





数据库系统中缓存的常见策略
在计算机系统中,计算任务都需要把数据先存储在内存中,再由 CPU 来调度计算任务,而每次加载数据到内存会引入额外的开销。另外,在实际的应用场景中,数据被访问的频率也是不一样的,有些数据在一段时间内被重复访问,有些数据则在这段时间内不被访问或者很少被访问。为了减少重复加载数据的开销,大部分数据库厂商都选择用内存缓存来存储已经被访问的一些数据,如果这些数据在有效期内被请求,就从缓存系统里取出数据,而不是从存储层再查询一遍数据。目前主流的数据库厂商都提供内存缓存的功能,例如 Oracle 的 Buffer Pool 等,还有一些内存数据库实现了基于内存的存储方案(内存数据库)。总体来看,基于内存的访问可以减少了磁盘操作,加快数据的查询和计算。以下是一些数据库系统在内存中的实现技术:
Oracle Buffer Pool
Oracle 的 Buffer Pool 的实现包括三个部分:keep pool 用来缓存一直被使用的数据;recycle pool 用来缓存大的数据字段;default pool 用来缓存其他各种类型的数据。 MySQL Buffer Pool
MySQL 的 Buffer Pool 存储数据页,主要目的是减少磁盘 IO 的次数。当要访问的数据页不在缓存中时,会从磁盘中把请求的数据页加载到内存中(Mysql 还有预读机制的实现:顺序预读和随机预读)。因为缓存空间是有限的,Mysql 中使用 LRU list 来换出“老旧”的数据页;对于脏页,则放在 Flush list 中批量刷盘(这里比较有意思的是 Mysql Innodb 的双写机制)。 Memgraph
Memgraph 是一个内存图数据库,它将图的所有数据加载到内存中以加快图算法的执行。如果图的大小超过了内存限制,Memgraph 会开始拒绝新的写请求。 RedisGraph RedisGraph 是 Redis 内嵌的内存图数据库,它使用稀疏矩阵来保存边的信息(CSR_matrix),支持图的快速遍历。因此 RedisGraph 对所有的点和边进行统一的编号(Global ID),用稀疏矩阵来保存点/边类型和边,用 GraphBLAS 进行图算法的计算。
ArcGraph 中对缓存系统的需求
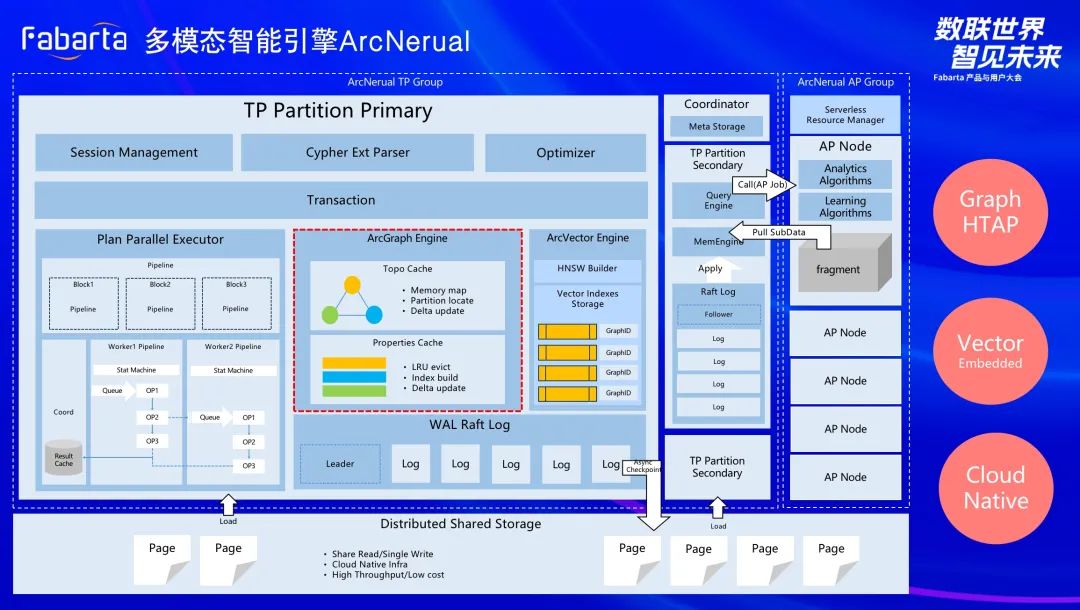
计算型任务需要缓存图来加速查询。
在目前的系统中,对点、边、拓扑信息的查询,都是通过存储引擎的接口进行查询,底层可能访问数据库或者文件,会有磁盘 IO 的开销。目前主流的数据库系统都提供内存缓存的功能,比如 Oracle,MySQL 等。还有一些内存数据库的厂商实现了基于内存的存储方案。基于内存的访问可以减少磁盘 IO 的操作,从而大大提高数据的查询效率。在图的数据存储中,点和边的存储可能比关系型数据库的存储更加分散,如果只提供磁盘访问的借口,可能会造成大量的物理页访问。这也促使我们选择内存缓存的方式保存图的数据。
事务处理中需要在内存中保存数据的版本信息,加速存储任务。
MVCC ( Multi-Version Concurrency Control)
Read Committed 和 Repeatable Read 隔离级别 为什么选择自己开发缓存系统,而不是引入开源项目呢?
