




从事数据科学工作的人都知道,机器学习领域往往需要许多丰富的实战经验的沉淀才能够把这件事情做好。当然其实每个领域的工作都是如此。所以对于刚开始接触数据科学的新手来说,需要大量的时间来沉淀实践经验。

AWS AutoGluon旨在解决由于实战经验不足所带来的困扰。AutoGluon将这些最佳实践经验以AutoML的理念制作成了一个简单易用的Python包,并于2019年进行了开源,大大降低了数据科学的入门门槛要求。用户只需知道如何使用三个 Python 函数:Dataset()、fit() 和 predict(),就可以完成绝大部分复杂的模型训练过程。通过AutoGluon我们可以进行包括图像分类、对象检测、文本分类、表格式数据预测等在内的所有类型的深度学习模型训练。
AutoGluon三大Python函数
Dataset()
函数提供类似 pandas 的体验,可进行基础的变量修改操作,同时基于AutoML的能力可实现部分数据预处理工作的自动化实现fit()
函数会自动分析数据集,将数据分为训练集和验证集,并同时进行多个模型的训练和最佳参数的选择,最后将它们组合在一起以生成高精度模型predict()
函数通过新数据生成预测,并生成预测结果和概率
市场主流AutoML工具
除了AWS Autogluon之外也有很多厂家在提供类似的AutoML服务,其中关注度最高、功能最完善的是微软的NNI。目前支持多种框架,并且支持主流的四大功能:feature engineering、hyperparameter tuning、neural architecture search、model compression等等
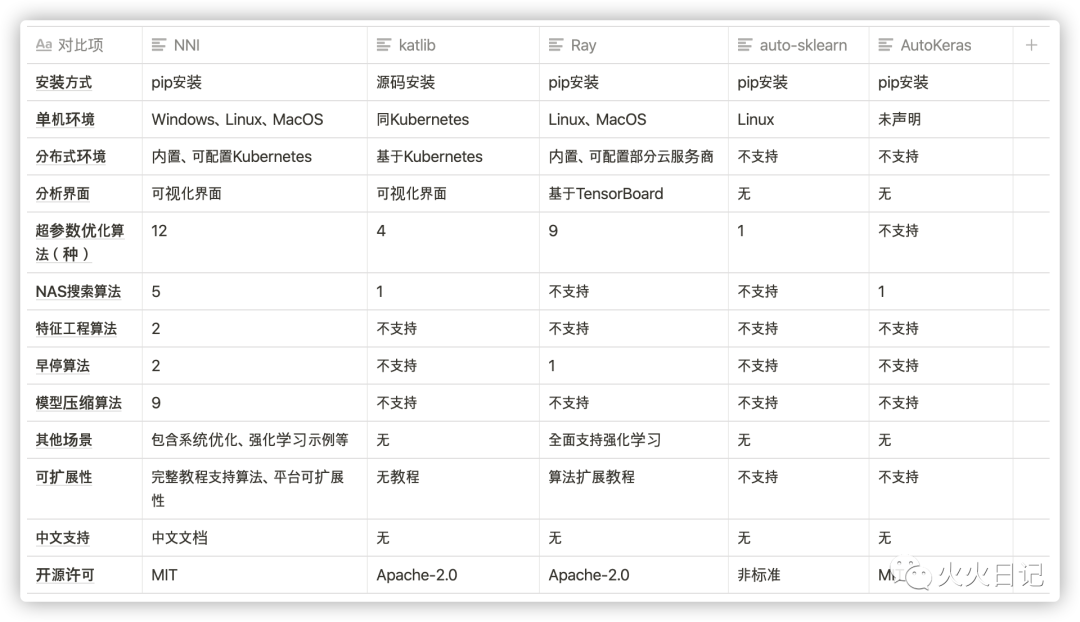
4大主流功能
feature engineering:
特征工程是将原始数据转化为特征,更好表示预测模型处理的实际问题,提升对于未知数据的准确性。它是用目标问题所在的特定领域知识或者自动化的方法来生成、提取、删减或者组合变化得到特征。
简单举个二分类的例来说,输入数据X:身高和体重 ,标签为Y:身材等级(胖,不胖)。显然,不能单纯的根据体重来判断一个人胖不胖,针对这个问题,一个非常经典的特征工程是,BMI指数,BMI=体重/(身高^2)。这样,通过BMI指数,就能非常显然地帮助我们,刻画一个人身材如何。甚至,你可以抛弃原始的体重和身高数据,这就是一个简单的特征工程的例子
hyperparameter tuning:
又可以称之为Hyperparamete Optimization(HO),比较典型的HO框架有Auto-sklearn和Auto-WEKA。比较典型的方法有随机搜索(Random Search)、网格搜索(Grid Search)、贝叶斯优化(Bayesian Optimization)、强化学习(Reinforcement learning)、进化算法(Evolutionary Algorithm)等,解决的是具体模型参数的自动调优问题
neural architecture search(NAS):
