AntDB 分布式内存数据库支持全内存态的运行模式,将热数据常驻内存。但内存存在易失性的特点,需要一种机制去保障这部分数据的高可以用。通常在实际使用过程中会配置多个数据副本来保障数据分片的高可用。同时 AntDB 分布式内存数据库提供一种 CP(Check Point)方案,将当前内存中的数据持久化到磁盘,形成以时间轴为连接线的基数文件备份体系,使用者可以选取时间轴上任意点的备份文件进行数据恢复。
为了更好地理解 AntDB 分布式内存数据库的 CP 过程,首先了解一下几个基本概念:
● 事务号:事务提交的事务号,在事务提交时会为事务分配一个事务号,并保证事务号严格递增,不会出现空洞。合法的事务号从1开始。每个CP都有对应的最后事务号,每次CP成功后,当前事务号之前的事务日志可以进行清理。CP要求落下来的文件事务是完整的,包含且只包含到当前事务号之前(包含当前事务号)所有的数据。既不能包含某些事务的部分更新,也不能缺少小于当前事务的数据。
CP文件包含的内容:表列表、事务号和所有表的数据。对于单张表,包含表的元数据(表空间信息、字段、索引和溢出页信息)和表数据。表数据是按照块存放的,一张表有多个块,块个数可扩展。每个块有固定个数的行,每个行都有唯一的编号,称为oid,oid从1开始。与oid一些相关的操作,包括备机复制恢复、CP文件恢复和binlog恢复,oid都不会改变,因此在记录CP文件时也会保证恢复后oid不会发生变化。
● 溢出页(overflow):对于超大字段,比如varchar等,超出255 后,就不再与普通的字段放在一起,而是另外存储,对于某一行上的某个超大字段,在行上存储rowid,通过rowid可以在溢出页中找到对应的数 据。而溢出页上的数据,每个内存都是固定大小,上面存储了下一条的rowid,通过链表的方式将一个字段的值串起来。溢出页中的rowid 与表空间中的rowid不同,溢出页只关心数据是否正确,并不保证在备机恢复或者从CP文件恢复后的rowid与恢复前相同,只要求数据内容一致。所以CP的方案中,针对溢出页,主要考虑数据是否能够恢复一致。
CP 状态标识分两个阶段:
(1) 将表数据写入文件中,这个阶段称为 dump。
(2) 将写表数据过程中产生的操作对应的数据,回写到文件中,这个阶段称为 restore。
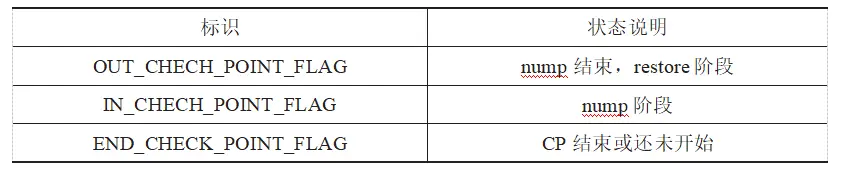
根据 CP 的这两个阶段,CP 有三个标识如表 4-1 所示。
如图 4-5 所示为 AntDB 分布式数据库一个完整的 CP 的整体过程。

(1) 加 DDL 锁。CP 操作过程中,不允许对表做增删字段等修改表结构的动作,加 DDL 锁可以防止 DDL 操作,也不会创建新表和删除表。同时为了减少 DDL 锁持有时间,在拿到 DDL 锁后,将当前所有的表加上读锁,记录当前表列表,然后释放 DDL 锁。后续针对记录的列表来进行操作。
(2) 加 DB 锁(lock_db)。DB 锁主要是与事务做排他操作,可以保证在DB 锁加锁后,没有事务正在提交或回滚。持有 DB 锁之后,记录当前的事务号, 作为 CP 的事务号。在事务提交或回滚时都要加事务锁,事务锁之间是可以并发的,而与 DB 锁是互斥的。
