





 第 19 篇 | LINSHIYI
第 19 篇 | LINSHIYI 
 TTF里都有什么SVG里都有什么SVG笔记(一):Python如何解析SVG?第一部分Unicode和它的朋友们(上) Unicode和它的朋友们(下)
TTF里都有什么SVG里都有什么SVG笔记(一):Python如何解析SVG?第一部分Unicode和它的朋友们(上) Unicode和它的朋友们(下)

在第三节绘制字形轮廓的时候我们还会用到matplotlib库,这是一个非常强大的绘图库,官网定义如下:

这一节主要解析TTF文件的结构并查看字体表中的内容,一共介绍两种方法。第一种方法是使用fontTools库中的ttLib模块,第二种方法是先将TTF文件转换成XML文件,再通过解析XML的方式来解析TTF文件。fontTools方法获得的信息会更多一些,但XML方法更直观,两种方法获得的结果相同,下文中会混合使用。
2.1 查看所有字体表
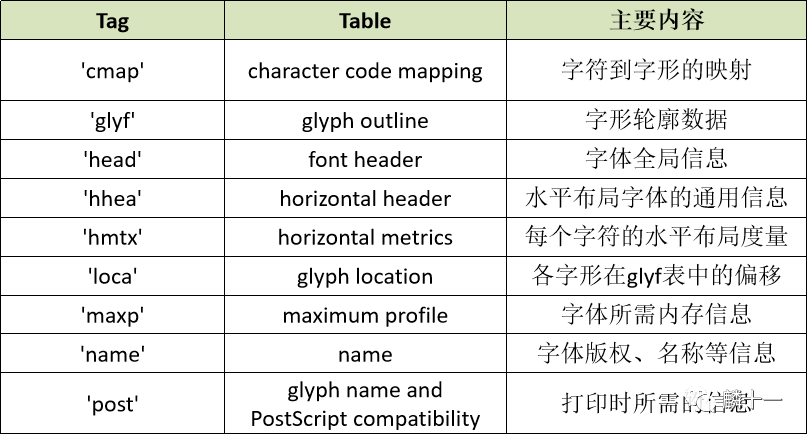
之前介绍TTF文件的时候提到过,TrueType字体文件中共有9张必须表,先复习一下(有关TrueType字体的所有表介绍见苹果官网https://developer.apple.com/fonts/TrueType-Reference-Manual/ )
我们以标准楷体文件(simkai.ttf)为例,先用fontTools方法查看该文件中有哪些字体表:
1#1. fontTools方法查看所有表
2from fontTools.ttLib import TTFont
3#1.1 加载TTF文件
4font = TTFont("simkai.ttf")
5#1.2 获取所有表名
6print(font.keys())
7#['GlyphOrder', 'head', 'hhea', 'maxp', 'OS/2', 'hmtx', 'cmap', 'fpgm', 'prep', 'cvt ', 'loca', 'glyf', 'name', 'post', 'gasp', 'GSUB', 'vhea', 'vmtx', 'DSIG']复制
1#2. XML方法查看所有表
2import xml.dom.minidom
3 #2.1 TTF转换成XML文件
4 font.saveXML("simkai.xml")
5 #2.2 DOM方法解析XML
6 DOMTree = xml.dom.minidom.parse('simkai.xml')
7 #2.2.1 提取根节点
8root = DOMTree.documentElement
9 #2.2.2 提取所有子节点
10 childnodes = root.childNodes
11 #2.2.3 处理多余的换行符节点
12tables = []
13for i in childnodes:
14 if str(i) == '<DOM Text node "\'\\n\\n \'">' or str(i) == '<DOM Text node "\'\\n\\n\'">':
15 continue
16 else:
17 tables.append(i)
18 #2.3 查看所有表
19print(tables)
20#[<DOM Element: GlyphOrder at 0x15f9223f178>, <DOM Element: head at 0x15f951d89c8>, <DOM Element: hhea at 0x15f951e2508>, <DOM Element: maxp at 0x15f951ea048>, <DOM Element: OS_2 at 0x15f951ea9c8>, <DOM Element: hmtx at 0x15f951fc800>, <DOM Element: cmap at 0x15f98d08178>, <DOM Element: fpgm at 0x15f9c16c340>, <DOM Element: prep at 0x15f9c16c470>, <DOM Element: cvt at 0x15f9c16c5a0>, <DOM Element: loca at 0x15f9c1fadf0>, <DOM Element: glyf at 0x15f9c1fae88>, <DOM Element: name at 0x1618d66a930>, <DOM Element: post at 0x1618d688930>, <DOM Element: gasp at 0x1618d688f20>, <DOM Element: GSUB at 0x1618d695210>, <DOM Element: vhea at 0x1618d6aaa60>, <DOM Element: vmtx at 0x1618d6b45a0>, <DOM Element: DSIG at 0x1619122ce88>]复制