注意这里的NAS不是我们熟悉的Network Attached Storage网盘,他是神经网络架构搜索的简称。他是一种自动设计神经网络的技术,可以通过算法根据样本集自动设计出高性能的网络结构,在某些任务上甚至可以媲美人类专家的水准,甚至发现某些人类之前未曾提出的网络结构。解决的是神经网络应该是几层、每一层的算子是什么等问题会通过自动化的方式进行,算是更高阶的AutoML的工作
model compession:
深度学习使得很多计算机视觉任务的性能达到了一个前所未有的高度。不过,复杂的模型固然具有更好的性能,但是高额的存储空间、计算资源消耗是使其难以有效的应用在各硬件平台上的重要原因。为了解决这些问题,模型压缩方法以最大限度的减小模型对于计算空间和时间的消耗。常用的模型压缩方法有参数修剪和共享(parameter pruning and sharing)、低秩因子分解(low-rank factorization)、转移/紧凑卷积滤波器(transferred/compact convolutional filters)、知识蒸馏(knowledge distillation)等
AutoGluon 实操
1. AutoGluon安装
建议使用Anaconda进行Python及Jupyter notebook的安装,pip安装方式会出现jupyter notebook路径与python3路径不一致的问题,导致无法正常导入autogluon Package
*Anaconda安装Python的步骤略过
利用git clone进行安装
brew install libomp
python3 -m pip install --upgrade "mxnet<2.0.0"git clone https://github.com/awslabs/autogluon
pip3环境变量设置
rm -rf /usr/local/bin/pip3ln -s /Library/Frameworks/Python.framework/Versions/3.8/bin/pip /usr/local/bin/pip3
切换到autogluon目录,将安装程序full_install.sh文件进行修改,以pip3的形式进行启动安装
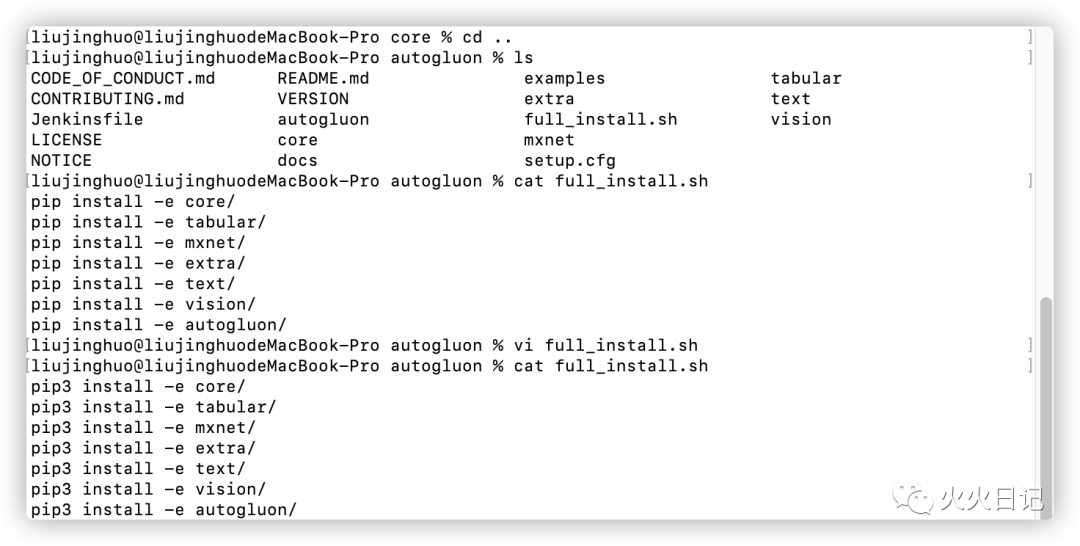
通过如下代码进行安装
./full_install.sh
需要数十分钟安装,安装完毕后可确认如下画面
2. 基于AutoGluon训练图像识别模型
接下来我们通过实际的图像识别场景来了解具体如何调用AutoGluon的API。
首先将已有标签的图像数据加载到notebook环境中,并基于训练数据集和测试数据集训练图像识别神经网络模型。区别于传统的机器学习任务,在传统的机器学习中,我们需要手动定义神经网络,然后在训练过程中指定具体参数。而利用AutoGluon的好处在于,我们只需调用AutoGluon的拟合函数就可以自动训练许多具有不同参数配置的模型,然后在其中选择准确度最高的模型。
首先我们需要打开notebook
jupyter notebook
2.1 导入相关包
导入autogluon相关包
import autogluon.core as agfrom autogluon.vision import ImageClassification as task

