




上一篇生成对抗网络GAN系列之一:基本原理和结构细讲我们分解了GAN的基本原理和结构,今天我们具体来看看三个最基础,也是最常见的GAN模型:深度卷积生成对抗网络DCGAN、条件式生成对抗网络cGAN、Wasserstein GAN(WGAN)。
1
DCGAN
卷积神经网络CNN是机器学习特别是计算机视觉中应用最广泛的网络结构,人们自然能想到把它用到GAN上。2014年GAN提出后,2015年Facebook AI实验室就把CNN用到GAN上,提出了DCGAN,即Deep Convolutional Generative Adversarial Networks,结构如下:
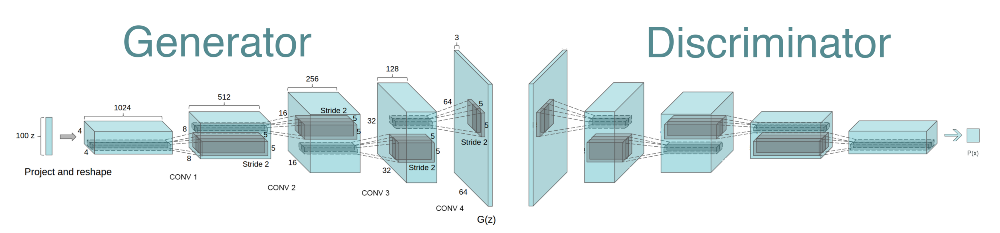
整个网络结构很清晰,判别器是我们常见的CNN,生成器是CNN的一个逆过程,我们称为反卷积。
具体讲,DCGAN主要提出四个设计点:
使用卷积层代替池化层
去掉全连接层
使用批归一化Batch Normalization
使用恰当的激活函数
以下分别简要说明。
1.使用卷积层代替池化层
把生成器和判别器中常见的池化层全部去掉。
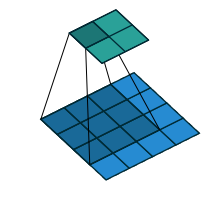
判别器中使用步长卷积(strided convolutions)代替池化层,如下图,也就是常见的卷积计算方法,输出维度变小了。
生成器中使用分数步长卷积(fractionally-strided convolutions)代替池化层,如下图,输入中会填充0值,输出维度变大了。
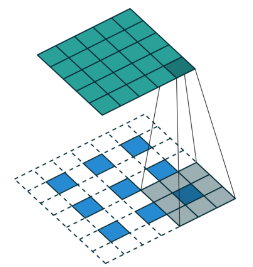
2.去掉全连接层
全连接的缺点是参数太多,参数多了也容易出现过拟合,去掉全连接层可以使得模型更稳定。
3.使用批归一化
归一化Batch Normalization现在是CNN网络的标配操作,可以使每一层的输出差异化不会太大,让网络更容易收敛。
4.使用恰当的激活函数
生成器里面各层使用ReLU,输出使用Tanh。判别器各层均使用LeakyReLU。
DCGAN有很多广泛的应用,取得的效果也不错,比如残缺图像补全、人脸图像算术运算(微笑女人的脸-女人普通表情+男人普通表情,可以得到微笑男人的脸)等。
2
cGAN
到此,虽然我们知道了GAN的基本结构和一个基本模型DCGAN,但在实际生成数据的时候,模型怎么知道要生成什么数据呢?一般情况下,我们得给模型指定一个条件,比如“生成猫的图片”,“根据相片生成对应的描述”,这里指定的“猫”和“相片”就是条件,这就需要条件式GAN,conditional GAN,简称cGAN。
cGAN的结构如下:
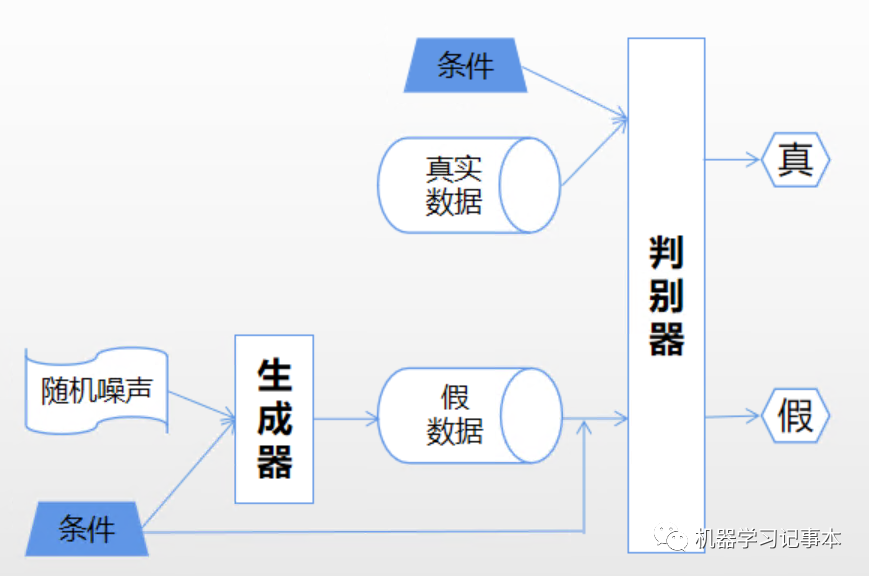
和基本的GAN结构相比,区别只是在生成器和判别器的输入里都加入了条件。
生成器的输入里,在随机噪声上加入条件。
判别器的输入里,在真数据和生成器生成的假数据上都加入条件。
cGAN的损失函数里生成器和判别器也对应加上条件,即下式中的(x|y):
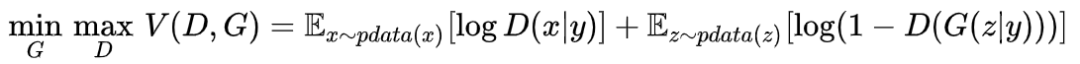
在具体实现时,如何加入条件呢?只要能加入代表条件的特征表示都行。例如要实现“根据指定的文本描述生成图片”,可以把指定的文本的向量表示作为条件和随机噪声的向量相乘或者相加。随机噪声的生成方式、条件的生成方式、噪声和条件的融合方式可以结合具体项目而定。
我自己在训练过程的一些经验,在给定条件下如果生成的数据要求高,比如生成数据的维度高并且各个维度都要符合分布,那么生成器学习难度高,可以在生成器损失函数中加一个额外的部分,让生成数据逼近给定的条件。
