




背景
在 MySQL 的主从复制架构中,server_id
是一个至关重要的参数。它用于标识每个 MySQL 服务器实例,确保主从服务器之间的数据复制能够准确无误地进行,防止复制回环。传统经验上,有多种方法用于设置这个 server_id
:
顺序编号:一些 DBA 习惯于给主库设置 server_id
为 1,从库设置为 2,如果有更多的从库,则依次递增。IP+端口组合:也有 DBA 采用 IP 地址的尾数加上 MySQL 的端口号来生成 server_id
。例如,如果主库的 IP 是 192.168.199.101,从库的 IP 是 192.168.199.102,那么他们的server_id
可能分别是 1013306 和 1023306。随机数生成:一些先进的自动化工具,如 dbops,选择使用随机数作为 server_id
。
为什么 dbops 要设置 server_id 为随机数字
dbops 选择将 server_id
设置为随机数,主要是因为传统的"顺序编号"和"IP+ 端口号"方法存在局限性。
一、顺序编号为什么不可行?
1. 顺序编号在 Ansible 中其实没啥意义。
由于 Ansible 的执行顺序并不是按照 hosts.ini
文件的书写顺序,因此不能保证主库一定会获得 server_id=1
,第二、第三个从库也无法保证分别获得 server_id=2
和 3
。
2. 顺序编号在 dbops 设计哲学里没作用。
dbops 不支持某些特定架构,如双主的 master-master 架构,但它允许你自行组装。例如,你可以先用 dbops 部署两个独立的 MySQL 实例,再手动设置复制关系。如果 dbops 按照顺序编号 server_id
,这两个实例的 server_id
都会是 1。这导致了你还必须手动更改 server_id
并重启服务,显著影响用户体验。
3. 顺序编号,你知道国外的 Ansible 专家们是如何配置数据库的吗?
他们手动设置!听起来很傻对吗?确实,这种方式很灵活,允许你指定 server_id
,但实际上,谁真的关心 server_id
的具体数值呢?我们只需要确保它们是唯一的!下面是国外专家们的配置方式,采用配置到 hosts.ini 传参来实现:
cat hosts.ini
[dbops_mysql]
192.168.199.131 ansible_user=root ansible_ssh_pass="'gta@2015'" server_id="1"
192.168.199.132 ansible_user=root ansible_ssh_pass="'gta@2015'" server_id="2"
192.168.199.133 ansible_user=root ansible_ssh_pass="'gta@2015'" server_id="3"复制
我的点评: 手动设置
server_id
容易出错,尤其是在大规模或动态扩展的环境中。使用随机数可以减少因人为错误导致的server_id
冲突。
二:IP+端口组合为什么不可行?
我前面提及的 IP+ 端口组合的方法,一般是 IP 尾数 + 端口
的组合,存在明显的局限性。以下这个例子,server_id
就会冲突,他们的 server_id
都等于 1013307。
192.168.198.101:3307
192.168.199.101:3307复制
那你可能会想,用 IP 后两位是否可以解决,答案是不能。例如,考虑以下两个 IP 地址和端口:
192.168.123.123:3306
172.16.123.123:3306复制
尽管一个是 C 类内网地址,另一个是 B 类内网地址,但只要网络配置得当,它们是可以互通的。然而,它们 server_id
(1231233306)也会相同。
那么,是否可以取 IP 的更多位数来生成 server_id
呢?答案同样是不行。因为 server_id
的最大值是 4294967295,这是一个 10 位的整数。而像 1231233306 这样的数字已经达到了 10 位,因此无法再从 IP 地址中提取更多数字来避免冲突。
大家可能觉得我觉得例子太复杂了,线上碰不到,我举个更常见的例子吧
192.168.198.101:13306
192.168.199.101:13306复制
这个用 IP 后两位加端口会如何?答案是超过 server_id
长度上限了。19810113306、19910113306 都是 11 位整数了。
所以,我觉得 IP + 端口
的组合有冲突的可能性,我没有采用这个方案。
dbops 是如何自动设置 server_id 的?