2.2 创建数据集
训练数据我们使用Kaggle里的Shopee-IET数据集的一部分数据,训练数据都具有数据标签来描述具体服装的类型,比如 BabyPant,BabyShirt,womancasualshoes,womanchiffontop等等。这些数据已经放到了AWS S3 Bucket中,我们可以直接进行数据下载。
下载数据并进行解压缩
filename = ag.download('https://autogluon.s3.amazonaws.com/datasets/shopee-iet.zip')ag.unzip(filename)
执行后有可能会出现如下报错
该报错是由于anaconda安装时,未能安装ipywidgets包或者版本过低导致的
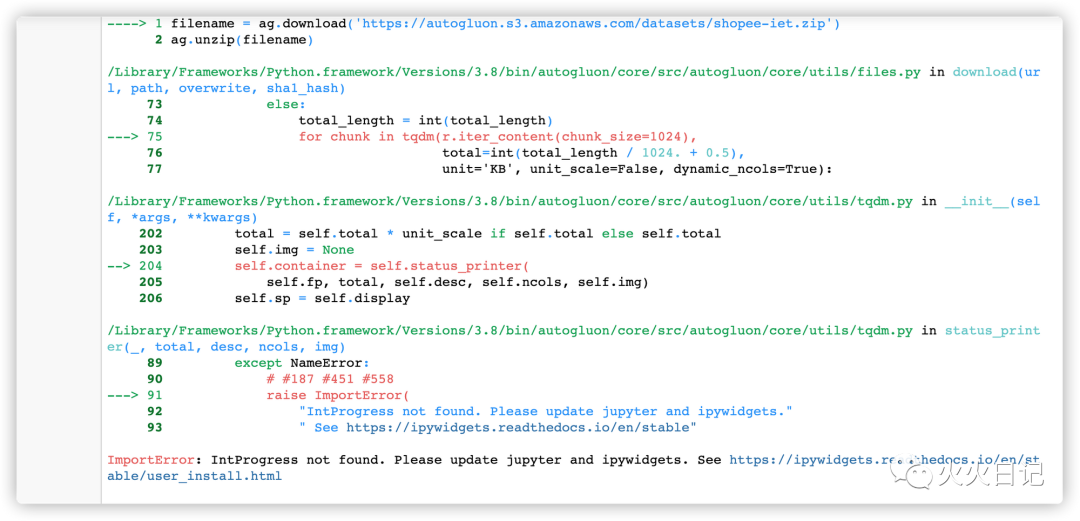
需要安装ipywidgets
! pip3 install ipywidgets
进行激活操作
! jupyter nbextension enable --py widgetsnbextension

数据重新进行下载和解压
filename = ag.download('https://autogluon.s3.amazonaws.com/datasets/shopee-iet.zip')ag.unzip(filename)

