




业务方找到我们咨询,有一个sql要跑10分钟左右,有点不能接受,经查看使用了dblink进行了跨库查询,并且执行计划确实没有走相应的索引,后使用driving_site的hint解决问题
由于业务SQL需要保密,这里自己创建的相应的表和索引进行场景的模拟
12c 12201 环境 创建连接到11g环境的dblink
SQL> CREATE public DATABASE LINK zwy11g CONNECT TO zwy11g IDENTIFIED by "123" USING '11g';
Database link created.
11g 环境 创建表 以及索引
SQL> create table zwy11g.zwy_test1 as select * from dba_objects;
Table created.
SQL> SQL> create index zwy11g.id_1 on zwy11g.zwy_test1(object_id);
Index created.
12c 环境 创建表 索引
create table zwy.zwy12c_test1 as select * from dba_objects;
create index zwy.zwy12c_id on zwy.zwy12c_test1(object_id);复制将业务SQL的逻辑转换为测试表对应的SQL
select a.object_id,a.object_name from zwy.zwy12c_test1 a,zwy_test1@zwy11g b where a.object_id=b.object_id and a.owner=b.owner and b.object_id=10000;复制业务场景为连接列有索引,并且A表是小表只有几百MB,B表是dblink连接的远端的大表有20G的大小,但是经由索引过滤,应该返回的结果集很小,乃至整个SQL运行的很快才对。