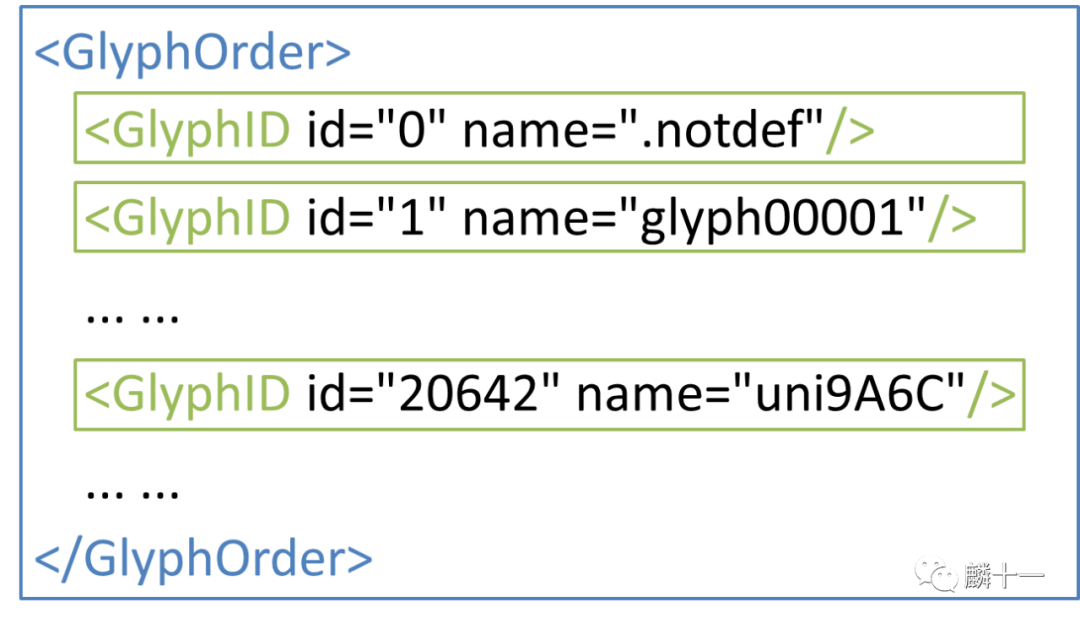
1#3.'GlyphOrder'表
2#3.1 fontTools方法
3#3.1.1 获取'GlyphOrder'表中的字符名称列表
4Glyphorder_table = font.getGlyphOrder()
5#3.1.2 查看前10项
6print(glyphorder_table[0:10])
7#['.notdef', 'glyph00001', 'glyph00002', 'space', 'exclam', 'quotedbl', 'numbersign', 'dollar', 'percent', 'ampersand']
8#3.1.3 查找"马"是第几个字形数据
9print("马的Unicode十六进制编码是 {}".format(hex(ord("马"))[2:]))
10#马的Unicode十六进制编码是 9a6c
11for i in range(len(glyphorder_table)):
12 if glyphorder_table[i] == 'uni9A6C':
13 print("马是第 {} 个字形".format(i))
14 else:
15 continue
16#马是第 20642 个字形复制
1#3.2 XML方法
2#3.2.1 从根节点提取'GlyphOrder'节点
3glyphorder_node = root.getElementsByTagName('GlyphOrder')
4#3.2.2 获取GlyphOrder节点下的所有子节点
5glyphorder_node_list = glyphorder_node[0].getElementsByTagName('GlyphID')
6#3.2.3 查找字符"马"的节点
7ma_node = glyphorder_node_list[20642]
8#3.2.4 查看属性值
9print(ma.getAttribute('id'))
10#20642
11print(ma.getAttribute('name'))
12#uni9A6C复制
1#4. 查看表中的数据
2#4.1 fontTools方法
3#4.1.1 所有字形的边界框
4xMin, xMax, yMin, yMax = font['head'].xMin, font['head'].xMax, font['head'].yMin, font['head'].yMax
5print("所有字形的边界框: xMin = {}, xMax = {}, yMin = {}, yMax = {}".format(xMin, xMax, yMin, yMax))
6#4.1.2 所有字形的最大上坡度和下坡度
7ascent, descent = font['hhea'].ascent, font['hhea'].descent
8print("所有字形的最大上坡度为 {}, 最大下坡度为 {}".format(ascent, descent))
9#4.1.3 "马"的步进宽度和左侧轴承
10width, lsb = font['hmtx']['uni9A6C']
11print("'马'的步进宽度为 {}, 左侧轴承为 {}".format(width, lsb))
12#4.1.4 TTF文件中存储了多少个字形数据
13numGLyphs = font['maxp'].numGlyphs
14print("标准楷体文件中共有 {} 个字符的字形数据".format(numGLyphs))
15#4.1.5 TTF文件的编码方式
16encoding_format = font['cmap'].tables[0].getEncoding()
17print("标准楷体文件在Windows系统下的字符编码方式为 {} ".format(encoding_format))复制
1#4.1 fontTools方法
2#4.1.1 所有字形的边界框
3所有字形的边界框: xMin = -12, xMax = 264, yMin = -47, yMax = 220
4#4.1.2 所有字形的最大上坡度和下坡度
5所有字形的最大上坡度为 220, 最大下坡度为 -36
6#4.1.3 "马"的步进宽度和左侧轴承
7'马'的步进宽度为 256, 左侧轴承为 23
8#4.1.4 TTF文件中存储了多少个字形数据
9标准楷体文件中共有 28562 个字符的字形数据
10#4.1.5 TTF文件的编码方式
11标准楷体文件在Windows系统下的字符编码方式为 utf_16_be复制
TTF里都有什么一文中有详细介绍。1#4.2 XML方法
2#4.2.1 所有字形的边界框
3#提取head节点
4head = root.getElementsByTagName('head')
5#分别提取边界框
6xMin = head[0].getElementsByTagName('xMin')[0].getAttribute('value')
