




不少人在使用MySQL和Redis上都有误区。比如说MySQL慢,比如count一个1000万级别的数据,然后把它存到Redis中。理由是因为Redis快。其实理解是不对的。
这是把MySQL等数据库的计算过程说的慢,查询结算结果的快做了一个不公平的比较。好比一个人从小学读到大学毕业,拿到了文凭。用了16年。而现在另外一个只看文凭这张纸,只用1秒。这本身就没有可比性嘛。
理论上来说把这个结果存在Oracle、PostgreSQL和MySQL中,他的效果也不慢。
说清楚这个以后,还是要说如果有非常频繁访问的数据,还是应该放在Redis中,毕竟能解放在线交易数据库,就解放一点吧。这里的频繁我指的是这些数据每秒100次以上的场景。毕竟每秒几十次的通过索引点查的请求对关系型数据库来说,这都不叫事(其实每秒几万也问题不大,感兴趣的话看我早期的公众号。毕竟没有Redis之前,日子也不是不能过。)
但是有了Redis可以让日子过的更好。当然也要考虑万一Redis被击穿后,交易数据库也要用尽全力扛起来一些请求。不能说Redis无法启动,整个业务就瘫痪。
下面开始说比较原始的数据同步做法。
在MySQL数据库上建立一个表,并且写入数据。
编写一个同步脚本。这个在网上也能找到。

在一个第三方的机器上远程执行MySQL的查询。可以看到写入的数据。然后将这个数据送到Redis中。

执行如下的命令就可以送到Redis中。然后再redis中查询key的值。

如果发生变更的话,需要手工执行命令(或者有个定时任务去送)比如再次执行上面的命令(或者有个定时任务去更新)
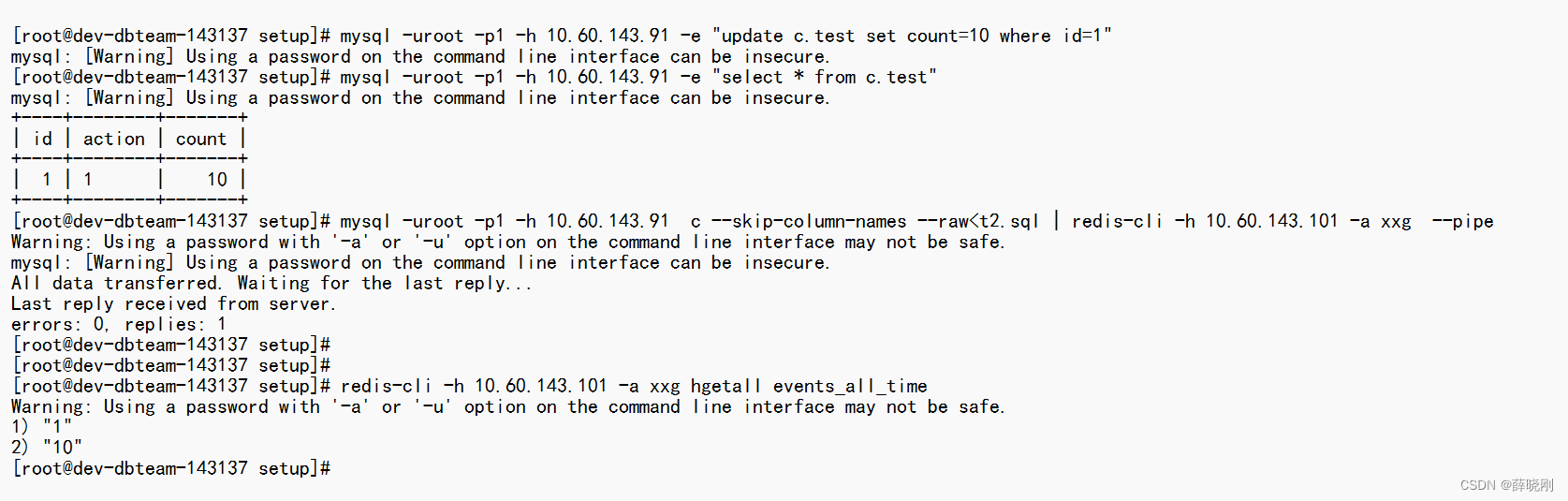
这是常规做法,不少开发人员做法都是定时更新的。我以前问他们,那不是不准确嘛?开发说,不重要。
可见这种有误差在有些系统中不在乎或者在乎也没有好办法。最好的还是OLTP数据库发生变更然后就送到KV数据库中。但是这是异构数据库。同构数据库大家都知道解析日志,比如CDC工具就是这样实现的,代表产品如OGG这种。