3
WGAN
GAN最大的问题就是训练不稳定,我在训练过程中就遇到了刚训练不久判别器就收敛,loss变为0,没达到期望的相互博弈。WGAN的目的就是解决GAN训练不稳定的问题。
WGAN的作者Martin Arjovsky在2017年专门写了一篇论文从数学上详细推导了为什么原始的GAN训练不稳定(https://arxiv.org/pdf/1701.04862.pdf).
该文的结论是:在原始GAN损失函数的定义下,如果判别器训练得太好,生成器会有梯度消失问题,如果判别器训练得太弱,又不能指导生成器。所以根源就在损失函数定义,于是作者提出了新的基于Wasserstein距离的损失函数。基于这个新损失函数再加上一些技巧就是Wasserstein GAN,简称WGAN。
Wasserstein距离又叫Earth-Mover距离,简称EMD,中文叫推土机距离。其来源于一个关于运输的动态规划问题:X个始发地有若干堆土要运到Y个目的地,每个目的地需要的土有规定的数量,始发地土的总量等于最终目的地收到的土的总量,如何分配运输才能使费用最小?
转换成GAN里的场景,目的地规定的土的分布就是真实数据的分布,源地土的分布就是生成数据的分布,目标就是找到一个方案最小化这两个分布间的距离。用公式来表示就是:
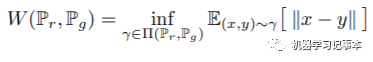
其中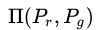 表示
表示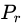 和
和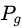 组合起来所有可能的联合分布的集合,(x,y)表示符合这个联合分布的采样,EMD就是所有这些采样的距离的期望的下界。
组合起来所有可能的联合分布的集合,(x,y)表示符合这个联合分布的采样,EMD就是所有这些采样的距离的期望的下界。
WGAN的原始论文https://arxiv.org/pdf/1701.07875.pdf 中证明了损失函数中使用EM距离要优于GAN原始的损失函数,能提供更有意义的梯度。
EM距离本身要解起来比较困难,经过作者推导、变形,最后WGAN的损失函数和原始GAN相比只是把loss中的log去掉了。没错,你没看错,就这么简单,绕了这么大个圈子最终的变化就这么少!
关于代码中如何实现这个新的loss,这篇文章有特别好的详细的解释:https://machinelearningmastery.com/how-to-implement-wasserstein-loss-for-generative-adversarial-networks/
上面说了WGAN除了使用新的损失函数,还加了些别的技巧,总结起来就是:
损失函数中去掉log
判别器最后一层去掉Sigmoid,得到的是一般意义上的分数,而不是原始GAN判别器输出的概率
更新权重的时候,需要对权值裁剪在一个范围内,原因是为了满足理论推导中的一个Lipschitz条件
将Adam梯度下降方法改为RMSProp,这个是作者经过试验得出的经验,说可以让训练更稳定
最终的算法描述就是这个样:

和原始GAN结构一样,区别只是红框里面的部分。
4
总结
好了,今天要介绍的就这三个模型:DCGAN是一个经典的使用CNN的模型,效果很好;cGAN使用场景很多,因为很多数据生成是要指定条件的;GAN训练最大的问题是不稳定,WGAN有效的改善了这一问题。有了对这三个模型的了解,就可以自己动起手来做很多有趣的项目了。