可以更好地适配查询引擎的实现,定义更契合查询算子的数据结构。
可以更好地支持查询算法,定制更高效的访问接口。
充分利用 Rust 语言来实现支持高性能高并发的缓存系统。
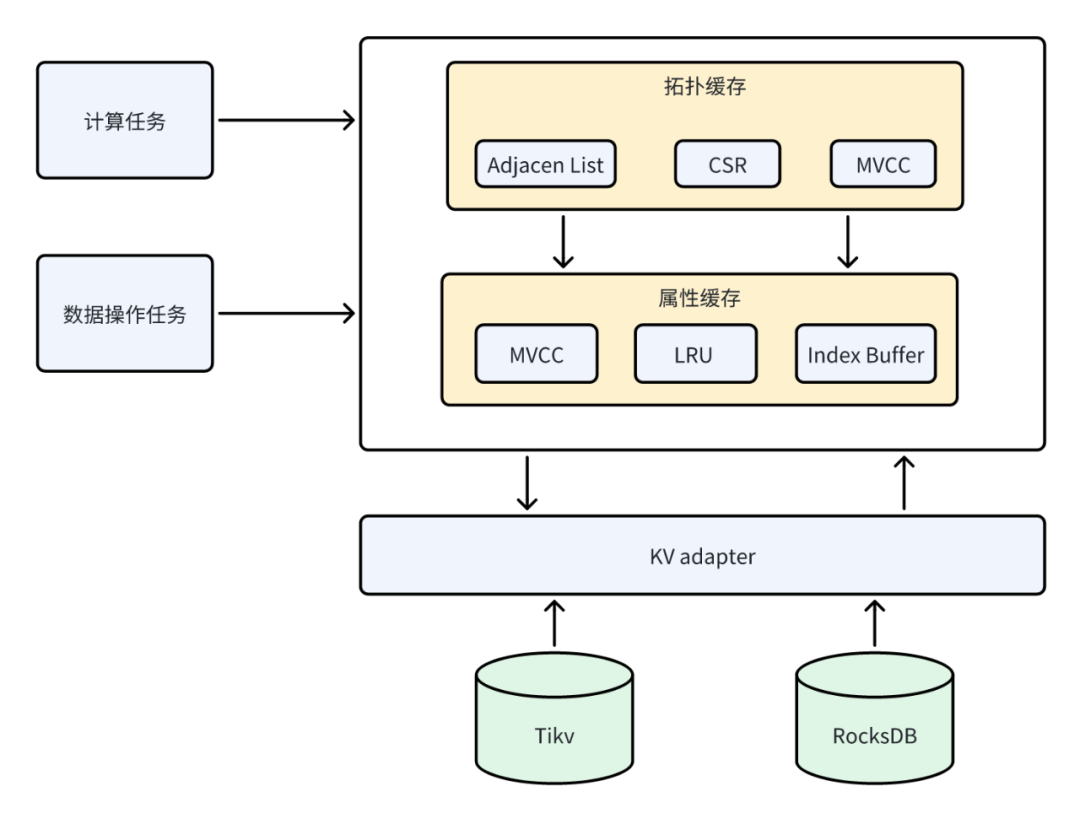
ArcGraph MemEngine 原理
单机和分布式灵活部署
MemEngine 既能部署在单个机器上,也能直接部署在有多台机器组成的集群中。 拓扑数据和属性数据分离
在图的查询计划中,相比较于点/边的属性,拓扑数据(点和边的关系图)被更频繁地使用。为了更好地支持查询计划的执行,我们把本地所有点/边的关系图(拓扑图)加载到缓存中,而对点/边的属性,有选择地加载一部分或者全部不加载(由配置参数控制)。
Q:为什么不用同一个缓存来同时保存拓扑数据和属性数据呢?
