




翻译自:https://stormatics.tech/blogs/ai-meets-postgresql-the-pgvector-revolution-in-text-search
一段时间以来,PostgreSQL一直是顶级的关系数据库。现在,在人工智能时代,我们还需要存储向量数据,以便进行快速和类似的搜索。这就是 pgvector 的用武之地——它就像 PostgreSQL 的一个附加组件,可以帮助它很好地处理向量数据。
什么是向量数据?
想象一下,你有一张地图,但它显示的不是城市和街道,而是你最喜欢的东西:电影、音乐和有趣的猫咪视频。每个事物都像地图上的一个点,如果这些点很近,则意味着这些事物是相似的。例如,一部喜剧电影可能接近另一部喜剧,但与科幻电影不那么接近。在数字世界中,向量就像地图上的点,代表信息,如文本或图像。通过比较这些点的接近程度,我们可以判断事物的相似程度,即使它们使用不同的单词或看起来有点不同。它就像一种秘密语言,让计算机能够理解单词或像素之外的含义——有点像魔术,但有数学!我们将向量数据表示为浮点数列表。
示例:[0.5,1.2, -0.3,4.7] 表示一个 4 维向量。
其他最常用的向量数据库:
Pinecone
Faiss
vespa
milvus
pgvector:文本搜索的革命
想想普通的文本搜索,就像一个侦探仔细地逐字逐句地浏览文档,以找到匹配的内容。现在,pgvector 更像是一个 AI 代理。它将文本、图像或声音存储到高维向量中,就像数字指纹一样,捕捉数据的核心含义。如上所述,如果两个向量在这个空间中很接近,则意味着它们在含义上非常相似。这就是余弦距离的用武之地。这个余弦度量着眼于两个向量之间的角度,如果角度很小,则意味着它们非常相似。
在 Ubuntu 上安装 pgvector
sudo apt install postgresql-15-pgvector
在 CentOS 上安装 pgvector
sudo apt install pgvector_15
注意:这里15是我的PostgreSQL服务器版本,根据您的需要进行更改
请遵循此官方自述文件以获取更多安装方法,例如 Dockers
https://github.com/pgvector/pgvector/blob/master/README.md
pgvector 解决了什么问题?
pgvector 旨在解决 PostgreSQL 中与搜索和数据表示相关的几个关键问题:
有限的文本和数据表示:传统的 PostgreSQL 以简单的格式(如文本、数字和日期)存储数据。由于缺乏灵活的表示方式,因此很难捕捉到文本文档、图像或科学数据等复杂数据点之间的真正含义和关系。pgvector 引入了多维向量作为数据类型,允许根据数据的固有质量和关系更丰富地表示数据。此外,pgvector 基于向量的方法,以及 HNSW 和 IVFFlat 等索引技术,可以在大型数据集上实现更快、更高效的搜索,为实时应用程序和大数据环境提供可扩展性。
低效的相似性搜索:PostgreSQL 中的传统文本搜索依赖于关键字匹配或模式识别,这对于查找相似文档或内容可能很慢,也无法用于对数据的含义进行搜索。pgvector 支持基于余弦距离等高级距离指标的高效相似性搜索,即使它们不共享相同的单词或模式,您也可以找到具有相似含义的项目。
缺乏与机器学习的集成:pgvector 通过实现与机器学习模型生成的向量嵌入的无缝集成,弥合了 PostgreSQL 和机器学习之间的差距。这使您可以直接在 PostgreSQL 数据库中利用机器学习的强大功能来执行文档检索、图像搜索和推荐系统等任务。
精确最近邻搜索与近似最近邻搜索
