




1、事出有因
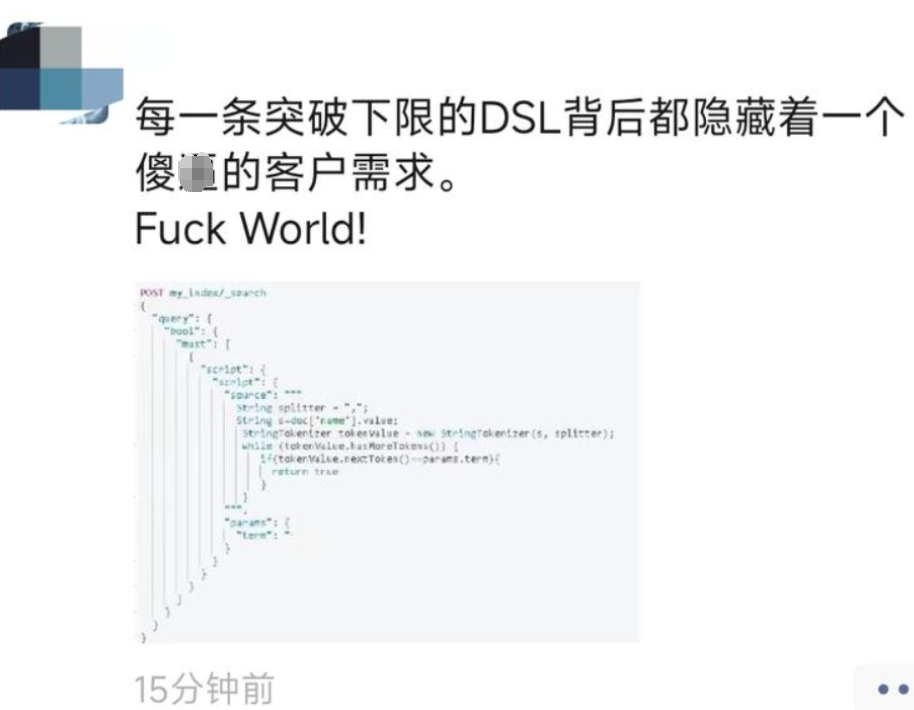
偶然间在朋友圈看到球友的一次分享,很好奇什么原因导致发了这么大的火!
我们放大看一下,是类似如下的 DSL。
POST my_index_001/_search{"query": {"script": {"script": {"source": """def strArrray=doc['name'].value;def searchTerm = params.searchTerm;def parts=strArrray.splitOnToken(',');for (part in parts) {if (part.trim().equals(searchTerm)) {return true;}}return false;""","params": {"searchTerm": "一局"}}}}}
而事情的来龙去脉是怎么样的呢?

我们且探个究竟。
2、问题来源
这是一个2024-01-22 21:54 的真实问题。
问题来源:https://t.zsxq.com/16aLaaHrP
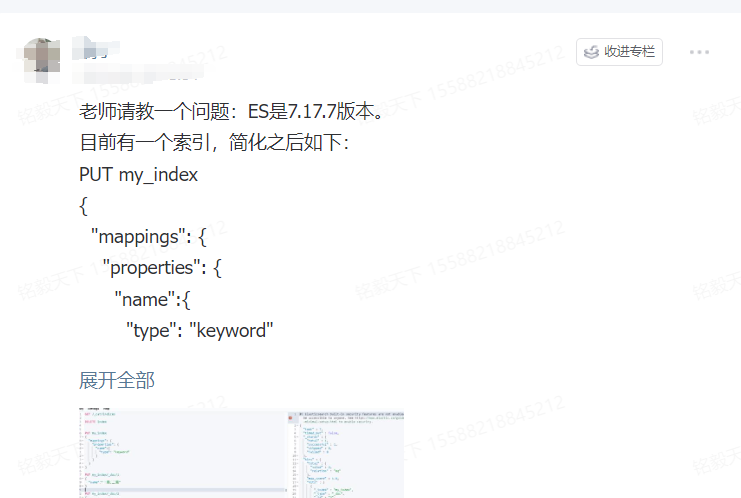
问题描述如下:
老师请教一个问题:ES是7.17.7版本。
目前有一个索引,简化之后如下:
PUT my_index{"mappings": {"properties": {"name":{"type": "keyword"}}}}PUT my_index/_doc/1{"name":"一局,二局"}PUT my_index/_doc/2{"name":"三局,十一局"}
因为历史原因是用逗号隔开存进去的,没存储为数组。
现在想比如搜索“一局”,我是这么写的。
POST my_index/_search{"query": {"script": {"script": {"source": "doc['name'].value.contains('一局')"}}}}
检索结果如下:

但是有个问题就是,因为十一局也是包含一局的,所以doc2也会被匹配,试了好几种方式都不行,老师能否指点一下。
3、问题解读
实际上问题已经描述得非常清楚了。
数据在存储的时候没有切分,而是以逗号分隔的字符串形式写入的数据。
而现在只想搜索其中的部分数据:“一局”,而如果按照上述的脚本检索方式,“十一局”包含“一局”,会出现文档1、文档2都会被召回的情况。
如果不动索引映射结构,只从检索的角度,只能借助脚本实现。
脚本实现就有了开头的脚本。
其核心部分如下所示:
def strArrray=doc['name'].value;def searchTerm = params.searchTerm;def parts=strArrray.splitOnToken(',');for (part in parts) {if (part.trim().equals(searchTerm)) {return true;}}return false;
我们通过脚本的方式,拆开字符串,然后进行拆开后的字符串级比较,如果相等,则直接召回数据。
这样就解决了精准匹配的问题。
但,这必然不是最优的方案。
一方面原因:脚本的复杂性,即便再熟悉官方文档,也不能快速写出。这是大家普遍反馈的共识。
另一方面原因:数据量大了,会有性能问题。
有没有其他解决方案?
4、解决方案探讨
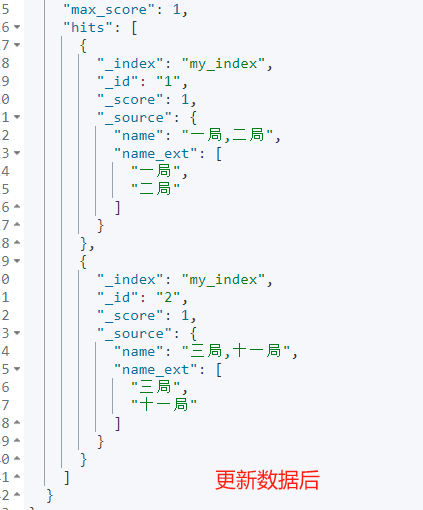
4.1 方案一:更新字段,“敌不过来,我就过去”,主动修改字段。
就是新增一个字段,然后通过 update_by_query + pipeline 的方式更新。
PUT _ingest/pipeline/split_pipeline_0126{"processors": [{"split": {"field": "name","separator": ",","target_field": "name_ext"}}]}POST my_index/_update_by_query?pipeline=split_pipeline_0126{"query": {"match_all": {}}}POST my_index/_search
4.2 方案二:重新创建索引,将数据迁移的过程中修改数据。
就是借助:default_pipeline + reindex 方式实现。
PUT my_index_002{"settings": {"default_pipeline":"split_pipeline_0126"},"mappings": {"properties": {"name": {"type": "keyword"},"name_ext": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}POST _reindex{"source": {"index": "my_index"},"dest": {"index": "my_index_002"}}POST my_index_002/_search
从实现层面和理解层面,如上两种方式的实现都比前文提到的复杂的脚本要复杂一些。
预处理是 Elasticseearch 5.X 就有的功能,在翻看 8.12 新版本官方文档的时候,又有了新的内容。

比如:如下截图,凸显了预处理器 ingest pipeline 在解析日志的强大之处。
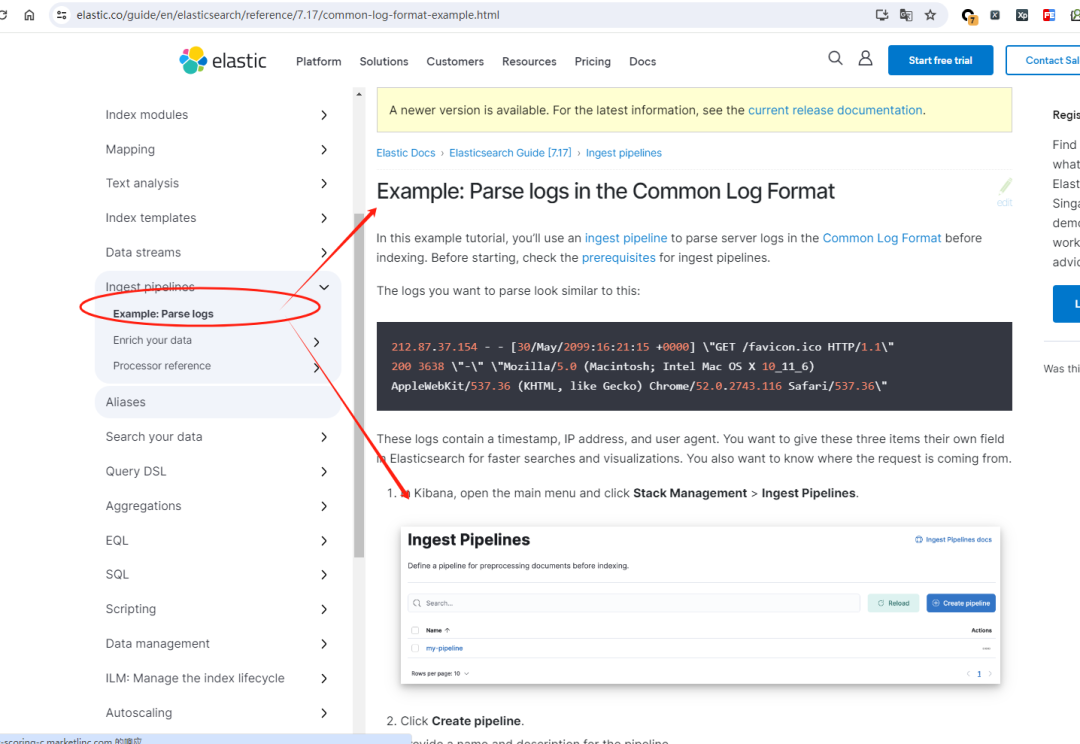
这点,基本上和我们上次的发文可以对应上。
5、小结
文章标题来自球友的朋友圈,当然是一时生气的发的个人感慨而已,请大家多关心技术点的实现,不要过度解释。
说一下,DSL 有没有下限呢?取决于我们如何理解业务需求,如何对接业务需求?如何实现业务逻辑?如何技术选型?等.....
如果你也有类似的问题,欢迎抛给我们一起探讨交流。

7 年+积累、 Elastic 创始人Shay Banon 等 15 位专家推荐的 Elasticsearch 8.X新书已上线
