




最近打算把现有工作中用的传统机器学习算法(随机森林,SVM等)改用深度学习算法,看看性能会不会有改进。本文记录一下探索的过程。
首先要选择从哪一个深度学习算法开始,本着从简单到复杂一步步来的经验,当前最基本的深度学习算法当然是卷积神经网络(CNN)和循环神经网络(RNN),而CNN更直观,最终选择从CNN开始。
CNN使用最广泛的例子在图像处理领域,而我工作中要处理的是文本分类,所以要看看如何把CNN用在文本处理上。俗话说要使工作有效率,需要站在巨人的肩膀上,而不是自己闭门造轮子。这个巨人就是YoonKim 2014年发表的论文《ConvolutionalNeural Networks for Sentence Classification》https://arxiv.org/abs/1408.5882 , 这篇论文应该算是CNN用于文本分类的范本。
CNN回顾
网上介绍CNN的好文章很多,在此就不详细介绍了,有兴趣的自行搜索,这里只是简单回顾一下为后面的使用做铺垫。
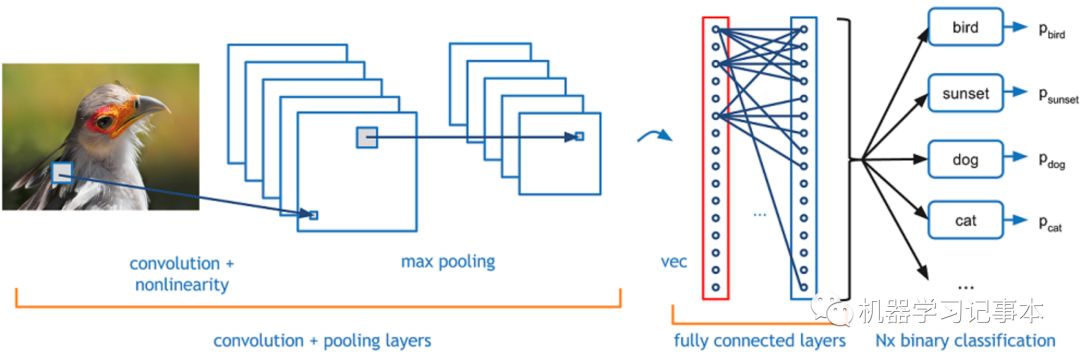
以上面CNN用于图像识别为例,输入为一张图片,输出需要识别出图片是鸟,狗还是猫。典型的CNN主要有3层:
1. 卷积层
对输出数据做卷积操作。上面的图片输入首先转化成RGB对应的数字,然后通过卷积核做卷积,目的是提取输入中的主要特征。卷积过程形象动图请参考斯坦福大学的cs231n的课程例子http://cs231n.github.io/assets/conv-demo/index.html,就是矩阵元素相乘再相加的过程。卷积后的输出,一般会用一个激活函数如ReLU处理。
2. 池化层
卷积后的数据一般比较大,需要用池化层压缩一下。常见的办法是取各个区域的最大值或者平均值。
3. 全连接层
这个就是普通的神经网络方法,把池化层的输出通过全连接,最后通过另一个激活函数比如Softmax处理。
实际工程中,输入可能有多个channel,卷积层有多个卷积核,卷积层和池化层多次联合重复操作。
CNN文本分类
简要回顾了CNN后,回到我们要解决的实际问题上来,如何把CNN用到文本分类中。图像处理很直观,因为图像本身就是二维的,通过卷积从中提取特征容易理解,但文本是一串串的文字,我们要想办法转化成矩阵形式再做卷积处理。下面是YoonKim论文中模型的完整内容,我一步步解释。
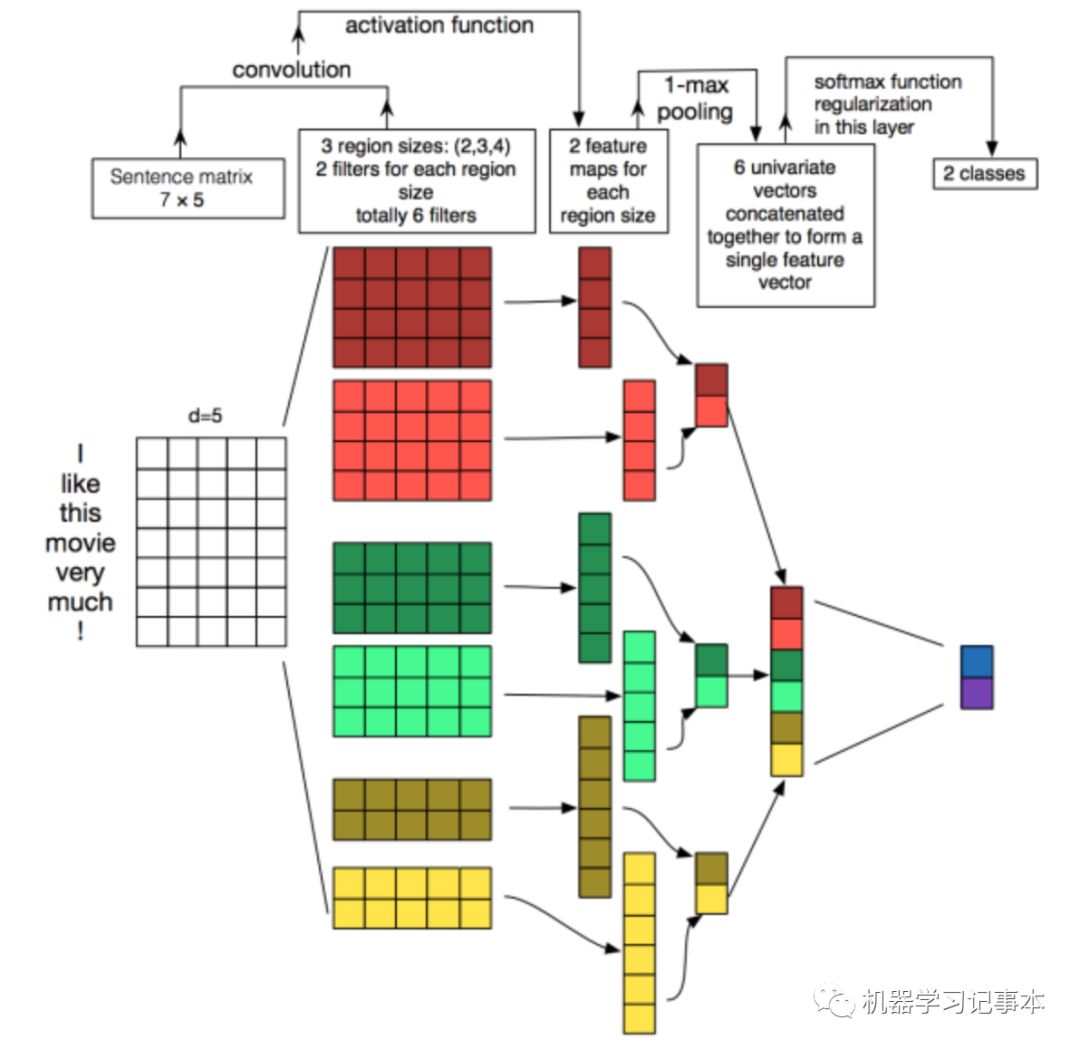
输入文本处理
论文是对句子分类,首先找出最长句子的长度max_len,填充每个句子,使得每个句子长度都为max_len,填充内容为<PAD>。训练词库得到每个词的向量,假设词向量长度为vector_len,则把每个句子转换为一个max_len* vector_len大小的矩阵,其中每一行是该句子中一个字对应的词向量,相当于把整个句子中的字对应的向量堆叠起来。这样每个句子都被转换成了max_len* vector_len大小的矩阵。上图中max_len为7,vector_len为5。