A:出于以下几个方面的考虑:更方便地控制缓存的大小;拓扑数据比属性数据更“热”。 MVCC
ArcGraph 默认是支持分布式事务的,对于事务中修改过的数据,需要先在保存在 MemEngine 中,并且支持计算引擎访问这些数据,直至事务数据落盘后才可以从内存中移出这些数据。
ArcGraph MemEngine 实现
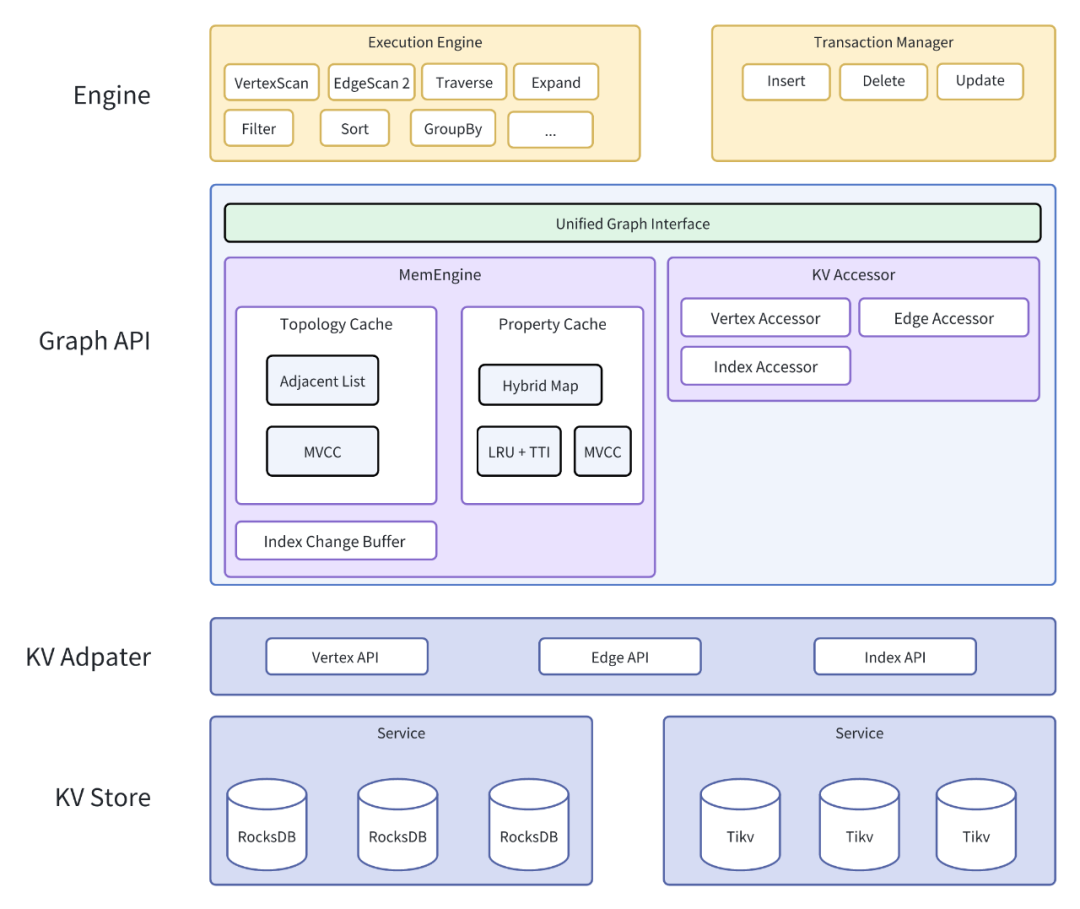
MemEngine 完全用 Rust 实现,按照图进行缓存,暂不支持跨图的访问。同时根据数据的特征,将数据分为拓扑数据(包括点和边图中的关系)和属性缓存(点/边的属性)。
拓扑缓存
拓扑缓存包含当前图中所有点和边的关系,主要用来支持图的遍历,包含
查找指定的点/边
查找指定类型的点/边
查找指定点的 1 度或者 n 度关系或邻居
属性缓存
Property Graph Model 属性缓存支持缓存以 Property Graph Model 构建的图中的边和边的属性。点和边的属性值一般当作“温”数据来处理,即指将最近频繁使用的数据加载在内存中,而对其他属性值则不加载,从而节省内存的开销。
目前我们只支持点/边级别的所有属性,没有对属性集中的列进行冷热分类。
LRU + TTI 的特性