pgvector 支持两种主要类型的搜索:精确最近邻搜索(ENN)和近似最近邻搜索(ANN)。ENN 和 ANN 都专注于在高维空间中寻找相似的向量,但它们的方法不同,并且具有不同的优点和缺点。
精确最近邻搜索(ENN)
定义:在数据集中查找与查询向量相同的向量。
算法:采用蛮力方法,将查询向量与数据库中的每个向量进行比较。
精度:保证找到真正的最近邻,确保尽可能高的精度。
性能:需要将查询向量与所有可用向量进行比较,这可能会导致计算速度变慢和资源使用率高,尤其是对于大型数据集。
常见用例:当绝对准确性至关重要时,例如在关键的财务计算或科学分析中。
近似最近邻搜索(ANN)
定义:查找在特定容差范围内与查询向量大致相似的向量。
算法:利用索引技术来识别候选向量,而无需比较所有向量,从而显著减少搜索空间。
准确性:提供近似答案,可能遗漏真正的最近邻,但通常会返回近似的替代方案。
性能:与 ENN 相比,搜索时间明显更快,资源消耗更低,适用于大型数据集和实时应用程序。
常见用例:当实时响应和可扩展性优先于绝对准确性时,例如在推荐系统、图像/视频检索和自然语言处理应用程序中。
在 ENN 和 ANN 之间进行选择取决于您的具体需求。
准确性:如果您需要以最高精度找到绝对最接近的匹配,则 ENN 是您的选择。
性能:对于实时应用程序和大型数据集,ANN 提供更快的速度和资源效率。
数据量:数据集越大,ANN的性能优势就越显著。
对不准确的容忍度:想想在你的应用程序中有一个接近匹配是多么好。
其他因素
距离度量:ENN 和 ANN 都可以使用各种距离度量,如 L2、内积和余弦距离。
索引技术:不同的 ANN 算法(如 HNSW 和 IVF)提供了不同的性能和准确性权衡。
用一个更简单的例子解释L2 距离、内积和余弦距离
想象一下水果篮里有两个苹果。
L2 距离
这告诉您苹果在篮子中的距离,就像测量它们之间的直线距离一样。距离越大,它们的相似度就越低。当您需要知道事物之间的确切差异时,例如地图上的距离或价格差异,则使用此方法。在 ENN 的帮助下,pgvector 直接使用 L2 距离来查找与查询向量相同的向量。
内积
这就像比较苹果的味道和质地。高内积意味着它们既甜又脆,而低内积意味着它们不同(也许一个是酸的,另一个是软的)。当您想要比较事物在特定质量方面的相似程度时,例如比较具有相似主题的文档或具有相似节奏的音乐时,会使用此方法。
以下引用通义千问相关解释:
内积是一个数学概念,通常在向量空间中使用,它描述了两个向量之间的一种特殊“乘法”,结果是一个标量(即一个单独的数),而不是另一个向量。
通俗地说,如果你想象有两个箭头(代表二维或三维空间中的向量),内积就是这两个箭头按照特定规则“相乘”得到的结果。这个规则是这样的:
1. 把每个向量的对应分量(长度和方向)分别相乘。
2. 把所有相乘得到的结果加起来。
例如,在二维空间中有两个向量 a = (a1, a2) 和 b = (b1, b2),它们的内积 a·b 就是 a1*b1 加上 a2*b2。
从几何角度看,两个非零向量的内积还等于这两个向量模长(长度)的乘积与它们之间夹角余弦值的乘积,即 a·b = |a| * |b| * cos(θ),其中 θ 是两向量之间的角度。
总结来说,内积提供了一种量化两个向量之间相似性或者“对齐程度”的方法,并且经常在物理、工程、计算机图形学等领域中用于计算力的功、确定角度、评估数据的相关性等方面。
余弦距离
假设每个苹果的顶部都有一个小箭头,指向某个方向。现在,如果你想知道这些苹果有多相似,你可以检查它们箭头之间的角度。当您想知道事物在一般意义上的一致性时,例如查找相似的图片或根据您过去的购买推荐相关产品,请使用此功能。