但是经由查看,远端的SQL执行计划走的是全表扫描,执行逻辑是先将20g大小的B表全表扫描后拿到本端进行过滤,再加上查看当时的网络流量确实很大,感觉确实不太合理,遂想将执行步骤调整为先在B表上过滤后得到的结果集再和A表进行连接,然后就使用了本案例的hint的driving_site
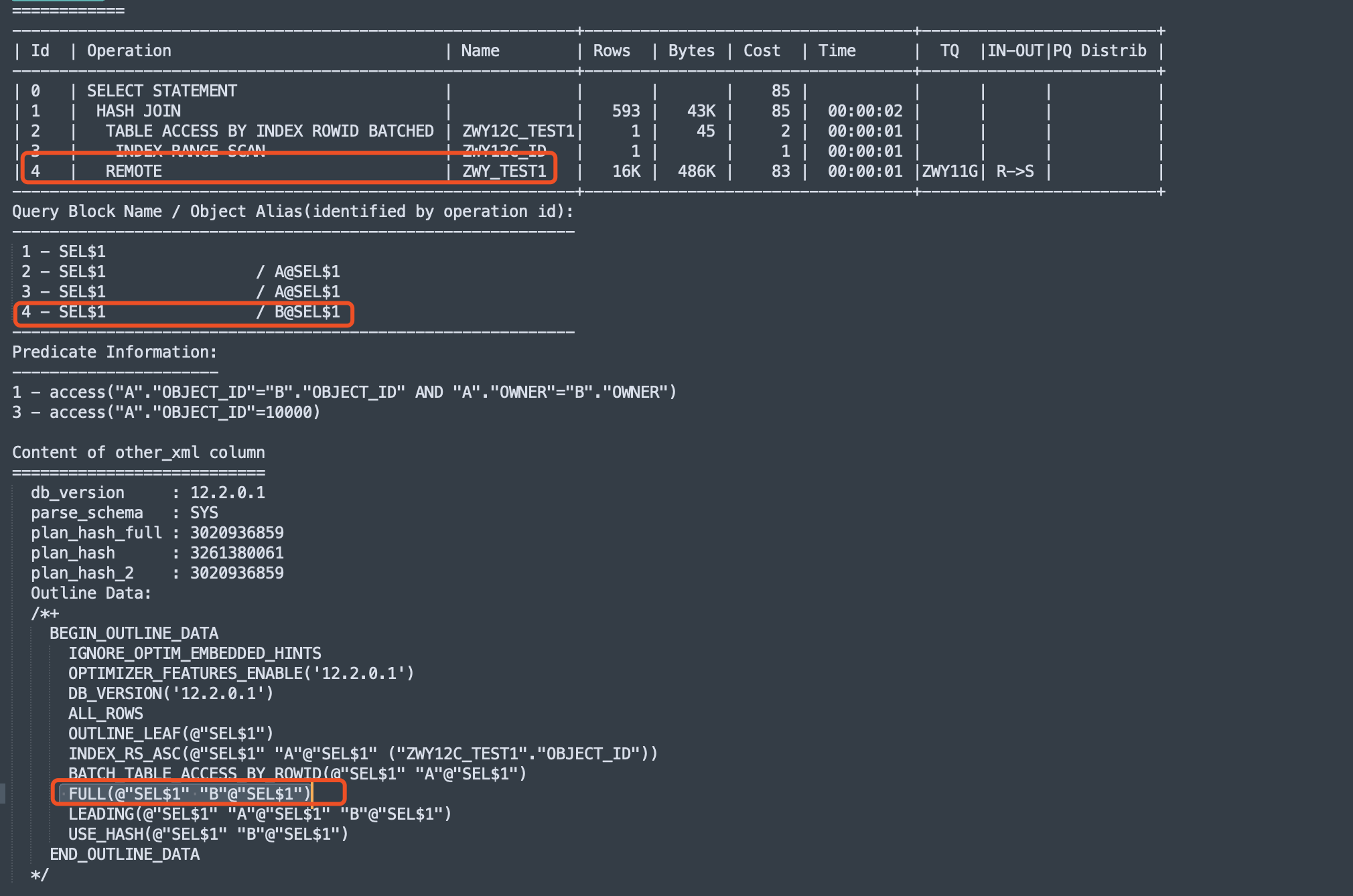
可以看到源SQL的执行计划中 id=4走的是该表的FULL全表扫。并且总体的cost为85.
加上driving_site hint后的执行计划
select /*+ driving_site(b)*/ a.object_id,a.object_name from zwy.zwy12c_test1 a,zwy_test1@zwy11g b where a.object_id=b.object_id and a.owner=b.owner and b.object_id=10000;复制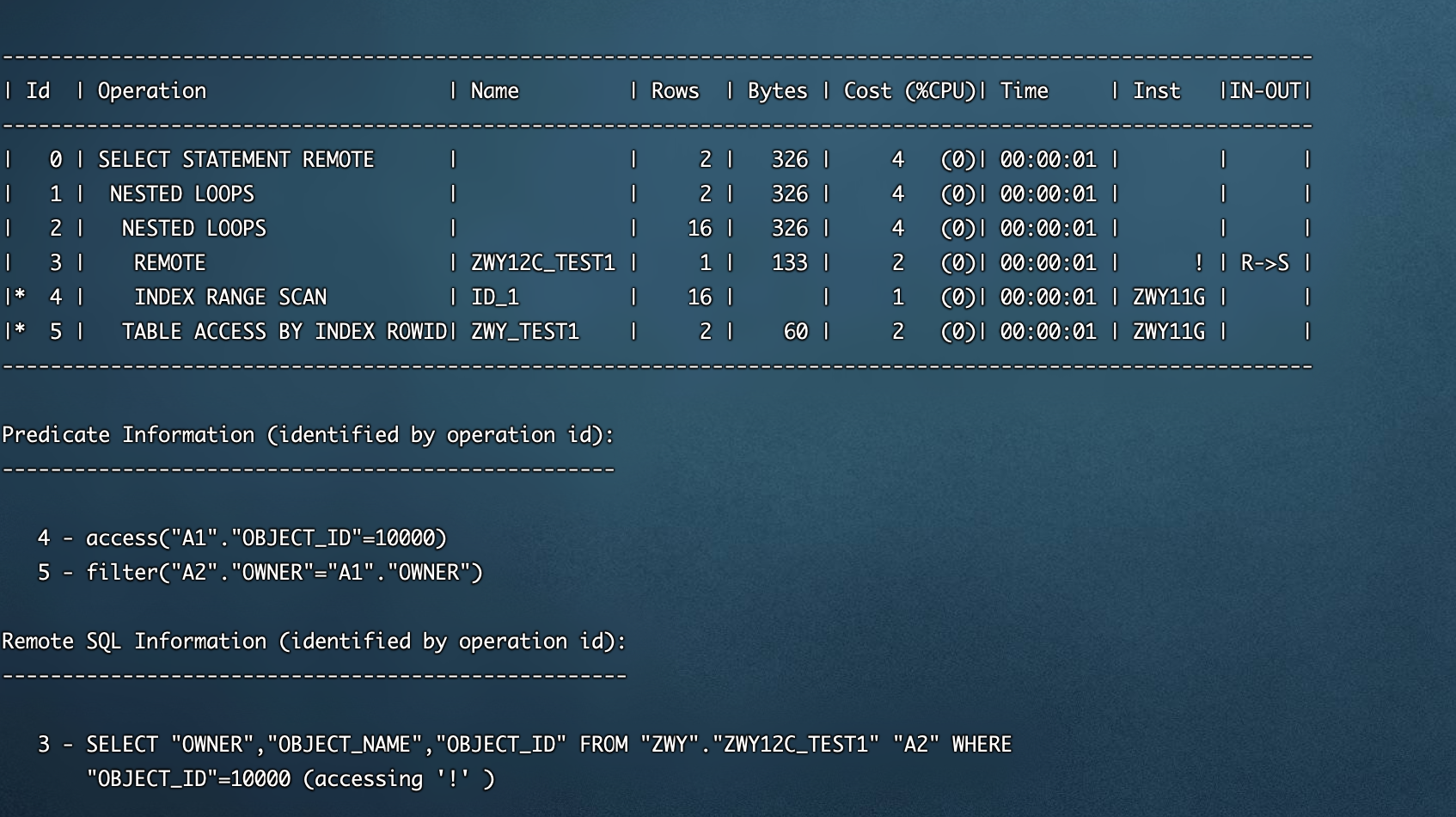
可以看到执行计划步骤变为:先在B表所在的远端进行驱动过滤后,将结果集传输到本端进行连接。cost从85降到了4,而当时的业务执行SQL从10分钟优化到秒出.
driving_site hint作用是指定执行计划具体是在远端数据库还是本地数据库做,当本端为小结果集,远端数据库为大结果集,但最终结果集较小时,我们期望执行计划能够在远端经过谓词条件驱动过滤后得到的小结果集传输到本地,从而避免了大结果集的网络传输,最终提高SQL执行效率。
最后修改时间:2021-11-23 15:41:30
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
墨天轮福利君