7xMax = head[0].getElementsByTagName('xMax')[0].getAttribute('value')
8yMin = head[0].getElementsByTagName('yMin')[0].getAttribute('value')
9yMax = head[0].getElementsByTagName('yMax')[0].getAttribute('value')
10print("所有字形的边界框: xMin = {}, xMax = {}, yMin = {}, yMax = {}".format(xMin, xMax, yMin, yMax))
11#所有字形的边界框: xMin = -12, xMax = 264, yMin = -47, yMax = 220
12#4.2.2 所有字形的最大上坡度和下坡度
13#提取hhea节点
14hhea = root.getElementsByTagName('hhea')
15#分别提取最大上坡度和最大下坡度
16ascent = hhea[0].getElementsByTagName('ascent')[0].getAttribute('value')
17descent = hhea[0].getElementsByTagName('descent')[0].getAttribute('value')
18print("所有字形的最大上坡度为 {}, 最大下坡度为 {}".format(ascent, descent))
19#所有字形的最大上坡度为 220, 最大下坡度为 -36
20#4.2.3 "马"的步进宽度和左侧轴承
21#提取hmtx节点
22hmtx = root.getElementsByTagName('hmtx')
23#分别提取"马"的编码,步进宽度和左侧轴承
24name = hmtx[0].getElementsByTagName('mtx')[27016].getAttribute('name')
25width = hmtx[0].getElementsByTagName('mtx')[27016].getAttribute('width')
26lsb = hmtx[0].getElementsByTagName('mtx')[27016].getAttribute('lsb')
27print("'马'的Unicode编码为 {}, 步进宽度为 {}, 左侧轴承为 {}".format(name, width, lsb))
28#'马'的Unicode编码为 'uni9A6C', 步进宽度为 256, 左侧轴承为 23复制
两种方法的结果是一样的,我们可以发现XML方法语法更复杂一些,所以如果只是想看看TTF文件的结构,推荐直接打开XML文件查看 没有必要再用Python解析了。
没有必要再用Python解析了。
2.4 字形映射
在2.2节中我们通过'GlyphOrder'表发现“马”在标准楷体文件中是第20642个字形,但在#4.2.3中我们又发现“马”在'hmtx'表中是第27016个字形,这其实与字形的排列顺序有关:
1#5. 字符和字形数据的映射
2print("马的Unicode十六进制编码是 {}".format(hex(ord("马"))[2:]))
3#马的Unicode十六进制编码是 9a6c
4#5.1 通过字符名称获取字形ID
5font.getGlyphID("uni9A6C") #20642
6#5.2 根据字形ID获取字符名称
7font.getGlyphName(20642) #'uni9A6C'
8#5.3 根据字形ID获取字符名称
9font.getGlyphOrder()[20642] #'uni9A6C'
10#5.4 根据字形ID获取字符名称
11font.glyphOrder[20642] #'uni9A6C'
12#5.5 按字母顺序表提取字形数据
13glyphnames = font.getGlyphNames()
14for i in range(len(glyphnames)):
15 if glyphnames[i] == 'uni9A6C':
16 print("按照字母顺序表排列,'马'的字形数据是第 {} 个".format(i))
17#按照字母顺序表排列,'马'的字形数据是第 27016 个复制
刚刚的5种方法都可以查找TTF文件中的字符和字形映射,不过结果略有不同。#5.5使用getGlyphNames()获取的字符名称列表是按照字母顺序表排列的,XML文件中的'hmtx'节点和'glyf'节点中的字形数据都是按这个顺序进行排列的,而TTF文件中真正的字形ID并非如此排列。
简单来说,使用fontTools方法在TTF文件中查询字形,需要使用字形ID,在这里就是20642;而使用XML方法查询字形,需要用到按字母顺序表排列的字形ID,即27016。
