





这个是事后的监控图
快中午的时候,被客户群消息淹没。反馈所有业务动作都变得很慢。
一、恢复故障
运维登陆服务器监控。发生一台数据库实例如上图,CPU与内存双双被打满
基于事故先恢复后排查的原则,运维kill了 大量执行时间很长的SQL,Kill后,CPU与内存都迅速恢复,业务恢复正常。
一、排查故障原因
业务恢复正常后,就是排查工作了
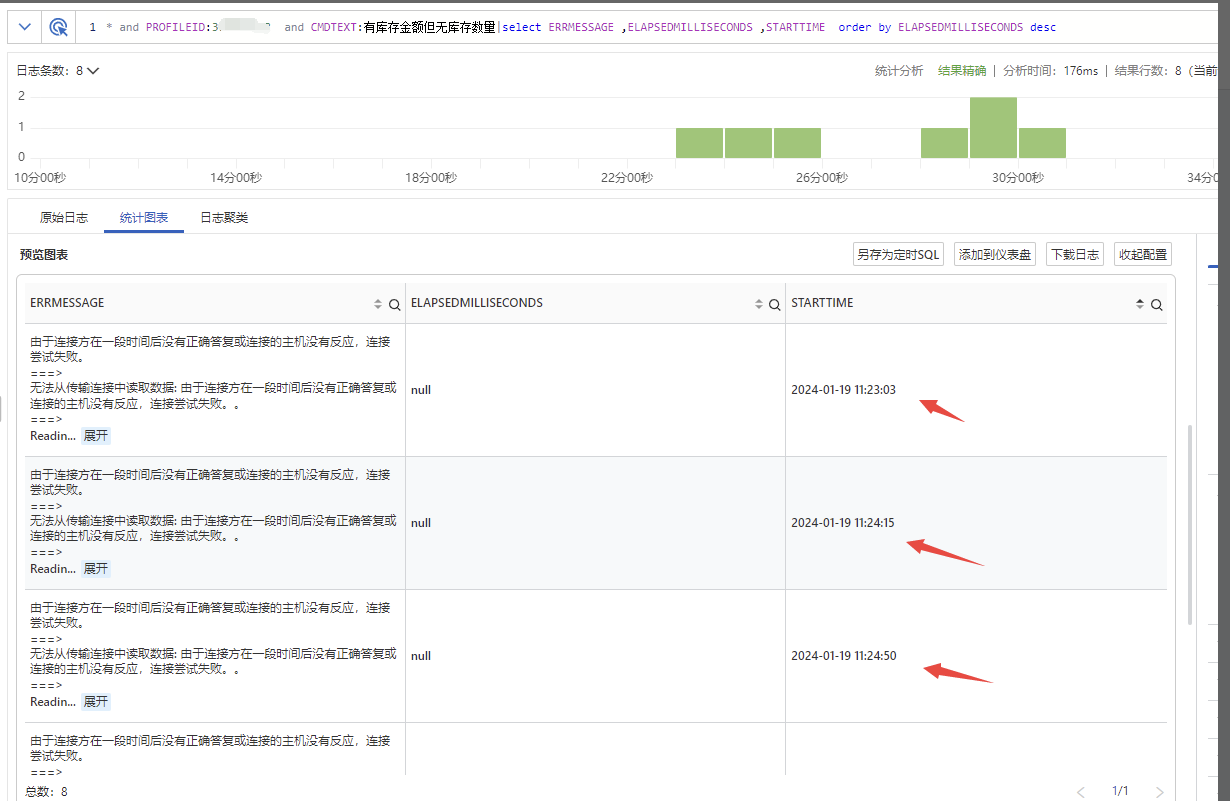
先查询平台记录的慢SQL.由于CPU上升到100% 是在11:26分
慢SQL造成CPU100% 最不好查的就是哪几个SQL才是源头,不然很容易陷入先有鸡还是先有蛋的问题:即是慢SQL造成的cpu100% 还是由CPU100%后造成的慢SQL.
到底是哪个原因造成的。我常用的手法是重放执行,看到重放计划较安全后再重放执行。如果重放的时间和当初慢SQL时间较大出入。那一般是CPU升到100后造成的慢SQL,反之就是需要优化的。
即使排查了一大堆需要优化的SQL,那怎么能找到最先优化的呢?我主要从下面开始排查
1、我首先去慢查询日志中查 26分以前的慢SQL,看执行时间与次数都还较正常,凭经验判断不会造成CPU与内存打满
2、然后我又抽取一部份 11:26份之后的执行时间TOP10的慢SQL,在生产上重放了执行计划,根据计划评估后,我又直接重放了执行,发现都和慢SQL记录的时间差距很大,证明这些语句是受CPU 100%的影响。
3、由于KILL掉的QUERY不会在慢查询中,我再去查了一下KILL 历史