3年前
评论
 0
0您好,您的文章已入选合格奖,10墨值奖励已经到账请查收!
❤️我们还会实时派发您的流量收益。
3年前
点赞 评论
相关阅读
【纯干货】Oracle 19C RU 19.27 发布,如何快速升级和安装?
Lucifer三思而后行
786次阅读
2025-04-18 14:18:38
Oracle RAC 一键安装翻车?手把手教你如何排错!
Lucifer三思而后行
664次阅读
2025-04-15 17:24:06
Oracle数据库一键巡检并生成HTML结果,免费脚本速来下载!
陈举超
591次阅读
2025-04-20 10:07:02
【ORACLE】你以为的真的是你以为的么?--ORA-38104: Columns referenced in the ON Clause cannot be updated
DarkAthena
548次阅读
2025-04-22 00:13:51
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
532次阅读
2025-04-17 17:02:24
【ORACLE】记录一些ORACLE的merge into语句的BUG
DarkAthena
510次阅读
2025-04-22 00:20:37
一页概览:Oracle GoldenGate
甲骨文云技术
496次阅读
2025-04-30 12:17:56
火焰图--分析复杂SQL执行计划的利器
听见风的声音
470次阅读
2025-04-17 09:30:30
OR+DBLINK的关联SQL优化思路
布衣
382次阅读
2025-05-05 19:28:36
3月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
382次阅读
2025-04-15 14:48:05



