




主题模型
—PCA主成分分析(一)
作者:水...琥珀
编辑:楠楠

目
录
一、数据的特点
二、什么是主成分分析
三、主成分分析的原理
四、主成分分析的python实现
我们在作数据分析处理时,数据往往包含多个变量,而较多的变量会带来分析问题的复杂性。主成分分析(Principal components analysis,以下简称PCA)是一种通过降维技术把多个变量化为少数几个主成分的统计方法,是最重要的降维方法之一。它可以对高维数据进行降维减少预测变量的个数,同时经过降维除去噪声,其最直接的应用就是压缩数据,具体的应用有:信号处理中降噪,数据降维后可视化等。
PCA把原先的n个特征用数目更少的m个特征取代,新的m个特征一要保证最大化样本方差,二保证相互独立的。新特征是旧特征的线性组合,提供一个新的框架来解释结果。接下来分四部分来展开PCA的理论与实践:
• 什么时候用PCA,即数据特点;
• 什么是主成分分析、主成分计算;
• 主成分分析为什么可以,即主成分理论基础;
• python如何快速实现PCA;
一、数据的特点
1.维度灾难
维度灾难,简单来说就是变量的个数多。如果变量个数增加,随之需要估计的参数个数也在增加,在训练集保持不变的情况下待估参数的方差也会随之增加,导致参数估计质量下降。
2.变量关系不一般。
变量关系不一般,指的是变量彼此之间常常存在一定程度的、有时甚至是相当高的相关性,这说明数据是有冗余的,或者说观测数据中的信息是有重叠的,这是我们利用主成分进行降维的前提条件,也可以说这使得变量降维成为可能(观察变量的相关系数矩阵,一般来说相关系数矩阵中多数元素绝对值大于0.5,非常适合做主成分分析,但也不是说小于的就不可以用这种方法)。
在变量个数多,相互的相关性比较大的时候,我们会不会去寻找变量中的“精华”呢?,寻找个数相对较少的综合变量呢?这是我们利用主成分降维的动机。
可参考被博文广传的例子:
•比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余。
•拿到一个数学系的本科生期末考试成绩单,里面有三列,一列是对数学的兴趣程度,一列是复习时间,还有一列是考试成绩。我们知道要学好数学,需要有浓厚的兴趣,所以第二项与第一项强相关,第三项和第二项也是强相关。那是不是可以合并第一项和第二项呢?
二、什么是主成分分析
1.由来
主成分分析(principal component analysis)由皮尔逊(Pearson,1901)首先引入,后来被霍特林(Hotelling,1933)发展了。
2. 描述
主成分分析是一种通过降维技术把多个变量化为少数几个主成分(综合变量)的统计分析方法。这些主成分能够反映原始变量的绝大部分信息,它们通常表示为原始变量的某种线性组合。
那为了主成分的为了是这些主成分所含的信息不互相重叠,应要求他们之间互不相关。
主成分的目的:
(1)变量的降维
(2)主成分的解释(在主成分有意义的情况下)
3.计算步骤
例子:我们简单粗暴直接上例子,我们带着问题看例子,一步一步来。(例子来自《应用多元统计》,王学民老师著)
在制定服装标准的过程中,对128名成年男子的身材进行了测量,每人测得的指标中含有这样六项:身高(x1)、坐高(x2) 、胸围(x3) 、手臂长(x4) 、肋围(x5)和腰围(x6) 。
第一步,对原始数据标准化(减去对应变量的均值,再除以其方差),并计算相关矩阵(或协方差矩阵):

第二步,计算相关矩阵的特征值及特征向量。
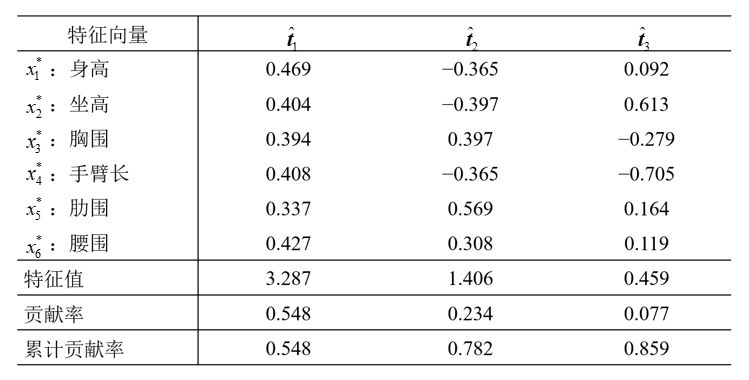
特征值从大到小排列,特征向量和特征值对应从大到小排列。前三个主成分分别为:
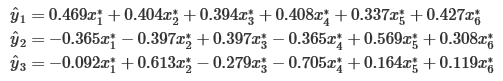
第三步,根据累计贡献率(一般要求累积贡献率达到85%)可考虑取前面两个或三个主成分。
第四步,解释主成分。观察系数发现第一主成分系数多为正数,且变量都与身材大小有关系,称第一主成分为(身材)大小成分;类似分析,称第二主成分为形状成分(或胖瘦成分),称第三主成分为臂长成分。(结合一定的经验和猜想,解释主成分,不是所有的主成分都能被合理的解释)称第一主成分为(身材)大小成分,称第二主成分为形状成分(或胖瘦成分),称第三主成分为臂长成分。可考虑取前两个主成分。由于λ6非常小,所以存在共线性关系:
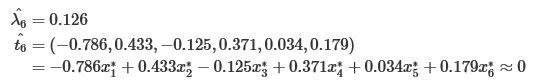
第五步,计算主成分得分。即对每一个样本数据标准化后带入第三步的主成分公式中,计算第一主成分得分,第二主成分得分。
第六步,将主成分可画图聚类,将主成分得分看成新的因变量可线性回归。
例子参考《多元统计分析》王学民老师著,上海财经大学出版社
总结一下PCA的算法步骤:
 。
。1.求出自变量的协方差矩阵(或相关系数矩阵);
2.求出协方差矩阵(或性关系数矩阵)的特征值及对应的特征向量;
3.将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵a(为k*p维);
4.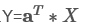 (Y 为k*1维)即为降维到k维后的数据,此步算出每个样本的主成分得分;
(Y 为k*1维)即为降维到k维后的数据,此步算出每个样本的主成分得分;
5.可将每个样本的主成分得分画散点图及聚类,或将主成分得分看成新的因变量,对其做线性回归等。
4.主成分的应用
在主成分分析中,我们首先应保证所提取的前几个主成分的累计贡献率达到一个较高的水平,其次对这些被提取的主成分都能够给出符合实际背景和意义的解释。但是主成分的解释其含义一般多少带有点模糊性,不像原始变量的含义那么清楚、确切,这是变量降维过程中不得不付出的代价。因此,提取的主成分个数m通常应明显小于原始变量个数p(除非p本身较小),否则主成分维数降低的“利”,可能抵不过主成分含义不如原始变量清楚的“弊”。
在一些应用中,这些主成分本身就是分析的目的,此时我们需要给前几个主成分一个符合实际背景和意义的解释,以明白其大致的含义。
在更多的另一些应用中,主成分只是要达到目的的一个中间结果(或步骤),而非目的本身。例如,将主成分用于聚类(主成分聚类)、回归(主成分回归)、评估正态性、寻找异常值,以及通过方差接近于零的主成分发现原始变量间的多重共线性关系等,此时的主成分可不必给出解释。
欢迎热爱数据挖掘的你加入我们的编辑团队,有兴趣后台私聊小编哦,坐等调戏~~~



长按识别二维码关注我们