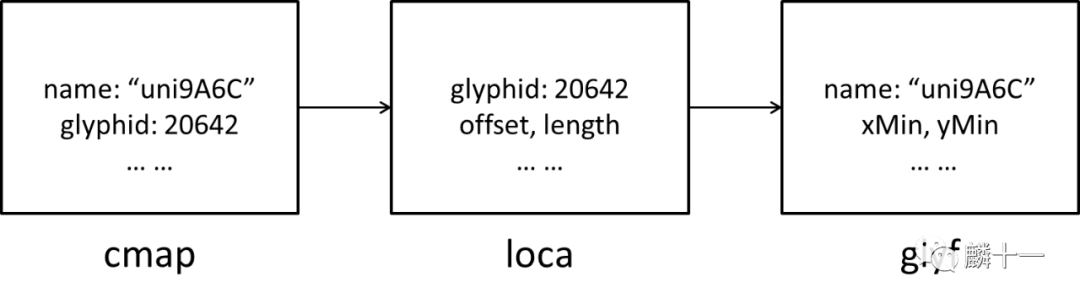
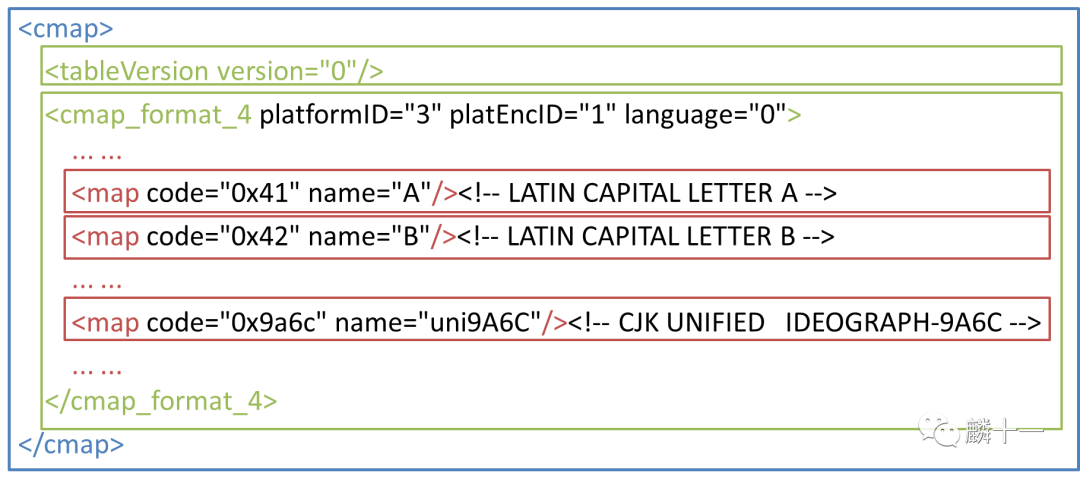
在“TTF有什么”那一篇文中提到过,'cmap','loca'和'glyf'三张表之间存在着映射关系。'cmap'表包含了字符名称和对应的字形ID,'loca'表存储了各个字符相对于'glyf'表头的偏移量,也就是具体字形数据的位置,'glyf'表里有字符名称和字形数据。
一般的字符映射过程是:根据字符名称在'cmap'表中查找字形ID,然后通过'loca'表定位到字形数据在'glyf'表中的位置,最后从'glyf'表中取出数据。先复习一下这个流程:
1#6. "马"的字形映射
2#6.1 fontTools方法
3#6.1.1 'cmap'表 - 查看字形ID
4font['cmap'].tables[0].ttFont.getGlyphID("uni9A6C")
5#20642
6#6.1.2 'loca'表 - 查看字形相对于'glyf'头部的偏移量
7#查看'loca'表格式 - 0 for short offsets,1 for long
8 print('loca表格式 {}'.format(font['head'].indexToLocFormat))
9#loca表格式 1
10print('偏移量 {}'.format(font['loca'].__getitem__(20642)))
11#偏移量 7944804
12print("'马'字形长度 {}".format(font['loca'].__getitem__(20642) - font['loca'].__getitem__(20641)))
13#"马"字形长度 812
14#6.1.3 'glyf'表 - 查看字形数据
15font['glyf']["uni9A6C"].xMin #23
16font['glyf']["uni9A6C"].xMax #223
17font['glyf']["uni9A6C"].yMin #-24
18font['glyf']["uni9A6C"].yMax #194
19font['glyf']["uni9A6C"].coordinates
20#GlyphCoordinates([(182, 102),(194, 109),(211, 100),(223, 91),(217, 81),(213, 69),(208, 20),(198, -7),(173, -24),(171, -5),(147, 19),(179, 5),(190, 15),(198, 61),(197, 87),(192, 95),(165, 94),(111, 87),(87, 82),(77, 73),(66, 91),(72, 95),(78, 114),(80, 143),(73, 159),(90, 153),(99, 143),(93, 135),(84, 94),(85, 91),(100, 93),(142, 98),(137, 109),(142, 121),(148, 147),(151, 176),(144, 179),(101, 171),(79, 166),(62, 178),(70, 178),(79, 178),(107, 180),(136, 186),(151, 194),(163, 188),(176, 179),(164, 168),(157, 127),(150, 99),(133, 58),(152, 64),(167, 58),(174, 48),(138, 47),(68, 38),(43, 32),(23, 46),(51, 45),(92, 51)])
21font['glyf']['uni9A6C'].flags
22#array('B', [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1])复制
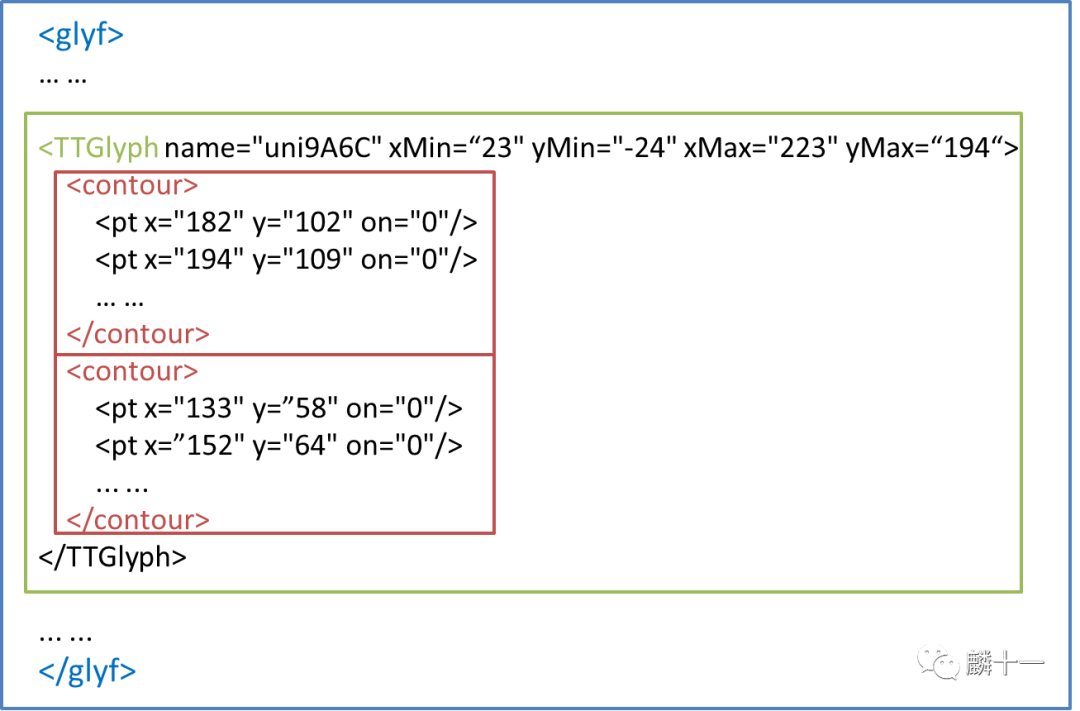
'glyf'表的结构--XML版
1#6.2 XML方法
2#6.2.1 'glyf'表 - 查看字形数据
3#获取glyf节点
4glyf = root.getElementsByTagName('glyf')
5#获取字形列表
6ttglyph = glyf[0].getElementsByTagName('TTGlyph')
7#获取"马"的字符名称
8ttglyph[27016].getAttribute('name')#'uni9A6C'
9#获取"马"的边界框坐标
10ttglyph[27016].getAttribute('xMin') #23
11ttglyph[27016].getAttribute('xMax') #223
12ttglyph[27016].getAttribute('yMin') #-24
13ttglyph[27016].getAttribute('yMax') #194
