排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
数说
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
数说
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
从语音到自然语言处理
从语音到自然语言处理
机器学习记事本
2019-12-15
743
自然语言处理(NLP, Natural Language Processing),顾名思义就是使用各种方法处理自然语言。既然是自然语言,肯定离不开语音,所以广义的自然语言处理既包括语音的处理,又包括文字、文本的处理。在实际处理过程中,由于语音处理涉及各种信号处理的知识,和文字处理有很多不同,所以狭义的自然语言处理也就是大家平时说的NLP主要指对文字、文本的处理,比如机器翻译、文本情感分析、文章摘要、文本分类等。
最近我工作中项目涉及从最前端的语音处理到最后的意图识别,由于之前没有语音处理的经验,特别希望能借此机会对整个流程有一个全面的了解。这篇文章是我从基础开始整理学习的笔记,包含各种网上搜索、书本阅读和向语音处理同事请教的内容等,主要目的是梳理出一个典型的从语音识别到自然语言处理应用的流程。对语音处理部分不求精通,但求知道来龙去脉,特别是一些基本操作如采样、时域频域转换等。部分表述可能不够专业和准确,但希望对像我一样想了解从语音处理到自然语言处理流程的同学有所帮助。
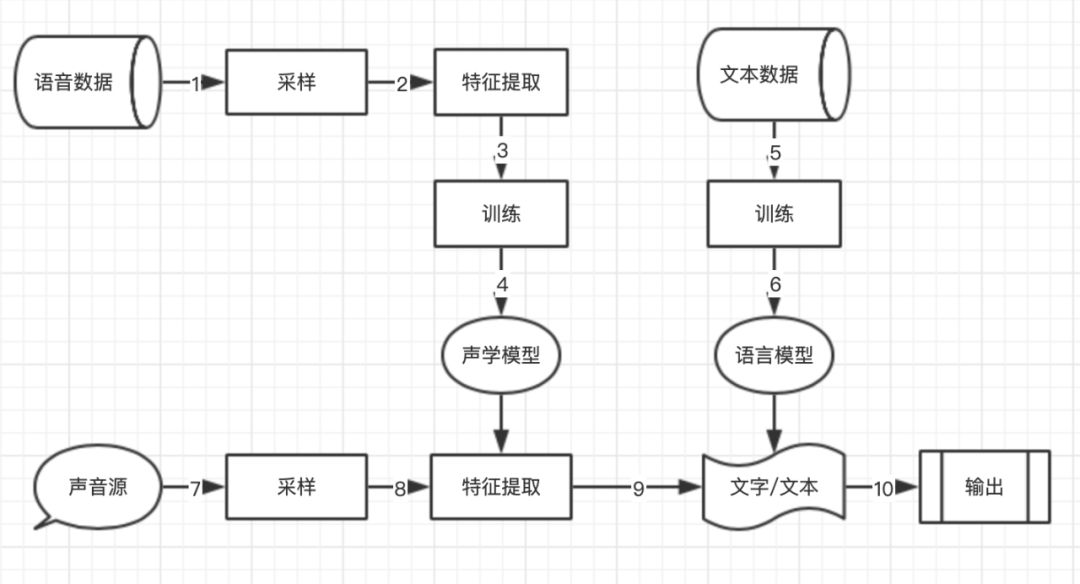
图1抽象了一个典型的以语音作为输入,以文本作为输出的流程图。具体到实际应用,比如我们说一段中文,通过软件翻译输出英文,或者我们说一条命令,让机器识别命令的类型等等,都可以抽象为这个流程。本文通过解释此流程图中每个节点来讲解整个过程。此流程图也可扩展到其他非文本输出的应用,比如问答系统,我们稍后说明,所以了解了此流程,其他各种含语音处理的NLP应用核心都类似,万变不离其宗。
图1 总体流程
语音采样
日常生活中我们会接触到各种信号,最常见的如电信号、光信号、声音信号等,语音属于声音信号。如果信号的幅度和时间都是连续的称为模拟信号,若幅度和时间都是离散的则称为数字信号。
我们说话的信号本身是连续的,但如果要用计算机处理,需要对连续的信号进行采样,得到幅度和时间都离散的数值。
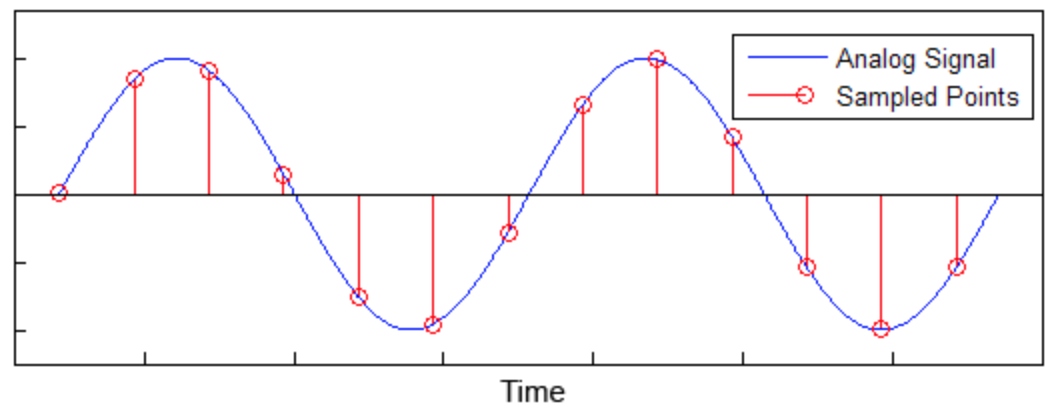
图2是一个信号幅度随时间变化的例子,
横坐标表示时间,纵坐标为
幅度
,
蓝色
曲线
表示连续
的模拟信号,
红色的小圆圈即为
信号采样
。
图2 采样
这里主要讲语音采样的三个重要的概念:
采样频率:
