




问题描述
某客户,2024年2月01 1:26 出现短信告警数据库db1连接不上,由于私网ipc通讯超时 最终导致节点1 asm实例自动重启成功,节点2 asm实例自动重启失败;节点1 db1实例自动重启失败,节点2 2:10 db2实例自动重启成功;8:53启动节点1 db1实例,导致节点2 db2实例被驱逐关闭,节点1支撑业务。
环境信息
数据库:Oracle 12.2.0.1 两节点rac
问题分析
系统日志
节点2 系统Message 日志发现ib1报错其他时间未发现此报错,节点1message未发现此报错:

数据库日志分析
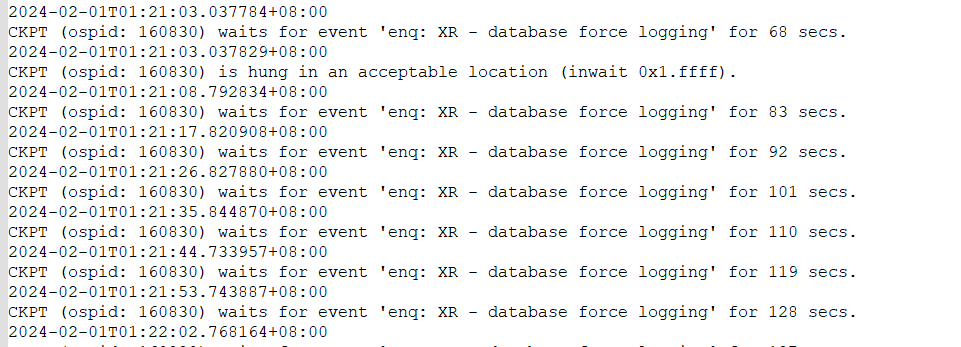
节点1 db alert日志信息:节点1 在2024.2.1 1:21:03 出现问题
节点2 db alert 日志信息:1:23:24 -243s 1:19:21 db2出现问题

asm实例日志
节点1 asm alert日志信息:
1:24:49 日志出现IPC Send timeout,最后实例被LMD0进程中断
节点2 asm alert日志信息:
1:22:51 asm 实例2开始出现异常,1:25 出现IPC Send timeout
集群以及集群进程日志分析
节点2 集群日志:1:23 显示数据库db资源异常
节点1 的crsd日志
1:23 数据库资源处于异常状态
节点2 的crsd日志
1:26 显示gipc异常

查看trace /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_lmon_72890.trc

注:kjxgrrcfgchk: Initiating reconfig, reason=3 表明是通讯故障。
使用ping 命令测试私网是没有问题的
根据上述日志以及各个实例的状态,分析得出,首先1:22:51分节点2 由于私网ipc通讯异常,超过243s无响应,导致节点2 db2实例被进程GEN0 terminated ,之后oracle内部经过节点驱逐机制,节点1 asm实例启动成功,节点2 db2实例启动成功,后续08:53 手动拉起节点1 db1实例,由于私网通讯处于半通讯状态(可以相互ping),oracle节点驱逐机制驱逐杀掉节点2 db2实例,保持节点1 db1实例启动成功。并且从节点2 message 日志发现ib1首次在1:19出现报错,并一直持续报错
综上,数据库集群日志私网ipc通讯异常(间断性访问异常,不是彻底不能访问私网);
主机工程师排查,主机节点2 ib1卡驱动版本存在bug,IPOIB模块中,业务发送线程与linux内核驱动的发送轮询线程互斥保护问题,一旦在内核的轮询线程发送数据的过程中,队列中有半数以上的消息需要发送(如队列长度为128,队列中有64个以上的消息需要发送),此时如果业务线程关闭了socket,低概率导致内核的轮询发送线程停止工作。一旦后续有新的数据发送,则导致数据堆积在发送队列,导致message提示tx队列满的问题。业务表现为部分的IPOIB的业务不通。
解决方案
a、如果网口存在Bond,将系统日志记录的存在故障的端口临时down掉(ifconfig ibx down),临时恢复业务。
查看系统日志中报错的ib网卡端口,手动切换主备,详细步骤如下:
1) 登录故障节点,切换到root用户,运行如下命令检查故障的端口:
cat /var/log/message | grep “transmit timeout”
2)对故障的端口down,使得Bond切换到另外的端口工作
ifconfig ibx(故障端口) down
b、如果是物理网口直接配置使用,只能通过重启服务器快速恢复。
根本解决方案
根据IB网卡厂商Mellanox的建议,升级IB驱动版本到4.7.1以上,并调整网卡队列深度。