(3) 获取正在进行的事务列表。在加上DB 锁后,还有一部分事务正在进行,为了保证 CP 文件中的数据是事务完整的,需要记录正在进行的事务,提取它们的 undo 数据,回写到 CP 文件中。此时设置了 AntDB 分布式内存数据库的 CP 标识为 IN_CHECK_POINT_FLAG。
(4) 解锁 DB 锁。解锁 DB 锁后,事务可以正常提交或回滚,提交或回滚时,会记录当前事务执行过的操作,然后记录 restore 信息,在 restore 阶段将数据回写到 CP 文件中。
(5) dump 表数据。一个表对应一个线程,将表写入磁盘中。在这个过程中,所有事务执行的修改操作,都会记录 restore 信息。
(6) 等待之前记录的所有事务结束。在表数据全部落地之后,设置AntDB 分布式内存数据库的 CP 标识为 OUT_CHECK_POINT_FLAG,然后等待之前加 DB 锁时获取的事务都提交或回滚。在这些事务提交或回滚时,按照需要将它们的 undo 数据覆盖到 restore 信息上。
(7) restore。将之前所有的 restore 信息回写到 CP 文件中,对于表空间来说,restore 中记录了 oid。根据 oid 可以计算出这一行在 CP 文件中的偏移量, 然后将行数据写入 CP 文件中。对于溢出页来说,通过 rowid,计算在 CP 中的偏移量,重写 CP 文件。
(8) 记录 frm 文件。frm 文件是记录表元数据的方式。当 AntDB 分布式数据库恢复时,将之前对应事务号的 frm 恢复到对应目录(表所在的库都会有独立的文件夹),让重新加载。CP 记录 frm 文件时,文件名以 'db-table.frm. trx_id' 格式命名。
(9)删除临时文件。在 dump 文件和 restore 过程中操作的文件,都是以“.tmp”作为后缀的临时文件,这时将这些文件都删除。
(10) 记录 antdbinfo.txt。antdbinfo.txt 文件记录了 CP 事务号、当前 CP 对应的表列表。在 AntDB 分布式内存数据库通过 CP 恢复时,加载 antdbinfo. txt,读取事务号和表列表,再根据表列表和事务号信息获取需要加载的表和表对应的文件。antdbinfo.txt 文件有两个,一个带事务号,一个不带事务号,它们一个是另一个的硬链接。
结束,设置 AntDB 分布式数据库的 CP 标识为 END_CHECK_POINT_FLAG。
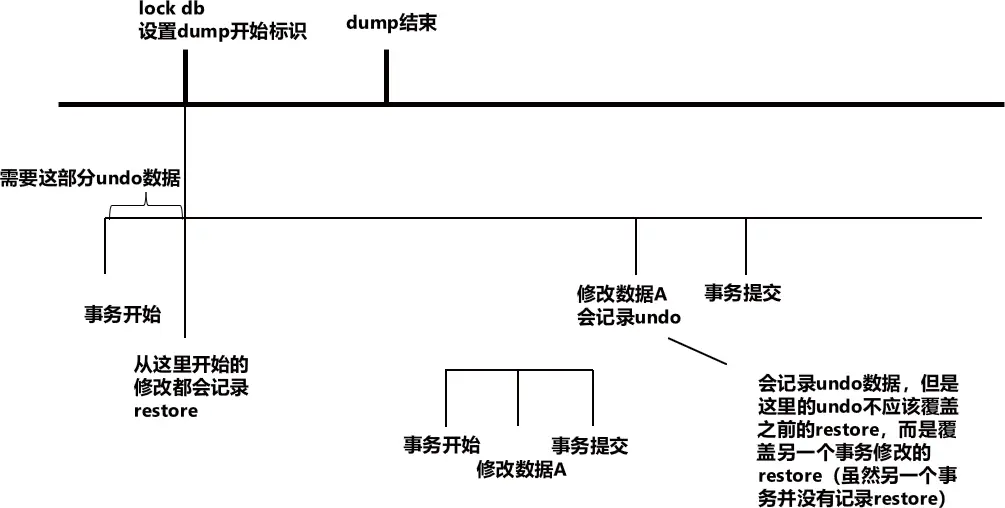
在 CP 过程中,加 DB 锁之后,会记录当前未完成的事务,这些事务的部分 undo 数据需要覆盖掉 restore 信息。按照下面原则:“CP 数据包含且只包含当前事务号和当前事务号之前的所有事务修改记录”。CP 开始时未提交的事务包含的操作应该排除在外,所以要将未提交事务修改过的数据对应的 undo(并且这些修改是在 CP 开始之前)覆盖掉 restore。之所以不能把所有 undo 数据都覆盖掉 restore,是因为未提交事务中的 undo 可能记录的是在 CP 开始后事务的修改。在 CP 开始后的修改,本来也有对应的 restore 数据,所以不使用 undo 不会影响正确性,undo 数据覆盖示意图如图 4-6 所示。