注意:pgvector 本身并不直接提供基于内积或余弦距离的内置搜索。但是,它以不同的方式利用 L2 距离来实现类似的结果。
以下引用通义千问相关解释:
余弦距离(或称余弦相似度)是一种衡量两个非零向量之间方向差异的度量方式,它广泛应用于机器学习、信息检索和数据挖掘等领域。通俗来讲:
想象你有两个箭头(向量),它们都指向一个无限大的空间里不同的位置。我们不关心这两个箭头有多长(即它们的模长大小),只关心它们指向的方向是否接近。
- 如果两个箭头指向几乎相同的方向,它们之间的余弦角度会非常小,接近0度,那么它们的余弦相似度会接近1,意味着它们很相似。
- 如果两个箭头相互垂直(形成90度角),则它们的余弦相似度为0,表示它们在方向上没有重叠部分,因此认为它们是正交或者不相关的。
- 当两个箭头完全反向时(形成180度角),它们的余弦相似度达到最小值-1,这表示它们在方向上是完全相反的。
所以,余弦距离通常是指1减去余弦相似度,是一个介于0到2之间的值(0表示完全相同,2表示完全相反)。但在实际应用中,更常用的是余弦相似度,它是直接计算两向量夹角余弦值得到的,范围在-1到1之间,越接近1表示越相似。在文本分析中,如果我们把每篇文章看作一个词频向量,那么余弦距离就可以用来判断两篇文章内容上的相似性。
pgvector 中的索引
pgvector 提供 2 种类型的索引,IVFFlat 和 HNSW,它们都是近似最近邻 (ANN) 索引,用于加快搜索相似向量的速度。选择合适的索引取决于几个因素,以下是它们的主要区别:
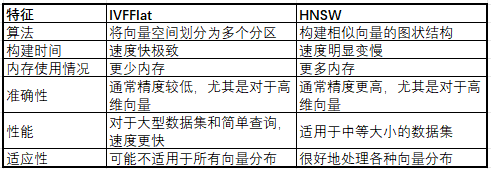
通过真实世界的例子了解 IVFFlat 和 HNSW
想象一下,你住在一个城市,需要找到一家与你喜欢的餐厅相似的餐厅(“最近的邻居”)。
IVFFlat 就像拥有一张带有标记社区的地图,具有以下特点:
根据一般特征将城市划分为不同的区域。
可以快速告诉您哪些社区可能有类似的餐厅。
将您带到那些可能很近但不一定在各个方面都最相似的社区中的餐馆。
更快地开始使用地图(更快的索引构建)。
存储地图所需的内存更少。
HNSW就像一个乐于助人的当地导游,具有以下特点:
非常了解这座城市,了解餐厅之间的联系(相似的口味、氛围等)。
可以快速将您带到您最喜欢的餐厅,即使它们不完全相同。
导游需要更多时间来了解城市(建立索引)。
导游需要记住更多信息(更高的内存使用率)。
选择正确的方法取决于您的优先事项
准确性:HNSW 就像导游一样,优先考虑找到与您最喜欢的餐厅最相似的餐厅,即使需要更长的时间。
速度:IVFFlat 就像地图一样,专注于快速找到类似的餐厅,即使它并不完美。
HNSW 更适合复杂的城市布局(高维数据)。而 IVFFlat 更适合大城市(大型数据集)。
数据嵌入过程
要创建向量数据,我们首先需要生成它。创建向量数据所涉及的过程称为嵌入,它就像一种秘密语言,以数字形式弥合了计算机数字形式的文字、图像或声音世界之间的差距。
收集数据:想象一个装满书籍的书架,一个有很多艺术作品的艺术画廊,或者一堆一起演奏的旋律。当我们开始嵌入时,这意味着我们正在收集我们想要显示为向量的基本内容。
选择嵌入模型:对于特定类型的信息,有不同的嵌入模型。一些常见的是:
HuggingFace 或 来自OpenAI 的text-embedding-ada-002 用于文本
VGG16 或 ResNet50 用于图像
Audio2Vec用于声音
训练模型:这就是奇迹发生的地方!该模型分析数据,识别模式、关系和隐藏的含义。它将单词、图像或声音映射到其相应的向量,为每个向量制作唯一的数字表示。
生成向量:一旦模型学会了数据的语言,它就可以根据需要将新的输入转换为向量。
HuggingFace 或 OpenAI 嵌入模型 – 选择什么?
