




先上一张官方文档的截图
看起来很复杂,实际还是较简单的
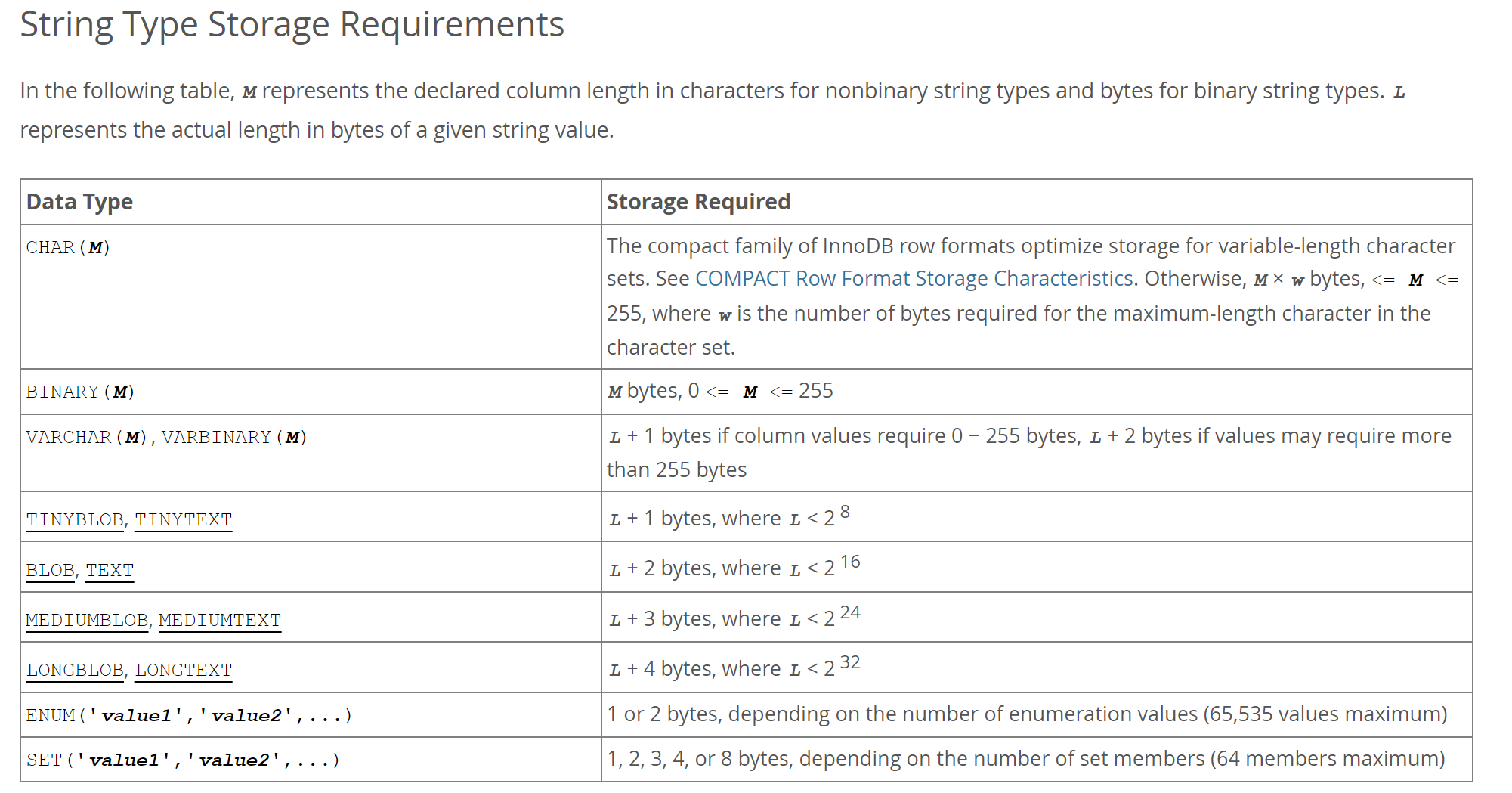
用W来表示1个字符在字符集下的最大占用
比如:utf8为3,utf8mb4就为4
char(M) 所占的空间就是 M*W 字节
varchar(M) 占用空间为两种
1、如果M*W<=255 最大占用空间即为 1 + M*W
2、如果M*W>255 最大占用空间即为 2 + M*W
看到这个文档时。我以为key_len也是按此规则来计算的,实际不是。来看一个实例
drop table stt;
create table stt
( id int not null,
str1 char(10) not null,
str2 varchar(60) not null,
str3 varchar(70) not null,
primary key(id)
) engine = InnoDB default charset = utf8mb4 ROW_FORMAT=COMPACT ;
insert into stt
values(1,'abcd','abcd','abcd');
alter table stt add index idx1(str1),add index idx2(str2),add index idx3(str3);
explain
select 1 from stt where str1 = 'abcd';
explain
select 1 from stt where str2 = 'abcd';
explain
select 1 from stt where str3 = 'abcd';
执行计划1

ken_len = 10*4 = 40 符合上面的公式 M*W
执行计划2

ken_len = 4*60 +2
按照上面公式 我觉得该为 4*60 + 1 = 241 而实际为 4*60 + 2 = 242 说明key_len 始终按最大可能占用的字节来算的
执行计划3

ken_len = 70*4 + 2 = 282 符合上面的公式 M*W + 2
总结:
这个是最后一篇介绍常用类型的空间占用 另两篇请见
日期型
数值型
能计算常用类型的空间占用,就能比较轻松的计算执行计划中的ken_len列的值,在组合索引中,清楚的计算key_len 有助于区分执行计划使用到了组合索引的几列,有助于优化SQL或优化索引。
具体实例可参见我的这篇文章:MySQL 优化实战之关注组合索引的key_len
另外对于字符型字段需要注意的有以下两点
1、varchar类型声明里需要贴近业务需求,不要胡乱声明很大,造成空间浪费
2、在遵守第1条的情况下,有一个例外,就是当你的声明达到255边界的时候,可以跨越它。如果字符集是utf8mb4 那么你声明varchar(60) 就改为varchar(64)吧。这样方便后面DLL可以INPLACE而不是耗时最久的COPY
关于这条的例子可参见我的这篇文章:数据库设计(MySQL)避坑指南