14#获取"马"的字形轮廓节点
15contour = ttglyph[27016].getElementsByTagName('contour')
16print(contour)
17#[<DOM Element: contour at 0x192de792cc0>, <DOM Element: contour at 0x192de7aac28>]
18#获取"马"的第一条轮廓中第一个轮廓点的信息
19contour[0].getElementsByTagName('pt')[0].getAttribute('x') #182
20contour[0].getElementsByTagName('pt')[0].getAttribute('y') #102
21contour[0].getElementsByTagName('pt')[0].getAttribute('on') #0复制

3.1 生成PNG图片
绘制PNG图片的思路是:从TTF文件中提取出轮廓点坐标和绘制指令,之后将绘制命令转化为matplotlib可以识别的指令,最后使用matplotlib进行绘图。
这部分内容在网上资料很少,所以我造了一个小轮子来生成图片,第一步是提取绘制语句:
1#7. 提取"马"的字形并复现
2from fontTools.ttLib.ttFont import TTFont
3from fontTools.pens.svgPathPen import SVGPathPen
4import matplotlib.pyplot as plt
5import matplotlib.patches as patches
6from matplotlib.path import Path
7import matplotlib._color_data as mcd
8%matplotlib inline
9#加载字体
10font = TTFont('simkai.ttf')
11#7.1 生成PNG图片
12#7.1.1 第一步提取绘制命令语句
13#获取包含字形名称和字形对象的--字形集对象glyphset
14glyphset = font.getGlyphSet()
15#获取pen的基类
16pen = SVGPathPen(glyphset)
17#查找"马"的字形对象
18glyph = glyphset['uni9A6C']
19#绘制"马"的字形对象
20glyph.draw(pen)
21#提取"马"的绘制语句
22commands = pen._commands
23print(commands)
24#['M84 94', 'Q85 91 92.5 92.0', 'Q100 93 142 98', 'Q137 109 139.5 115.0', 'Q142 121 145.0 134.0', 'Q148 147 149.5 161.5', 'Q151 176 147.5 177.5', 'Q144 179 122.5 175.0', 'Q101 171 90.0 168.5', 'Q79 166 70.5 172.0', 'Q62 178 70 178', 'Q79 178 93.0 179.0', 'Q107 180 121.5 183.0', 'Q136 186 143.5 190.0', 'Q151 194 157.0 191.0', 'Q163 188 169.5 183.5', 'Q176 179 170.0 173.5', 'Q164 168 160.5 147.5', 'Q157 127 150 99', 'Q182 102 188.0 105.5', 'Q194 109 202.5 104.5', 'Q211 100 217.0 95.5', 'Q223 91 220.0 86.0', 'Q217 81 215.0 75.0', 'Q213 69 210.5 44.5', 'Q208 20 203.0 6.5', 'Q198 -7 185.5 -15.5', 'Q173 -24 172.0 -14.5', 'Q171 -5 159.0 7.0', 'Q147 19 163.0 12.0', 'Q179 5 184.5 10.0', 'Q190 15 194.0 38.0', 'Q198 61 197.5 74.0', 'Q197 87 194.5 91.0', 'Q192 95 178.5 94.5', 'Q165 94 138.0 90.5', 'Q111 87 99.0 84.5', 'Q87 82 82.0 77.5', 'Q77 73 71.5 82.0', 'Q66 91 69.0 93.0', 'Q72 95 75.0 104.5', 'Q78 114 79.0 128.5', 'Q80 143 76.5 151.0', 'Q73 159 81.5 156.0', 'Q90 153 94.5 148.0', 'Q99 143 96.0 139.0', 'Q93 135 84 94', 'Z', 'M92 51', 'Q133 58 142.5 61.0', 'Q152 64 159.5 61.0', 'Q167 58 170.5 53.0', 'Q174 48 156.0 47.5', 'Q138 47 103.0 42.5', 'Q68 38 55.5 35.0', 'Q43 32 33.0 39.0', 'Q23 46 37.0 45.5', 'Q51 45 92 51', 'Z']复制
