




最近工作中由于需要增广一些训练数据,除了使用普通基于规则的方法外,研究了如何使用生成对抗网络(Generative Adversairal Network,GAN)生成数据,经历了从头开始学习、不断理解其损失函数的真正含义、如何根据损失函数实现生成器和判别器、训练中从一开始生成数据完全不对到慢慢生成像样数据整个过程。有些问题从一开始困惑到找资料一步步细抠清楚,觉得有必要记录一下,一来系统整理以免之后忘记,再者希望对像我一样遇到同样问题的人有帮助。
1
什么是生成模型
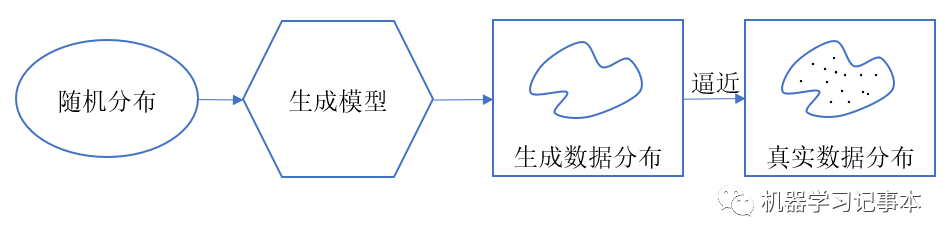
简单来说就是生成数据的模型。
在概率统计中,生成模型指能够在给定某些隐含参数条件下,随机生成观测数据的模型,通常情况下我们希望生成数据的分布能逼近真实数据的分布。对于真实数据,一般很难准确定义其分布函数,而是通过真实数据采样获得分布。
2
生成数据的意义
首先,最直观的例子,我们可以通过生成数据技术来做数据转换,比如更换人的肤色、发型,或者给定一个简单轮廓补全图像,或者还原以前老照片为彩色照片等。这些技术已经应用到各种app中,十分有趣。
其次,生成数据可以有效地补充监督学习训练数据集。监督学习常见的一个问题是有标签的训练数据不足或者不均衡,我们可以有针对性的生成需要的数据用于训练。
最后,生成数据可以进行一些有意思的艺术创作,比如让计算机生成一些天马星空的抽象画等等。
3
GAN的基本原理
生成对抗网络,顾名思义带对抗的生成模型网络,它是生成模型,并且整个网络结构中带有对抗过程。
为了方便理解,我们用一个常用的文物模仿例子来描述这个过程。假设一个山寨厂商G要模仿生产明代成化年间的青花瓷,一个文物鉴定师D专门鉴别青花瓷。一开始,G水平比较糙,模仿生产的产品太次,D一眼就看出来了,随口指出了很多破绽,比如明代青花瓷根本没有这种颜色,形状也不对。第二轮,G学聪明点了,改了很多显而易见的地方,但是D仔细观察,还是发现了很多问题,不过比第一版强多了。就这样,一轮又一轮,G不断学习改进,D不断鉴别纠错,最后生产的产品到了以假乱真的地步,有的产品连D都不太确定是真是假。
以上就是一个典型的生成对抗过程,映射到GAN中,上面的G就叫生成器Generator,负责生成数据,D叫判别器Discriminator,负责判断真假,整个训练过程就是一个互相博弈的对抗过程。
网络训练好后,喂一些随机数据给生成器,生成器就可以生成符合我们期望的数据。
把上述过程画成图,就是下面这个结构:
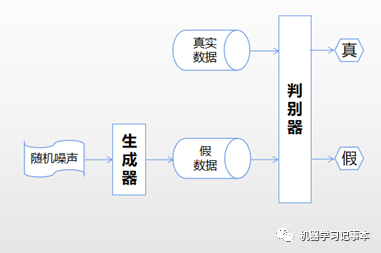
整个网络包含一个生成器和一个判别器。生成器通过输入的随机噪声生成假数据,希望能模仿真实数据。判别器输入有两部分,一是真实数据,二是生成器生成的假数据,判别器的目标就是尽可能分辨出哪些是真数据,哪些是假数据。这个逻辑容易理解,重点在于如何训练。
4
训练过程
我们还是以原始论文的算法描述出发来解释整个训练过程。

判别器训练
首先训练判别器k 步,上述算法描述的是同时训练真实数据和生成器生成的假数据,然后一起通过梯度上升更新判别器的权重。梯度公式在下一节单独讲解。梯度计算公式中前半部分针对的真实数据,后半部分针对的生成数据,这里不好理解的是在实现时如何把两部分数据传到同一个公式里面。对于真实数据,其实只有第一部分起作用,对于生成的假数据,只有第二部分起作用,实现时可以真假数据分开先后训练,不必混在一起训练。具体如下:
固定生成器的权重(一开始可以随机初始化,也可以预训练),输入一批随机噪声,生成假数据,输入判别器,其输出带入算法中第一个梯度公式,公式中只有第二个log函数起作用,更新判别器权重。
准备一批真数据,输入判别器,其输出带入算法中第一个梯度公式,公式中只有第一个log函数起作用,更新判别器权重。
生成器训练
判别器训练k轮后,训练生成器。固定判别器权重,向生成器输入一批随机噪声,生成数据传入判别器,判别器的输出带入算法中第二个梯度下降的公式,更新生成器的权重。
其中k值根据具体项目试验调整。我在实际训练过程中,如果k值过大,判别器学得太好,就调小一点,反之调大一点。
如此不断来回训练,判别器不断学习提高判别能力,生成器不断学习让生成数据像真实数据,希望能骗过判别器,达到博弈的目的。
5
重点:损失函数的理解
1.总体目标
整个网络训练的总体目标是:
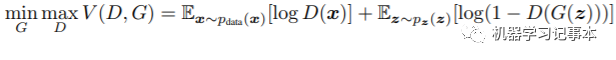
其中,G表示生成器,D表示判别器,D(x)表示数据通过判别器后的输出,即数据是真实数据的可能性,最大为1表示真实数据,最小为0表示假数据。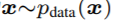 是符合真实数据分布的数据x,
是符合真实数据分布的数据x,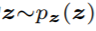 是符合噪声分布的噪声,
是符合噪声分布的噪声,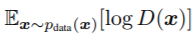 为真实数据通过判别器的输出取对数的数学期望,
为真实数据通过判别器的输出取对数的数学期望,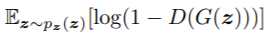 是噪声通过生成器生成数据,再通过判别器输出,1减去输出再取对数的数学期望。取数学期望是希望所有训练数据的平均值能达到这个目标。等号后面整个部分我们定义为V(D,G)。
是噪声通过生成器生成数据,再通过判别器输出,1减去输出再取对数的数学期望。取数学期望是希望所有训练数据的平均值能达到这个目标。等号后面整个部分我们定义为V(D,G)。
2.第一个理解角度:直观理解
判别器
判别器的目标就是要在固定生成器G时最大化V(D,G), 即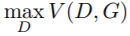 ,要最大化V(D,G),就是要最大化式子里第一部分的D(x)和最小化第二部分的D(G(z)),意思就是对真实数据x,要最大化判别器输出D(x),让其尽量接近1,对通过噪声z生成的数据G(z),要最小化其通过判别器的输出D(G(z)),让其尽量接近0。这刚好就是判别器要干的事,分辨出真实数据和假数据。
,要最大化V(D,G),就是要最大化式子里第一部分的D(x)和最小化第二部分的D(G(z)),意思就是对真实数据x,要最大化判别器输出D(x),让其尽量接近1,对通过噪声z生成的数据G(z),要最小化其通过判别器的输出D(G(z)),让其尽量接近0。这刚好就是判别器要干的事,分辨出真实数据和假数据。
实际计算时,数学期望就是取所有采样点计算的平均值,也就是算法描述中的
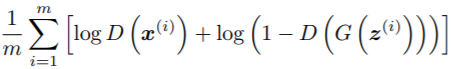
要最大化此值,所以采用梯度上升,其实等价于取反后的最小化,即我们常用的梯度下降。
生成器
在判别器学习一段时间后,生成器的目标是在固定判别器的时候(),最小化其值,即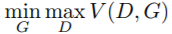 ,意思是判别器在最大化V(D,G)的时候,让这个最大值尽量小点,尽量让判别器不要识破自己,能骗过判别器。