生成训练数据集
dataset = task.Dataset('data/train')
生成测试数据集
test_dataset = task.Dataset('data/test', train=False)
为了提高训练效率,我们将图片数据变更为FashionMNIST数据集
MNIST:一个入门级的计算机视觉数据集,考虑到CPU的计算性能问题,我们把图片变更为入门级手写图片格式,提高训练效率
if ag.get_gpu_count() == 0:dataset = task.Dataset(name='FashionMNIST')test_dataset = task.Dataset(name='FashionMNIST', train=False)
2.3 训练模型
下面通过AutoGluon进行模型训练
epoch一次epoch是指将所有数据训练一遍的次数,即训练的模型数量
ngpus_per_trial每个试验中要使用多少个GPU, 设定为“None”时将由AutoGluon自动确定
verbose在模型训练过程中是否打印出中间过程信息
classifier = task.fit(dataset,epochs=5,ngpus_per_trial=None,verbose=False)
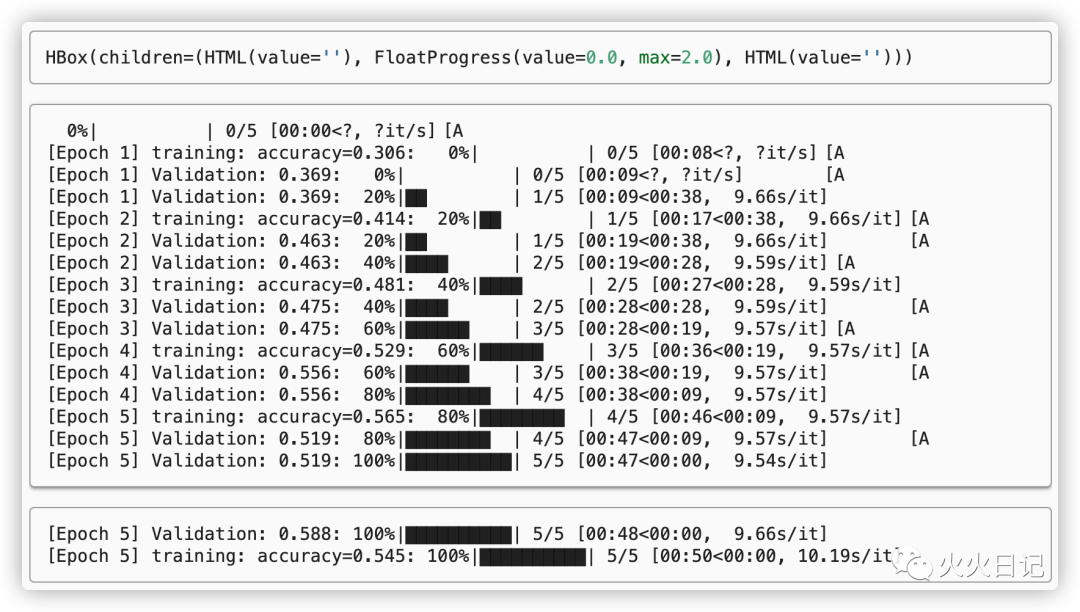
在训练过程中数据集会自动分为训练集和验证集。根据验证集中的性能变化,系统会自动选择最佳参数配置。然后系统会把这个最佳参数运行到整个数据集(训练集+验证集)上进行交叉验证。
如上图系统自动跑出了5个不同的模型,我们可以选出准确率最高的模型
print('Top-1 val acc: %.3f' % classifier.results['best_reward'])

2.4 识别新图片
利用已训练的模型,我们可以来识别新的图片(无标签)数据,生成预测标签以及预测概率
# 识别BabyShirt和Womenchiffontop两张图片,将两个图片的识别结果进行输出if ag.get_gpu_count() > 0:image = 'data/test/BabyShirt/BabyShirt_323.jpg'ind, prob, _ = classifier.predict(image, plot=True)print('The input picture is classified as [%s], with probability %.2f.' %(dataset.init().classes[ind.asscalar()], prob.asscalar()))image = 'data/test/womenchiffontop/womenchiffontop_184.jpg'ind, prob, _ = classifier.predict(image, plot=True)print('The input picture is classified as [%s], with probability %.2f.' %(dataset.init().classes[ind.asscalar()], prob.asscalar()))


2.5 模型评估
下面将模型试用到测试数据集中,进行准确性评估
test_acc = classifier.evaluate(test_dataset)print('Top-1 test acc: %.3f' % test_acc)

以上是今天的内容,谢谢大家~