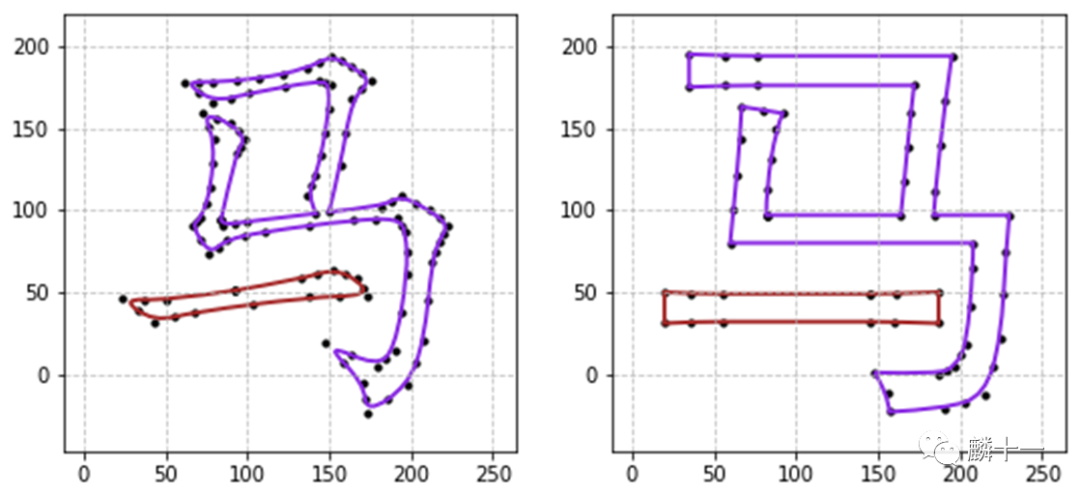
代码中的commands是一个列表,每个元素都是“指令+坐标”的形式,M代表绘制起点,Q代表二次贝塞尔曲线,Z代表闭合路径。“马”字的轮廓中没有出现其他的指令,但是TrueType字体中的绘图指令共有10种,在其他类型的TTF文件中也会涉及到其他的命令,具体的命令解释见SVG里都有什么的最后一节。
由于我想要把不同的轮廓线用不同的颜色显示出来,所以对commands列表做了一点修改,修改后列表的每一个子列表代表一条轮廓线:
1#将绘制命令按照轮廓线划分
2total_commands = []
3command = []
4for i in commands:
5 #每一个命令语句
6 if i == 'Z':
7 #以闭合路径指令Z区分不同轮廓线
8 command.append(i)
9 total_commands.append(command)
10 command = []
11 else:
12 command.append(i)复制
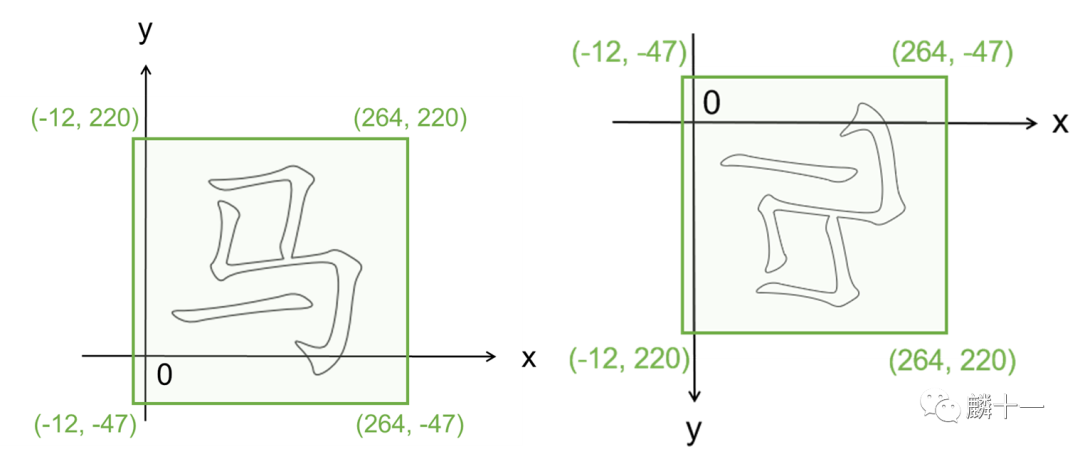
为了让字形正确地显示在图片正中心,我们从'head'表中提取所有字形的边界框:
1#从'head'表中提取所有字形的边界框
2xMin = font['head'].xMin
3yMin = font['head'].yMin
4xMax = font['head'].xMax
5yMax = font['head'].yMax
6print("所有字形的边界框: xMin = {}, xMax = {}, yMin = {}, yMax = {}".format(xMin, xMax, yMin, yMax))
7#所有字形的边界框: xMin = -12, xMax = 264, yMin = -47, yMax = 220复制
之后我们进行第二步:将TTF中的绘制命令转换成matplotlib可以看懂的命令语句 (预警,这一部分,比较长 )
)
1#7.1.2 将TTF中的绘制命令转换成matplotlib可以看懂的命令语句
2#笔的当前位置
3preX = 0.0
4preY = 0.0
5#笔的起始位置
6startX = 0.0
7startY = 0.0
8#所有轮廓点
9total_verts = []
10#所有指令
11total_codes = []
12#转换命令
13for i in total_commands:
14 #每一条轮廓线
15 verts = []
16 codes = []
17 for command in i:
18 #每一条轮廓线中的每一个命令
19 code = command[0] #第一个字符是指令
20 vert = command[1:].split(' ') #其余字符是坐标点,以空格分隔
21 # M = 路径起始 - 参数 - 起始点坐标 (x y)+
22 if code == 'M':
23 codes.append(Path.MOVETO) #转换指令
24 verts.append((float(vert[0]), float(vert[1]))) #提取x和y坐标
25 #保存笔的起始位置
26 startX = float(vert[0])
27 startY = float(vert[1])
28 #保存笔的当前位置(由于是起笔,所以当前位置就是起始位置)
29 preX = float(vert[0])
30 preY = float(vert[1])
31 # Q = 绘制二次贝塞尔曲线 - 参数 - 曲线控制点和终点坐标(x1 y1 x y)+
32 elif code == 'Q':
33 codes.append(Path.CURVE3) #转换指令
34 verts.append((float(vert[0]), float(vert[1]))) #提取曲线控制点坐标
35 codes.append(Path.CURVE3) #转换指令
36 verts.append((float(vert[2]), float(vert[3]))) #提取曲线终点坐标
37 #保存笔的当前位置--曲线终点坐标x和y
38 preX = float(vert[2])
39 preY = float(vert[3])
40 # C = 绘制三次贝塞尔曲线 - 参数 - 曲线控制点1,控制点2和终点坐标(x1 y1 x2 y2 x y)+
