





什么是索引?
索引是指数据库为加快数据访问,通过额外存储索引数据结构,将索引值与对应行的存储地址关联起来,以达到“空间换时间”目的的一种数据结构。
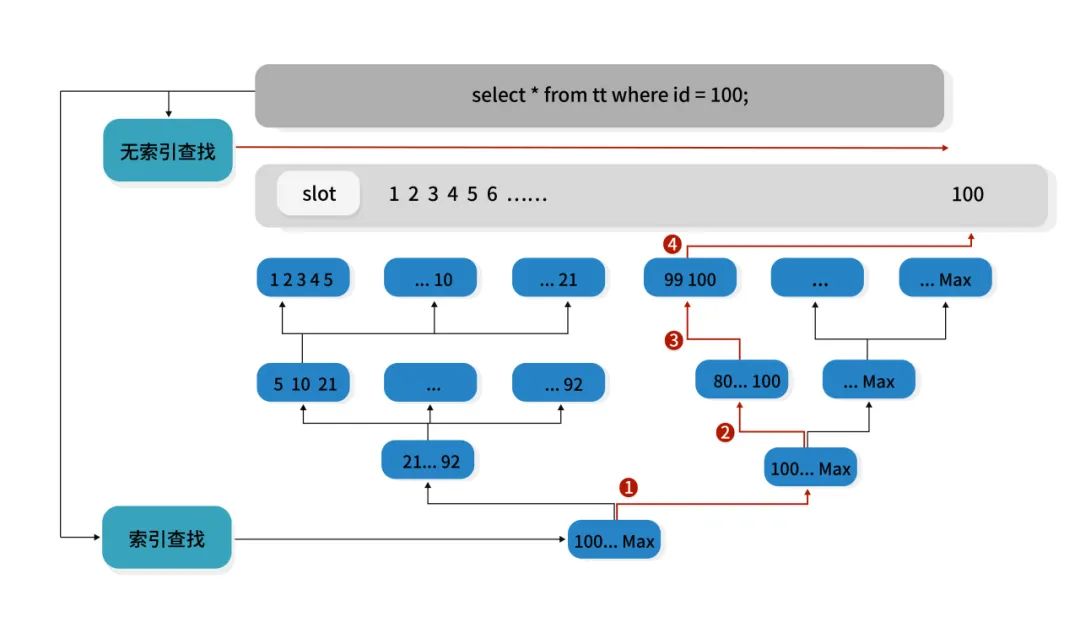
以上图为例,通过索引Key排序并存储到对应的数据结构内,可通过二分法快速定位数据的存储位置。查询Id值为100的行时,如果使用无索引查找,需要遍历Id值为1 - 100的所有行;如果使用索引查找,则只需要4次跳转即可快速定位到Id为100的行。
Qcubic内存存储引擎支持哪些索引种类?
Qcubic支持的索引数据结构为B+树等,本篇着重分析B+树索引。
Qcubic的内存索引数据结构与传统磁盘
数据库的索引数据结构有什么不同?
由于Qcubic内存表的数据全部存储在内存中,不需要考虑磁盘IO性能问题,因此对传统的B+树结构进行了一定程度上的更改,使得它更适用于内存索引场景。如下图所示,内部结点中存储了Row Pointer(即指向内存中该行数据的内存地址)、Key值和Child Node Ptr(指向子结点的内存地址),其中Row Pointer数组、Key数组和Child Node Ptr数组一一对应,通过Key值可以快速定位到子结点的内存地址。叶子结点中存储了Row Pointer和Key值,通过Key值可以快速定位到Row的内存地址。
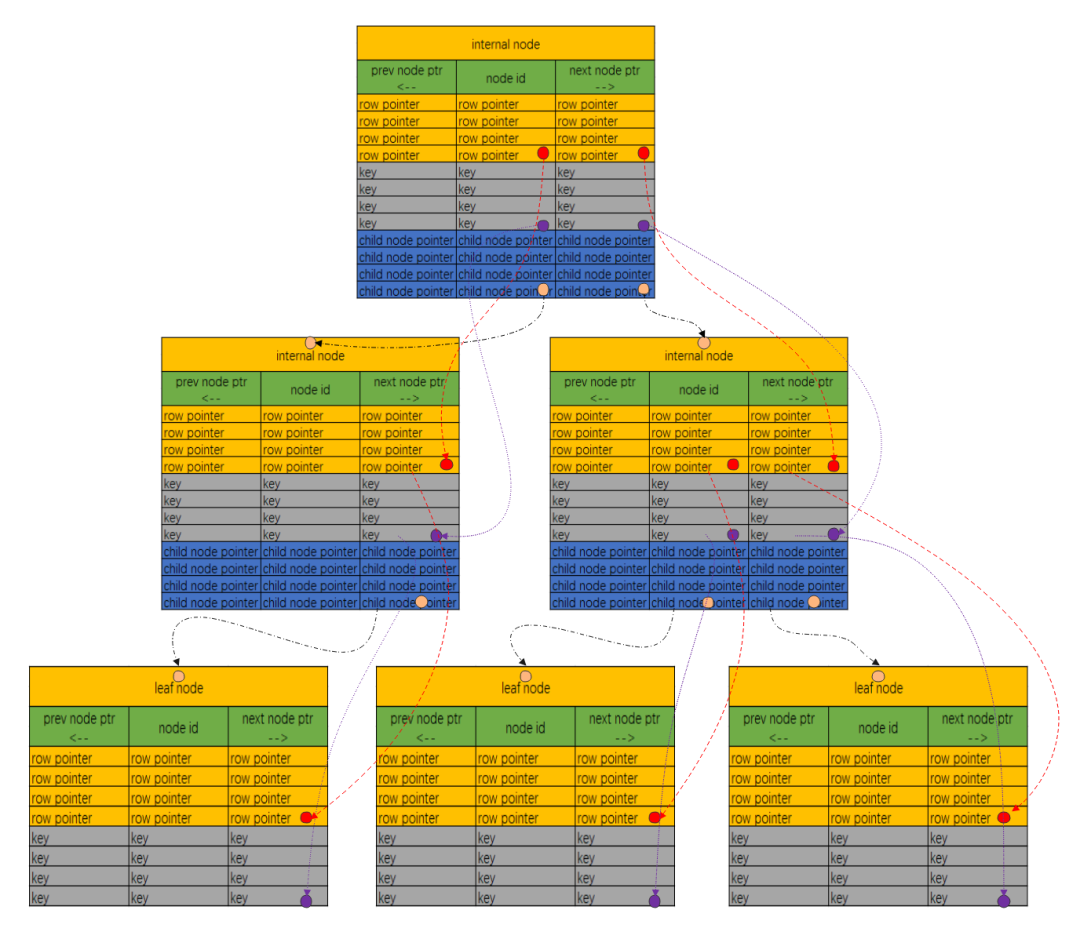
QCUBIC B+树索引结构示意图
具体不同有以下几点:
Qcubic内存索引的内部结点存储了行指针、Key值和子结点的指针。不同于传统磁盘数据库索引,这里的行指针和子结点指针均为内存地址而非ROWID(文件内偏移位置)。之所以采用这样的方法是Qcubic的所有数据都存储在内存中,无需通过ROWID换算其存储位置,可加快访问速度。