,意思是判别器在最大化V(D,G)的时候,让这个最大值尽量小点,尽量让判别器不要识破自己,能骗过判别器。
这个时候由于固定了判别器,训练数据全是通过噪声生成的,V(D,G)中针对真实数据的第一个对数部分没有了,只剩第二个部分。目标是最小化第二个部分,即算法描述中的
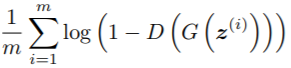
这个时候是要最小化,让判别器的输出尽量接近1,所以算法描述中使用梯度下降。
3.第二个理解角度:交叉熵
容易看出,判别器其实就是个判别真假的二分类器,对二分类问题我们常用的损失函数是交叉熵:
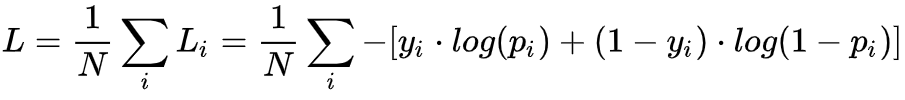
看看这个式子是不是和V(D,G)长得很像!
上式中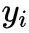 表示真实标签,
表示真实标签,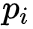 表示预测值。
表示预测值。
判别器
真实数据标签为1,上式中为1,第二部分为0,只剩下第一部分
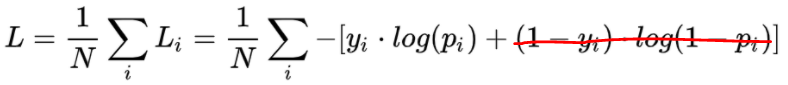
最小化第一部分,等价于最大化论文算法中的第一部分
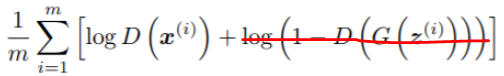
假数据标签为0,交叉熵中为0,第一部分为0,只剩第二部分,对应等价于论文算法中的第二部分,就不添加图片列举了。
所以判别器的损失函数就是交叉熵!
生成器
训练生成器时全为假数据,但是生成器为了欺骗判别器,训练时标签标记为1,即骗判别器说自己是1,交叉熵中为1,只剩第一部分
交叉熵要最小化上式,这和生成器要最小化下式是同一回事
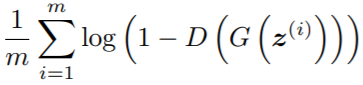
这个地方稍微有点绕,D的输出相当于,前面的1去掉不影响最小化,D前面的负号提出去也不影响最小化,因为去掉1并把负号提前以后,函数的变化趋势是一样的,这样两个公式在解决同样的问题。
所以不管是判别器还是生成器,GAN的损失函数其实和交叉熵的本质是一回事!
3.化繁为简看本质
有了上面的理解,我们就可以去掉外壳,看各个部分数据训练时损失函数真正的核心部分:
判别器正样本: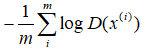
判别器负样本: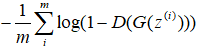
生成器: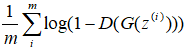 ,简化为
,简化为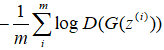
6
代码实现
上面只是讲了GAN的最基本的原理和原始论文的损失函数,自从2014年Ian J. Goodfellow提出GAN以后,目前已经有300多种变体的GAN,github也有很多对应基本结构和变体结构的代码实现。
对于基本结构,实现时损失函数直接使用训练平台自带的二分类交叉熵loss即可,Tensorflow中是binary_crossentropy。因为真实标签为1,假数据标签在判别器中为0,在生成器训练时为1,带到交叉熵中自然和理论推导中的公式一致。
以上就是我自己使用过程中对GAN的理解,特别是对损失函数的理解,但这只是进入GAN的第一步。如上所述,业界根据不同的需求已经研究出了300多种不同的GAN,正是这些五花八门的GAN才让各种有趣的应用变成可能,下一篇文章我们选最常见的几种结构谈谈。