41 elif code == 'C':
42 codes.append(Path.CURVE4) #转换指令
43 verts.append((float(vert[0]), float(vert[1]))) #提取曲线控制点1坐标
44 codes.append(Path.CURVE4) #转换指令
45 verts.append((float(vert[2]), float(vert[3]))) #提取曲线控制点2坐标
46 codes.append(Path.CURVE4) #转换指令
47 verts.append((float(vert[4]), float(vert[5]))) #提取曲线终点坐标
48 #保存笔的当前位置--曲线终点坐标x和y
49 preX = float(vert[4])
50 preY = float(vert[5])
51 # L = 绘制直线 - 参数 - 直线终点(x, y)+
52 elif code == 'L':
53 codes.append(Path.LINETO) #转换指令
54 verts.append((float(vert[0]), float(vert[1]))) #提取直线终点坐标
55 #保存笔的当前位置--直线终点坐标x和y
56 preX = float(vert[0])
57 preY = float(vert[1])
58 # V = 绘制垂直线 - 参数 - 直线y坐标 (y)+
59 elif code == 'V':
60 #由于是垂直线,x坐标不变,提取y坐标
61 x = preX
62 y = float(vert[0])
63 codes.append(Path.LINETO) #转换指令
64 verts.append((x, y)) #提取直线终点坐标
65 #保存笔的当前位置--直线终点坐标x和y
66 preX = x
67 preY = y
68 # H = 绘制水平线 - 参数 - 直线x坐标 (x)+
69 elif code == 'H':
70 #由于是水平线,y坐标不变,提取x坐标
71 x = float(vert[0])
72 y = preY
73 codes.append(Path.LINETO) #转换指令
74 verts.append((x, y)) #提取直线终点坐标
75 #保存笔的当前位置--直线终点坐标x和y
76 preX = x
77 preY = y
78 # Z = 路径结束,无参数
79 elif code == 'Z':
80 codes.append(Path.CLOSEPOLY) #转换指令
81 verts.append((startX, startY)) #终点坐标就是路径起点坐标
82 #保存笔的当前位置--起点坐标x和y
83 preX = startX
84 preY = startY
85 #有一些语句指令为空,当作直线处理
86 else:
87 codes.append(Path.LINETO) #转换指令
88 verts.append((float(vert[0]), float(vert[1]))) #提取直线终点坐标
89 #保存笔的当前位置--直线终点坐标x和y
90 preX = float(vert[0])
91 preY = float(vert[1])
92 #整合所有指令和坐标
93 total_verts.append(verts)
94 total_codes.append(codes)复制
最后一步,我们来绘制这个图像并保存成PNG图片:
1#7.1.3 绘制PNG图片
2#获取matplotklib中的颜色列表
3color_list = list(mcd.CSS4_COLORS)
4#获取所有的轮廓坐标点
5total_x = []
6total_y = []
7for contour in total_verts:
8 #每一条轮廓曲线
9 x = []
10 y = []
11 for i in contour:
12 #轮廓线上每一个点的坐标(x,y)
13 x.append(i[0])
14 y.append(i[1])
15 total_x.append(x)
16 total_y.append(y)
17#创建画布窗口
18fig, ax = plt.subplots()
19#按照'head'表中所有字形的边界框设定x和y轴上下限
20ax.set_xlim(xMin, xMax)
21ax.set_ylim(yMin, yMax)
22#设置画布1:1显示
23ax.set_aspect(1)
24#添加网格线
25ax.grid(alpha=0.8,linestyle='--')
26#画图
27for i in range(len(total_codes)):
28 #(1)绘制轮廓线
29 #定义路径
30 path = Path(total_verts[i], total_codes[i])