传统磁盘数据库会将索引持久化写入到磁盘,而Qcubic默认情况下每次启动时会逐行扫描各个表的Slot并计算Key值,然后在内存中重新构建索引,无需担心程序重新启动后内存地址失效的问题。
在父结点中存储的Key值为对应子结点的最大Key值。当执行插入时先判断待插入的叶结点以及在该叶结点内的偏移量,如果待插入的Key位于当前叶结点的末尾Slot,则直接写入Key、Row Pointer,然后逐级向上更新父节点中key数组对应当前Node的Key值;如果待插入的Key位于当前叶结点的非末尾Slot,则将大于该Key值的Slot向右移动,再将当前Row的相关信息插入。通过以上方法可以尽可能减少因为数据插入而导致的节点锁定,同时在内存中批量移动Slot可使用Memcpy减少时间复杂度。
在内部结点中存储的Row Pointer是下层子结点最大Key值对应的Row。在实际生产环境中,单个表可能有多个索引存在,索引Key值的长度也无法保证(比如变长字符类型),如果在索引Node中存储key值可能会占用较多内存。由于Qcubic内存表的数据全部存储在内存中,可以通过读取Row实时生成Key值的方式减少内存占用(通过系统参数设置是否在索引Node内存储Key值,存储Key值会加快速度但会增加内存占用;不存储Key值减少内存占用但会略微降低索引性能)。
作者宋强,Qcubic内核研发工程师,具有多年Mysql、Oracle数据库文件管理及各类文件系统底层实现技术经验,现负责Qcubic存储引擎模块的功能开发与性能优化。
往期推荐




/END/