在实际的生产活动中,图中存在数据规模庞大的点和边,这些点和边的属性显然不能全部放入内存中,因为我们使用一定的缓存策略来管理内存中的属性值。例如我们默认的缓存策略是一种复合侧露:LRU(Least Recently Used)+ TTI(Time To Idle)。
为什么会选择这种组合呢?先来看一下各种策略在缓存中的应用。
LRU 设定一个最大缓存容量的阀值,在内存中只保留温热的数据。如果实际数据超过了缓存的最大阀值,就会将最“老”的数据换出缓存,然后把新数据插入。另外一种策略 LFU(Least Frequently Used,通过统计数据的使用频率来进行换入换出决策。 是不是有 LRU 就足够了呢?答案是否定的。LRU 策略下,如果没有新的数据插入到缓存中,缓存中的数据会一直驻留在内存中,这就造成了资源的浪费。这时我们引入一种补偿策略——TTI,即如果缓存中的一条数据在指定时间内没有被访问过,就把它换出内存。这样就解决了数据一直驻留在内存中的问题。
MVCC
从上面缓存的设计图中我们可以看到,在 MemEngine 中 MVCC 包含两个部分,一部分在拓扑缓存中,一部分在属性缓存中。在拓扑缓存中,当我们插入或者删除一个点/边时,都会在 TopoCacheEntry 中添加对应点/边的 Delta 数据(包含点/边在拓扑图上可见性的记录),同时也 PropertyCacheEntry 中添加包含属性值版本的 Delta 信息;当修改一个点的属性值时,我们只保存属性缓存中这部分的 delta 记录。