发现执行时间最长的两个SQL为同一个。
再根据SQL相关信息,去我们自己记录的dblog中查看开始时间。发现两个语句都是 24,23分左右执行的。而kill时间是31分。那么这部份SQL已执行了7,8分钟了。
看了此SQL的执行计划。根据表中的内容,发现会产生笛卡尔积
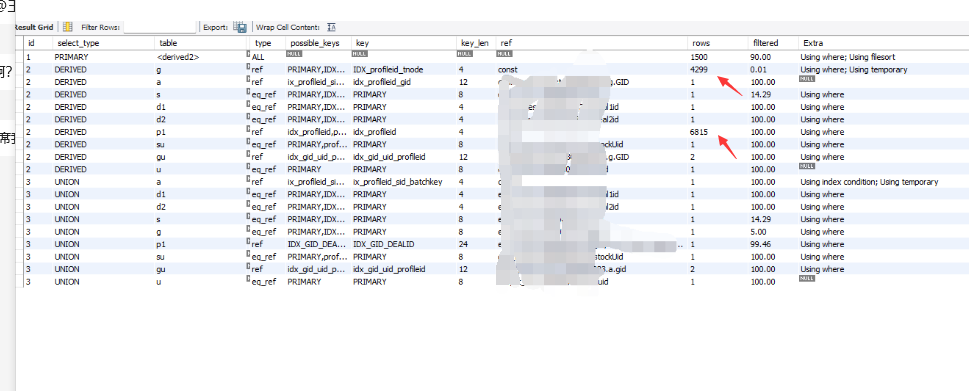
如图。两个箭头的表会产生笛卡尔积。 4299 *6815 会产生29297685行的临时表。因为语句还要union all
我将数据导到本地然后在本地重放SQL,300S都没有执行出来 。已超过我workbench 设置的超时限制

我想尝试此语句的极限在哪里。 我将workbench的超时限制放大到600S
再次执行SQL,发现直接报错

根据报错内容,是磁盘空间不足。我将tmpdir所在盘的空间清理出来。
再次执行,然后观察tmpdir所在盘的磁盘占用,也一并观察cpu与内存情况
当执行到400S时,我发现临时表吃掉我30G, 内存长期100%,CPU间断性100%
至此基于符合生产环境表现出来的现象
但实际SQL还没有执行完。我直接kill了语句

三、优化
此语句优化很简单,是研发将联合索引的中间一个关键字段写漏掉了
改了后的执行计划
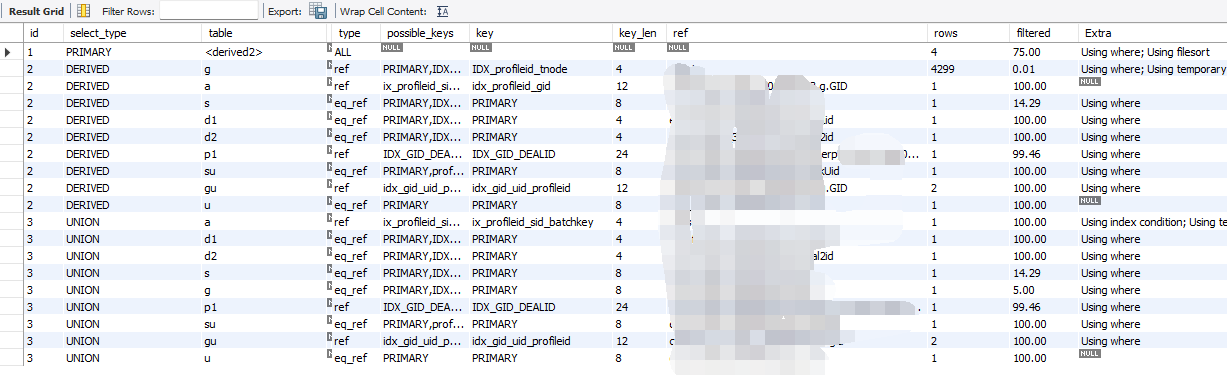
最后执行只需要0.2S