为满足您的嵌入需求,在 Hugging Face 和 OpenAI 之间进行选择取决于几个因素:
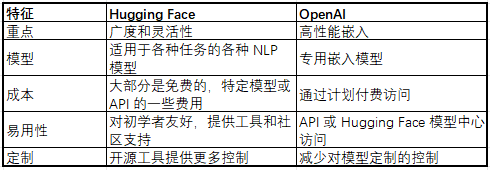
最终,最佳选择取决于您的具体需求、预算和技术专长。在做出决定之前,请仔细考虑您的优先事项并比较可用选项。
注意:我们将在即将发布的博客中介绍通过不同模型嵌入的数据
使用 pgvector:一个实例
想象一下,我们将各种单词作为向量存储在数据库中。然后,我们向数据库提供不同的单词以找到最相似的单词
我们将存储在数据库中的单词是 Apple、Banana、Cat 和 Dog
我们要搜索的单词是Mongo和Horse
创建扩展:在计算机上安装 pgvector 后,您首先需要创建所需的扩展
create extension vector;
创建表:存储向量数据
CREATE TABLE items (id bigserial PRIMARY KEY, name varchar(100), embedding vector);
生成嵌入
我们将使用 HuggingFace 来生成我们的嵌入。
安装所需的 Python 包
pip3 install sentence-transformers
pip3 install langchain
用于生成嵌入的 Python3 代码
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name='all-MiniLM-L6-v2')
print(embeddings.embed_query("Apple"))
注意:这里用于生成嵌入的模型是 all-MiniLM-L6-v2′
下图显示了单词 Apple 的嵌入:

将数据插入数据库
INSERT INTO items (name, embedding) VALUES (‘Apple’, ‘’);
注意:将Your_Apple_Embedding替换为原始嵌入,如上图所示
同样,我们将在数据库中插入其他向量,即香蕉、猫和狗。
插入所有关键字后,我们可以检查项目表中的行数。
select count(*) from items;
count
-------
4
(1 row)
向量搜索
为了找到一个单词,我们将再次为该单词创建嵌入,并利用生成的嵌入在数据库中搜索该单词。
在下面的查询中插入生成的(Mango)嵌入以获得结果:
SELECT name, 1-(embedding <=> '') as cosine_similarity FROM items ORDER BY cosine_similarity DESC LIMIT 2;
SELECT 查询结构的细分
SELECT name:这将从项目表中选择项目的名称。
1-(embedding <=> '<Mango_embedding>')as cosine_similarity: 此表达式计算每个项的嵌入与“Horse”的指定嵌入之间的余弦相似度,并将结果别名为cosine_similarity列。
embedding <=> '<Mango_embedding>': 此算子计算两个向量之间的余弦相似度。它将每个项的嵌入(存储在嵌入列中)与“Mango_embedding的占位符进行比较。
1 – ... : 从 1 中减去相似度计算的结果以反转比例,值越大表示相似度越大。
ORDER BY cosine_similarity DESC: 这将根据计算出的余弦相似度按降序对结果进行排序。这会将与“Mango”最相似的项目放在顶部。
LIMIT 2: 这会根据计算出的余弦相似度,将输出限制为仅前 2 个最相似的项目。
最后,通过运行上述查询,我们得到的结果如下:
name | cosine_similarity
--------+--------------------
Banana | 0.5249995745718354
Apple | 0.4006202280151715
(2 rows)
在下面的查询中插入生成的(Horse)嵌入以获得结果:
SELECT name, 1-(embedding <=> '') as cosine_similarity FROM items ORDER BY cosine_similarity DESC LIMIT 2;
name | cosine_similarity
------+---------------------
Dog | 0.5349170288394121
Cat | 0.41092748143620783
(2 rows)
结果分析
芒果和马没有直接出现在表中:因为它们没有在结果中列出,如果它们被列出,则会返回完美匹配(余弦相似度为 1)。
Banana 和 Apple 与 Mango 在语义上有适度的相似性:
Banana (0.5249995745718354) 是最相似的,但不是完全匹配。
Apple (0.4006202280151715) 的相似度较低,表明关系较弱。
Dog 和 Cat 与 Horse 具有适度的语义相似性:
Dog (0.5349170288394121) 是最相似的,但不是完全匹配。
Cat (41092748143620783) 的相似性较低,表明关系较弱。
值得注意的是,余弦相似度范围为 0 到 1
1 表示完全匹配,这意味着项目在用于比较的表示形式方面是相同的。
0 表示完全不相似,这意味着这些项目的表示形式没有重叠。
介于 0 和 1 之间的值表示不同程度的相似性。
在即将发表的博客文章中,我们将探讨 LLM 与 PostgreSQL 和 pgvector 的最佳利用,以有效地解决现实世界的场景。


