有一个被选拔为leader,其他都为follower。
生产者向topic发送数据时,数据只被插入到leader中,其他follower主动向leader拉取数据进行数据同步。
leader为了感知众多follower的同步状态建立一个副本同步队列ISR(In-Sync Replicas),理解同步细节需要先了解一些名词。
HW
:高水位,标识consumer可见的offset,取所有ISR中最小的那个LEO
:partation中日志最大的offset + 1AR
: 所有的分区副本集合ISR
:同步的分区集合,属于AR的一个子集,ISR中如果同步慢了或挂起会被t出ISR队列。
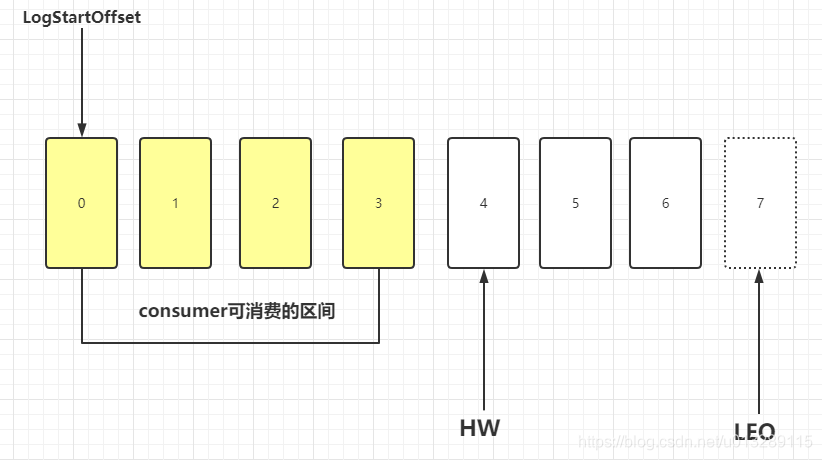
偷几个图,LEO的值永远是大于HW,消费kafka时,并不是producer往kafka写多少,consumer就消费多少。HW是相对于Replica之间而言的,三个Replica,一个leader,两个follower,当producer往kafka发数据时,在消息被写入leader,leader收到数据后会与其它两个follower保存数据同步。
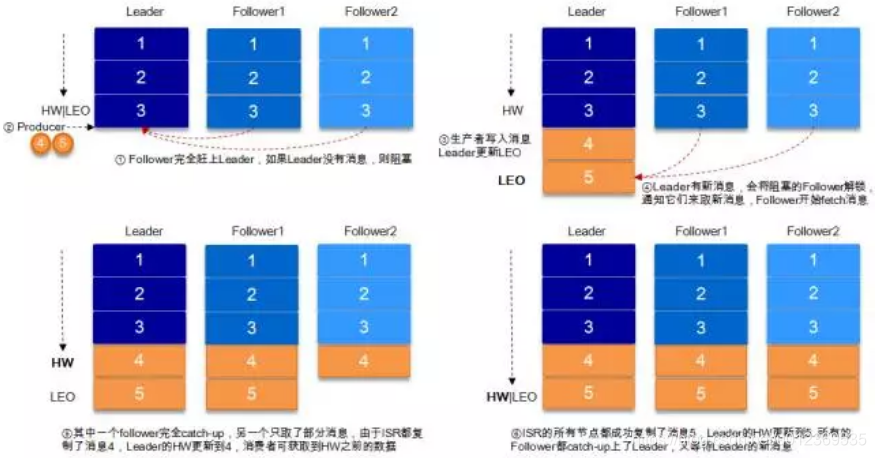
每个 follower的机器都不一样,写入速度也不一致,某一时刻,leader已经写入了5条消息,follow1可能同步了第5条消息,而follow2只同步了4条消息,这时的HW值也就是4,也就是经常说的“木桶效应”,以最低水位的那个follower为准。
选主
topic的某partition有三个副本,分别为A、B、C。A作为leader肯定是LEO最高,B紧随其后,C机器由于配置比较低,网络比较差,故而同步最慢。这个时候A机器宕机,这时候如果B成为leader。
假如没有HW,在A重新恢复之后会做同步操作,在宕机时log文件之后直接做追加操作,而假如B的LEO已经达到了A的LEO,会产生数据不一致的情况
,所以使用HW来避免这种情况。A在做同步操作的时候,先将log文件截断到之前自己的HW的位置,即3,之后再从B中拉取消息进行同步。
如果失败的follower恢复过来,它首先将自己的log文件截断到上次checkpointed时刻的HW的位置,之后再从leader中同步消息。leader挂掉会重新选举,新的leader会发送“指令”让其余的follower截断至自身的HW的位置然后再拉取新的消息。
选主的算法我还没弄明白呢,以后补上
ack应答机制
这个其实已经说过了,就是有三种模式
acks=0
:producer不会等待任何来自服务器的响应。如果当中出现问题,导致服务器没有收到消息,那么producer无从得知,会造成消息丢失由于producer不需要等待服务器的响应所以可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量acks=1(默认值)
:只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应如果消息无法到达Leader节点(例如Leader节点崩溃,新的Leader节点还没有被选举出来)生产者就会收到一个错误响应,为了避免数据丢失,生产者会重发消息.如果一个没有收到消息的节点成为新Leader,消息还是会丢失.此时的吞吐量主要取决于使用的是同步发送还是异步发送,吞吐量还受到发送中消息数量的限制,例如生产者在收到服务器响应之前可以发送多少个消息acks=-1
:只有当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应 这种模式是最安全的,可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群依然可以运行
结束,状态不是很好,有点要感冒的意思,下周见吧~