卷积层
选择不同卷积核对输入做卷积操作。上图中有6个卷积核,每两个一组,第一组大小为4*5,第二组3*5,第三组2*5。卷积后得到3组6个输出,第一组大小4*1,第二组5*1,第三组6*1。
池化层
从卷积层6组输出中分别取出最大的数值组成一个大小为6的向量。
全连接层
上图直接对池化层输出通过Softmax处理得到二分类的结果。
以上就是该CNN文本分类模型的主要内容。
项目实际尝试
1. 实现方法
了解完模型后,来看看实际应用。我选取了我项目中8000条开源软件commits的message文本进行实验,其中6000条用于训练模型,2000条用于测试。词向量训练库直接用这8000个文本训练,没有增加额外的词库,词向量长度为200。
卷积核分为3组,每组128个,第一组大小3*3,第二组4*4,第三组5*5。
池化层选择卷积层输出的最大值。
全连接层用了一层全连接。
代码使用Google Tensorflow实现,参考了https://github.com/dennybritz/cnn-text-classification-tf
2. 结果
实验结果需要和我们已经使用的传统机器学习算法进行比较。传统机器学习算法我用了5个算法联合起来的集成算法,这5个算法分别是AdaBoost,GaussianNB,KNeighor,RandomForest,GradientBoost。
开源软件的commits文本里特征有message,committer, files, patch等,传统机器学习算法实现里我把所有这些特征都连在一起作为一个向量进行训练,但是CNN里不适合这样做,因为把所有特征联合在一起再用卷积提取特征不符合逻辑。为了方便比较,我做了3个实验:传统机器学习算法训练commit所有特征,传统机器学习算法训练commit message,CNN训练commit message。这样后两者更具有可比性,因为他们训练的内容一样。
下面是训练性能结果:
Recall | Precision–传统算法-Message only | Precision-传统算法-All features | Precision-CNN-Message only |
0.6 | 0.53 | 0.75 | 0.81 |
以同样的recall值0.6对应的precision进行比较,传统算法只训练commitmessage的查准率为0.53,训练全部特征的查准率为0.75,CNN只训练commitmessage的查准率为0.81。也就是说CNN训练较少的特征比传统学习算法训练全部特征得到的性能更好。
上面只是8000条数据的初步结果,接下来我会考虑使用更多数据,以及如何在CNN中使用所有特征,或者用其他深度学习算法比如RNN进一步改进性能。