31 #创建形状,无填充,边缘线颜色为color_list中的颜色,边缘线宽度为2
32 patch = patches.PathPatch(path, facecolor = 'none', edgecolor = color_list[i+10], lw=2)
33 #将形状添到图中
34 ax.add_patch(patch)
35 #(2)绘制轮廓点--黑色,点大小为10
36 ax.scatter(total_x[i], total_y[i], color='black',s=10)
37#保存图片
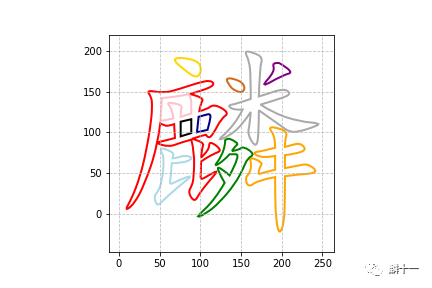
38plt.savefig("simkai-马.png")复制
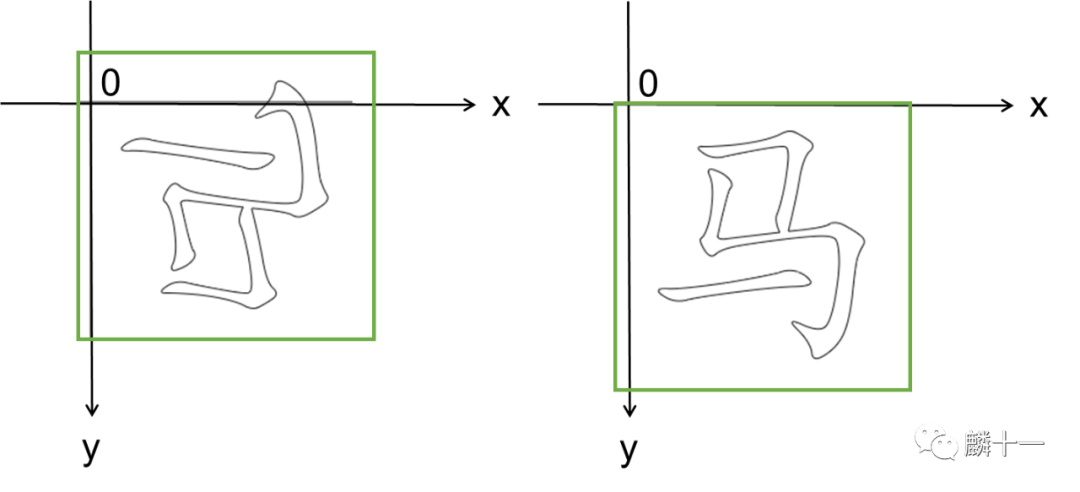
标准楷体 vs 标准黑体的"马"
transform属性更多的内容见https://developer.mozilla.org/en-US/docs/Web/SVG/Attribute/transform。下面提供了两种方法,生成的结果只是viewBox的大小不一样而已,视觉上是一样的:
1#7.2 绘制SVG图片
2from fontTools.ttLib import TTFont
3from fontTools.pens.svgPathPen import SVGPathPen
4#加载字体
5font = TTFont("simkai.ttf")
6#与7.1.1相同--提取绘制命令语句
7glyphset = font.getGlyphSet()
8glyph = glyphset['uni9A6C']
9pen = SVGPathPen(glyphset)
10glyph.draw(pen)
11#方法1
12#获取所有字形的边界框坐标
13xMin, xMax, yMin, yMax = font['head'].xMin, font['head'].xMax, font['head'].yMin, font['head'].yMax
14#viewbox的宽和高
15height1 = yMax - yMin
16width1 = xMax - xMin
17#SVG语句
18svg1 = f"""<svg version="1.1" xmlns="http://www.w3.org/2000/svg" viewBox="{xMin} 0 {width1} {height1}">
19<g transform="matrix(1 0 0 -1 0 {yMax})">
20<path stroke = "black" fill = "none" d="{pen.getCommands()}"/>
21</g>
22</svg>"""
23#写入SVG文件
24with open("test1.svg", "w") as f:
25 f.write(svg1)
26#方法2
27#获取"马"的步进宽度和左侧轴承
28width2, lsb = font['hmtx']['uni9A6C']
29#获取所有字形的上坡度和下坡度
30ascent, descent = font['hhea'].ascent, font['hhea'].descent
31height2 = ascent - descent
32#SVG语句
33svg2 = f"""<svg version="1.1" xmlns="http://www.w3.org/2000/svg" viewBox="{lsb} 0 {width2} {height2}">
34<g transform="matrix(1 0 0 -1 0 {ascent})">
35<path stroke = "black" fill = "none" d="{pen.getCommands()}" />
36</g>
37</svg>"""
38#写入SVG文件
39with open("test2.svg", "w") as f:
40 f.write(svg2)复制

以上就是Python解析TTF文件的所有内容 这一篇内容涉及到了我之前写的好几篇文章,有一种前期铺支线,这一篇终于收尾了的感觉
这一篇内容涉及到了我之前写的好几篇文章,有一种前期铺支线,这一篇终于收尾了的感觉
下一篇应该是读写系列的第四篇:有关XML的解析,之前还想着应该不会再写第四篇了,没想到最近就在写解析XML的接口 等到下一篇写完,读写系列也就结束了,再之后估计会是2-3篇的OCR识别,1篇opencv的安装,然后一直到年底估计就全都是小程序开发系列的文了。
以上算是今年的写作计划,最近有点忙也有点懒,但是希望自己能一直坚持写,至少先写满一年再说别的 哦对,最后一个小小的愿望,但愿我能在7月初把“无锡游记”修完然后发出来
哦对,最后一个小小的愿望,但愿我能在7月初把“无锡游记”修完然后发出来
 END
END ~
~