Q:这样做的好处和缺点?
索引数据
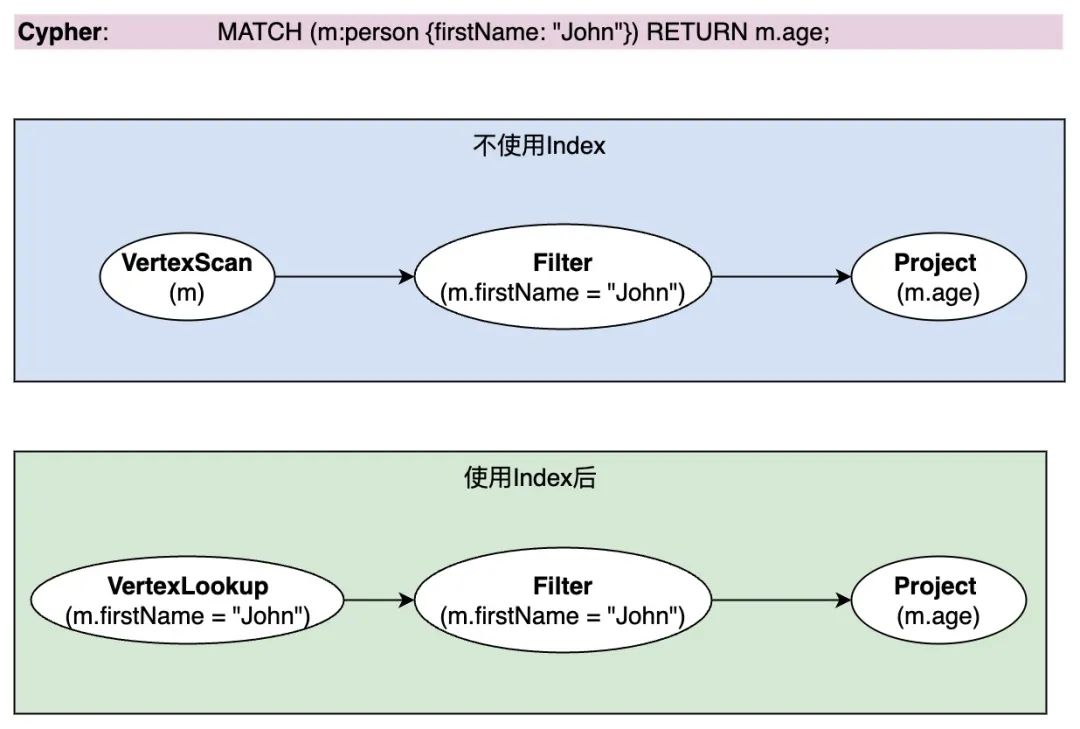
如果没有在点类型 person 的属性 firstName 上创建索引,查询计划会扫描所有类型为 person 的点,然后拿这些点的 firstName 属性值跟指定值(“John”)比较并过滤,时间复杂度为 O(n)。
当在点类型 person 的属性 firstName 上创建索引后,查询计划会直接用“John”这个字符串值在指定的索引上进行操作,根据索引算法的实现,时间复杂度为 O(1)或者 O(logn),查询计划效率的提升很明显。
向量数据
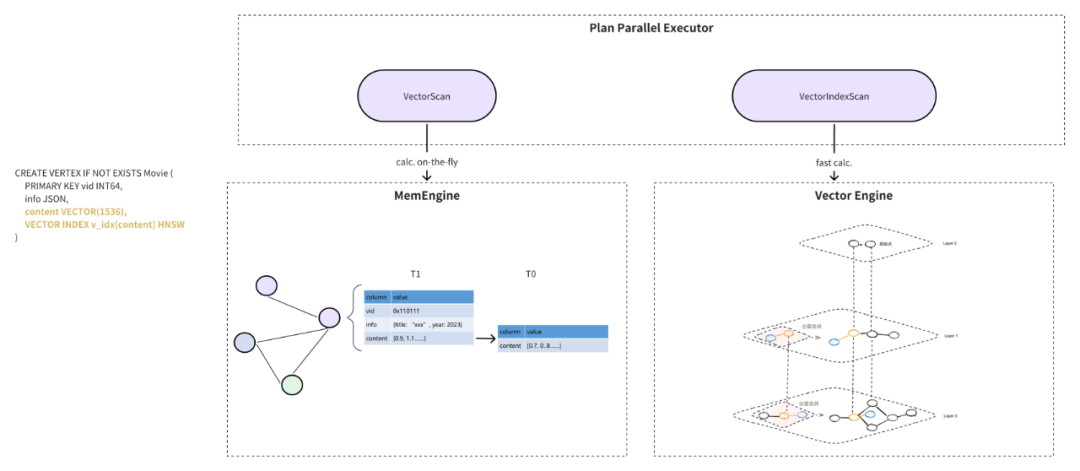
总结
如对我们的产品或技术感兴趣,欢迎通过 business@fabarta.com与我们联系。也可以点击阅读原文,了解更多我们的产品与解决方案信息。

本文作者
INTRODUCTION

乔云从
Fabarta ArcGraph 架构师
负责 Fabarta ArcGraph 的查询处理器、表达式计算、内存引擎等模块的设计和实现。长期从事数据库内核开发工作,曾负责 SAP HANA 和 SAP ASE 查询优化器和执行引擎中多个功能的设计和开发。
推荐阅读


 点击阅读原文了解更多信息
点击阅读原文了解更多信息