每一秒钟采样次数,比如每一秒钟采样24000次,则采样频率为24000Hz。采样频率越高,采样后得到的声音音质越好,比如44100Hz为理论上的CD音质。
帧:
把多个采样点的值放在一起,就构成一帧。比如说帧长是1024,意思是说一帧里面有1024个采样点,这1024个数据可以表示为一个数组或者向量供下一步使用。
帧移:
为避免采样信息遗漏,通常相邻两帧之间会重叠部分采样区域,两帧起始位置距离就叫帧移。图3中每帧长25ms,帧移10ms。
图3 帧移
如果以44100的频率采样,帧长1024,则一秒内采样的帧数为44100/1024=43帧,那么每一帧播放时间为1000ms/43=23.26ms。
特征提取
通过采样,我们得到了可以使用二进制表示的计算机能处理的数据,接下来就是看怎么从这些数据中提取需要的特征。
上面的采样和得到的数据都是从时间域(时域)角度分析的,优点是容易直观地看到信号随时间变化的形状,但是要更进一步对信号进行分析,需要从时域转换到频率域(频域)。通俗地讲,就是在频域上能把信号数据掰得更开来分析,下面我们具体来看怎么转换。
注意,
这个频域中的频率指的是声音信号的频率,即发声物体每秒振动的次数,和上面的采样频率不是同一个事。
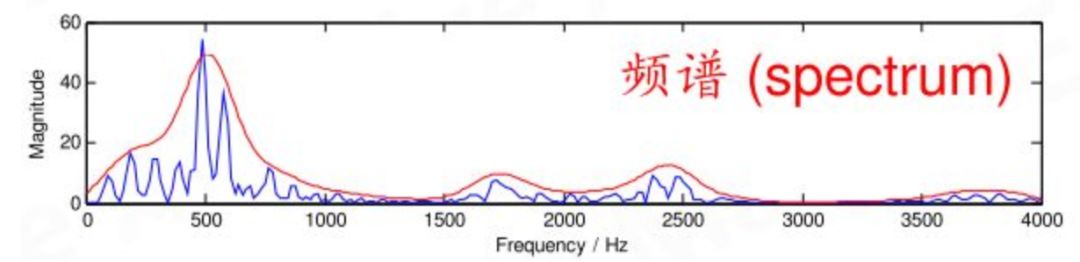
对很短时间内的一段语音数据,比如一帧数据,它是由多种不同频率信号叠加而成的,可以通过傅里叶变换(FT)把不同频率对应的幅度分解开来。不理解傅里叶变换细节也没关系,傅里叶变换直观上是说一个给定的波形可以分解成若干正弦和余弦波,那么对一段语音数据就可以用傅里叶变换把不同频率对应的幅度分解开来。这个幅度就是声音的能量,幅度越大,能量越大。以频率为横坐标、幅度为纵坐标的图就叫频谱。图4就是一个频谱图的例子。通过傅里叶变换,一帧的采样数据向量变成了另外一个向量。
图4 频谱图
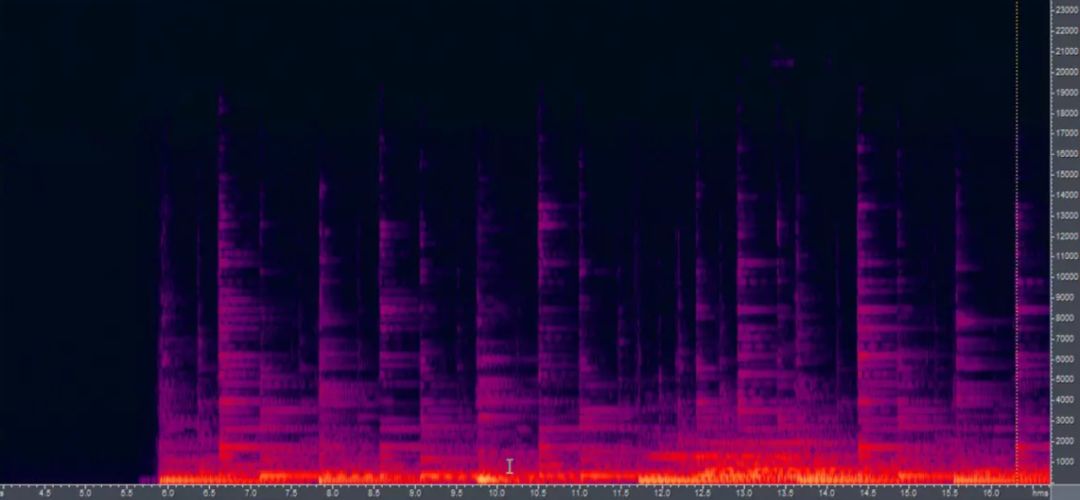
是不是觉得有点绕了,集中精力再坚持一下,接下来这个很重要。记住上面这个图是一帧数据对于的频谱图,为了直观观看,根据每个横坐标频率对应的能量(幅度)大小,用颜色来表示,能量越大颜色越深,我们把频谱反转90度倒立起来,然后把所有时间上的频谱图都连起来,就构成了语谱图。图5就是一个语谱图的例子。
图5 语谱图
语谱图中横轴仍然是时间,纵轴右边是频率,图中不同颜色的点就是该横轴时间点对应纵轴一个频率上能量(幅度)的大小,实际上是把一个三维的图放在二维中显示。
费这么大劲做以上转换,主要为了刚才说的在频域上能获取到更多的信息,提取到更多我们可以用来计算的特征。从计算的角度讲,时域向频域转换前的数据是时间序列上若干帧的采样数据向量,转换后还是时间序列上的数据,不过每个时间段上对应的数据向量转换成了按不同频率排列的能量向量。这样我们就得到了最基本的特征,特征向量可以在下一步用来作为声学模型的输入。