dbops 通过 Jinja2 模板语法在 my.cnf.j2 文件中自动设置 server_id
。当 Ansible 使用 template 模块调用该文件时,server_id
会在 1-1023 范围内随机生成。
[root@192-168-199-175 8.0]# cat my.cnf.j2 |grep server_id
server_id ={{ 1024 |random(1) }} # 0复制
dbops 设置 server_id 有 Bug
熟悉 Ansible 的小伙伴看到上述的 jinja2 代码后思考片刻应该能发现 Bug。
这个 Bug 就是,虽然该设置确保了在多台 MySQL 主从实例中 server_id
是随机的,但并不能保证主从集群里这些 server_id
是唯一的。为了证实这一点,我缩小了 my.cnf 中随机数的范围,并进行了测试。
[root@192-168-199-175 8.0]# cat my.cnf.j2 |grep server_id
server_id ={{ 3 | random(1) }} # 0复制
在这种设置下,server_id
的随机数只能是两个值:1 和 2。这大大增加了在多台 MySQL 主从实例中出现相同 server_id
的可能性。
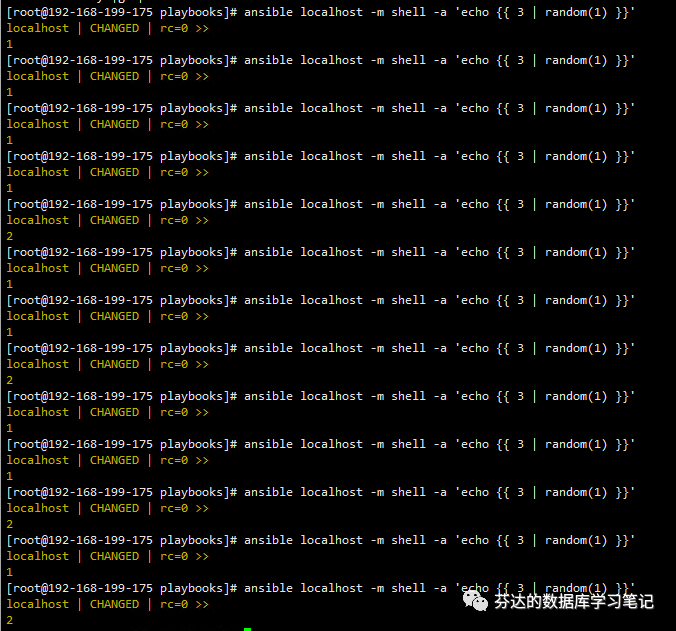
如图,我们证实了 {{ 3 | random(1) }}
设置下,输出的范围只有 1、2 两种值。所以使用这个方法是有可能会导致主从的 server_id
重复的。
下面我们用上述 {{ 3 | random(1) }}
的设置执行 dbops 的 playbook 搭建主从。

playbook 执行成功,没报错。
我分别登录上两台主从服务器,查看 server_id
,运气非常好,他们 server_id
相同的概率是 50%,我执行一次就模拟出来了。
[root@192-168-199-131 3306]# cat my.cnf |grep server_id
server_id =2 # 0
[root@192-168-199-132 3306]# cat my.cnf |grep server_id
server_id =2 # 0复制
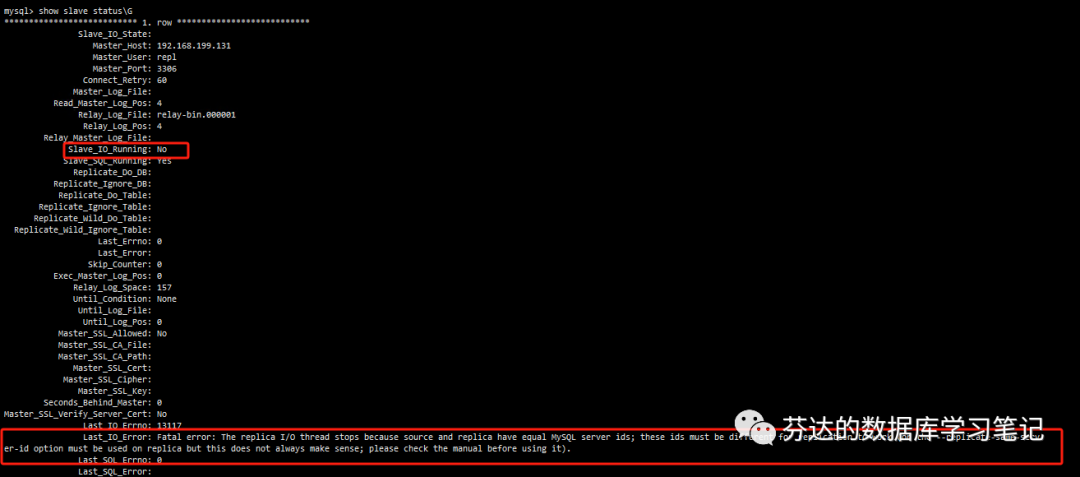
这个 Bug 导致了主从的 server_id
相同,这个是有问题的,并且 dbops 显示部署成功,但从库实际处于复制不可用的状态。(下图)
为什么我一直没有发现这个低级的 Bug
答案是我运气还不错。尽管我已经进行了几百次测试,但在部署一主一从的配置中触发这个 Bug 的概率大约是千分之一(1/1023)。而在部署一主两从的配置中,这个概率大约是千分之三。触发的概率不高但也不算低了。值得一提的是,我并非在使用过程中发现这个 Bug,而是在阅读这段代码时意外发现的。直到现在,这个 Bug 才得以修复。
我是如何修复这个 Bug 的
1.我扩大了随机数的范围,让 server_id
在官方允许的范围内随机生成,即在 1-4294967295 之间。
2.我调整逻辑上移到 pre_tasks 预执行脚本中生成 server_id
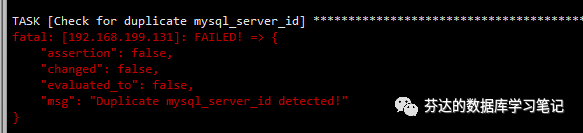
。如果生成的随机数出现冲突,那你的运气已经超过了中双色球头奖(双色球头奖的中奖概率为 1772 万分之一,而一主一从情况下 server_id
冲突的概率为 43 亿分之一)。这种情况下,部署会在开始前报错,你只需重新执行 playbook 脚本即可。
如果你看到这个报错,那么恭喜你,你的运气已经远超过中彩票的概率,成为这个星球最亮的仔。
最后
最新 dbops 已含上述更新代码,欢迎下载试用。
下载地址: https://gitee.com/fanderchan/dbops
