




20 世纪 70 年,关系数据库诞生,一直到 2000 年互联网兴起前,其都是解决所有数据处理问题的“瑞士军刀”,精致而简洁。互联网的繁荣使得数据量加速膨胀,关系数据库扩展性差的缺点被显著放大。为了解决扩展性问题,一些公司选择了保留关系数据库核心能力,采用分库分表结合中间件的方案做替代。另一些公司选择放弃制约关系数据库扩展性的关系模型和事务支持,将数据之间原本固有的约束和关联关系从数据库转移给应用,这样无须再支持标准SQL、Schema、ACID、优化器这些关系数据库的核心要素,通过极简设计换取最大的扩展性和性能,即所谓的 NoSQL。NoSQL 无疑是成功的,因为它满足了当时大数据最迫切的海量数据写入性能和存储问题,在各个场景应用。
谷歌在 2003 年到 2006 年发表了三篇论文 The Google File System、MapReduce:Simplified Data Processing on Large Clusters、Bigtable:A Distributed Storage System for Structured Data 介绍了 Google 如何对大规模数据进行存储和计算。这三篇论文开启了工业界的大数据时代,被称为 Google 的“三驾马车”。紧接着开源社区也出现了 Hadoop、HBase、Cassandra、MongoDB、Solar、ElasticSearch 等大数据组件。这些组件因为没有事务的ACID 和 SQL 引擎,并且在各自的细分领域成功应用,于是这些大数据组件自我标榜为 NoSQL 数据库,以此来区分传统的关系型数据库,甚至曾经被过分宣传,出现过 NoSQL 取代 SQL 数据库的局面。但是随着 NoSQL 数据库的推广, 很快它们的局限性也暴露出来:
局限性
● 不支持SQL。开发人员自己实现复杂的代码,进行聚集分析等。
● 不支持事务的ACID。实现大量代码处理数据不一致。
● 功能不全。HBase、Cassandra、MongoDB、ES等不支持关联,只得使用宽表,引起数据冗余,维护代价高;Hadoop不支持数据的实时增改和索引查询,离线批处理还可以,实时在线处理不行。
● 使用低级查询语言。数据独立性差,灵活性差,维护代价高。
● 缺少标准接口。学习代价一般,应用使用代价高,需要大量“胶水”代码。
● 一个复杂业务系统涉及多个NoSQL组件,需搭配使用。数据冗余大, 整合代价高。
● 人才和成本浪费。企业原先的大多数业务系统都是针对Oracle、SQLServer、MySQL等关系型数据库开发而来,积累了大量的SQL人 才,如果切换到NoSQL数据库,那么企业需要招NoSQL人才或者让原先的SQL人才学习各种NoSQL数据库,这是对人力资源的浪费。另外,原先的业务系统切换到NoSQL数据库,需要做大量的开发,这对开发成本也是一种浪费。
以上这些都是放弃关系模型所必须付出的代价。后来 NoSQL 生态圈也意识到各自的局限性,纷纷借鉴了 SQL 数据库的特性,比如,Hadoop 生态圈基于 MapReduce 推出 Hive,方便使用 SQL 语句做复杂的分析,以及后来的Spark 也有对应的 SparkSQL,Flink 也有对应的 FlinkSQL、HBase、Cassandra、ES 等也有类 SQL 的接口。这就难免招来不少同行的质疑,这些组件明明自我标榜 NoSQL,为什么还采用 SQL 的解决方案?于是 NoSQL 生态圈的拥护者们纷纷出来辩解说 NoSQL 意指 Not Only SQL(不仅仅是 SQL)不是没有 SQL。笔者在此不得不佩服人类语言的博大精深。
谷歌在 2012 年发表了论文 Spanner:Google’s Globally-Distributed Database, 2013 年发表了论文 F1:A Distributed SQL Database That Scales,其中 Spanner 支持二级索引、分布式事务的 ACID 和主从副本的强一致性,F1 具备 SQL 数据库的所有功能(OLTP,OLAP),最初是基于 MySQL 的,后来迁移到 Spanner 上。这证明了 NoSQL 的始作俑者
谷歌自己也回归到 SQL 阵营。人们称这种具备 SQL 数据库所有特性的分布式数据库为NewSQL,称传统的 SQL 数据库为 OldSQL。OldSQL、NoSQL、NewSQL 的关系如 图 7-1 所示。
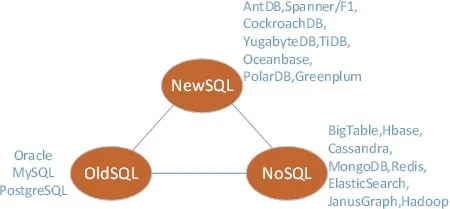
如果说数据库从传统的 SQL 向 NoSQL 发展是分的过程,那么从 NoSQL向 NewSQL 发展就是合的过程。
数据库技术从传统 SQL 发展成为 NoSQL,最后又回归到 SQL 成为NewSQL,不是在走弯路,而是技术发展的必经过程,当初由于分布式事务ACID、数据强一致性、分布式 SQL 优化器和执行器难以实现,所以抛开这些特性重点实现分布式存储和计算,于是产生了 NoSQL,由于 NoSQL 没有标准, 于是诞生了各种各样的 NoSQL 数据库:列族式数据库 HBase、Cassandra;文档型数据库 CouchDB、MongoDB;全文检索数据库 ElasticSearch;图形数据库 Neo4j、JanusGraph,等等,每种 NoSQL 数据库都有各自的优点和适用场景。但是人们对美好事物的追求总是永无止境,希望在这些 NoSQL 数据库上实现完整事务的 ACID 和数据强一致性,并且能够支持 SQL 方便使用,因为SQL 语言是被证明了的最适合数据处理的语言而且有统一标准,于是诞生了NewSQL 分布式数据库。
数据库技术最终回归到 SQL 并不代表 NoSQL 会走向消亡,因为每种NoSQL 数据库都有各自的优点和适用场景,所以每种 NoSQL 数据库都有各自擅长的细分领域。NoSQL 数据库在各自细分领域的蓬勃发展,也给之后NewSQL 分布式数据库的发展提供技术上的借鉴和启发,未来的 NewSQL 分布式数据库必然是融合传统 OLTP 和 OLAP(HTAP)功能基础上,进一步融合各细分领域NoSQL 的特性,并且是存储计算分离的超融合(All In One)型数据库。