实际工程中,还需要对信号进行滤波(去掉某些频率的信号,去掉噪声)或者加噪声,通过FBank(FilterBank)特征提取、MFCC(
Mel Frequency Cepstral Coefficient
)特征提取,这些方面我没有深入学习过,就不班门弄斧了。
对于时域到频域转换以及语谱图的理解我也花了一些时间,如果你是刚开始涉及,估计也会有同感,不太好理解。
声学模型训练
到此,已经解释了图1整体流程中的标号为1、2的步骤,我们可以从原始的语音中提取到需要的信息,通过向量的形式表示。接下来就是步骤3、4步涉及的声学模型训练。
声学模型的目的是把通过特征提取得到的向量转换为文字,别忘了我们的最终目的是分析、理解语音的意思,理解就需要先转为文字。转换的方式有多种,一般先转为音素(发音的基本单位),如果是英语则由音素构成单词,中文则由音素构成拼音或者汉字。可以看出,声学模型是一个典型的序列预测问题,即由特征提取的向量序列预测对应字的序列。
以前
传统的最著名的模型是GMM-HMM,其使用隐马尔科夫链根据概率预测文字序列。近年来由于深度学习的发展,基于深度学习的声学模型是主流。深度学习用来处理序列问题,当然是使用RNN、LSTM、GRU以及最近的Transformer模型。
语言模型训练
通过前一步声学模型我们可以从声音得到文字,接下来就是NLP常规要解决的问题了,即通过文字根据各种场景训练语言模型,这是图1中标号5、6的部分。这个部分我以前公众号文章谈了很多,这里就不展开了。主要思路就是得到文字的向量表示(word embedding),例如使用近年流行的BERT,GPT等模型,然后根据应用场景训练应用相关的模型,比如情感分类问题训练分类模型,翻译问题训练翻译模型,意图识别问题训练意图识别模型。
推断
有了从步骤1到6得到的声学模型和语言模型,我们就可以对新来的语音进行预测推断了,即图1中第7到10步内容。
第7、8步的语音采样、特征提取和第1、2步为声学模型准备训练数据时的
语音采样、
特
征提
取
方式一样。第9步使用已训练好的声学模型把第8步得到的特征转换为文字,第10步使用训练好的语言模型把文字转换为对于应用场景的输出。比如情感分类就输出该段语音属于哪类情感,翻译问题就输出翻译的目标文字。
至此,我们描述完了整个流程,如同文初所讲,模型应用和这个流程可能不一致,比如对话系统,在第10步理解了对话中上一条语音的意义后,下一步要回复对话,这时再加上一个语音生成系统,但是系统的流程核心仍然相同。
以上就是我最近对从语音到自然语言处理的一个总结,由于之前对语音部分不熟悉,主要时间都花在语音处理上了。如果你想了解整个流程的全貌,希望对你有所帮助。
数据库
文章转载自
机器学习记事本
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