




点击上方蓝字关注我们

为促进团队内外的沟通联系,我们Klustron团队的bbs论坛开始上线,欢迎各位同学使用!(链接:https://forum.klustron.com/,或者点击文末“阅读原文”,即可跳转)
点击上方蓝字关注我们
为促进团队内外的沟通联系,我们Klustron团队的bbs论坛开始上线,欢迎各位同学使用!(链接:https://forum.klustron.com/,或者点击文末“阅读原文”,即可跳转)



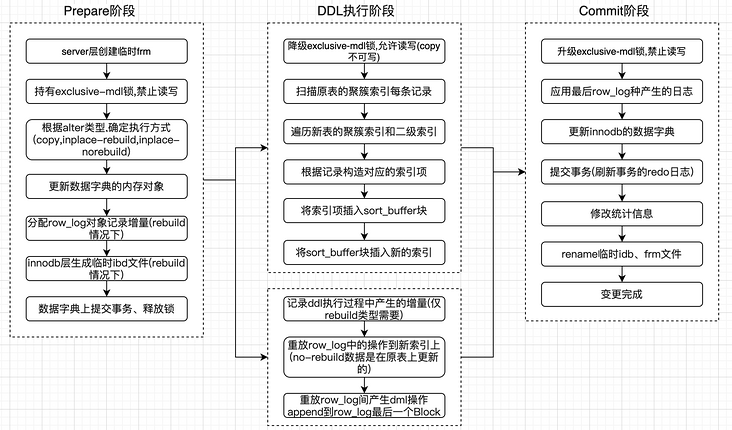
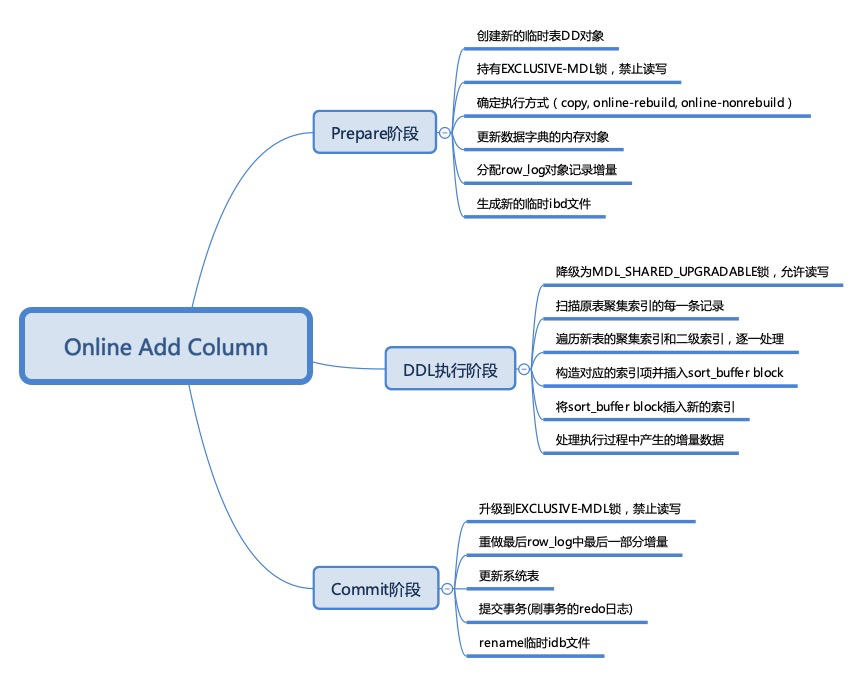
在MySQL 5.5之前只支持Copy方式的DDL操作,需要拷贝数据,而且不能并发写正在变更的表; MySQL 5.5开始支持Inplace方式的DDL操作,对于支持inplace的DDL操作,无需拷贝数据,直接在原有的表数据上面进行变更,但仍然不可并发写; MySQL 5.6开始支持Online DDL,实现大部分DDL操作时可并发读写,极大减少了DDL操作对于系统的整体影响; MySQL 8.0开始支持instant DDL,通过只修改数据字典而不修改数据的方式实现DDL操作的瞬时完成。


大表的DDL执行过程太长,尤其是复制场景; 执行部分DDL需要成倍的磁盘空间; 部分DDL执行过程会消耗大量的IO,内存和CPU资源; 在复制场景下,DDL在从机执行需要长时间才能与主机同步;
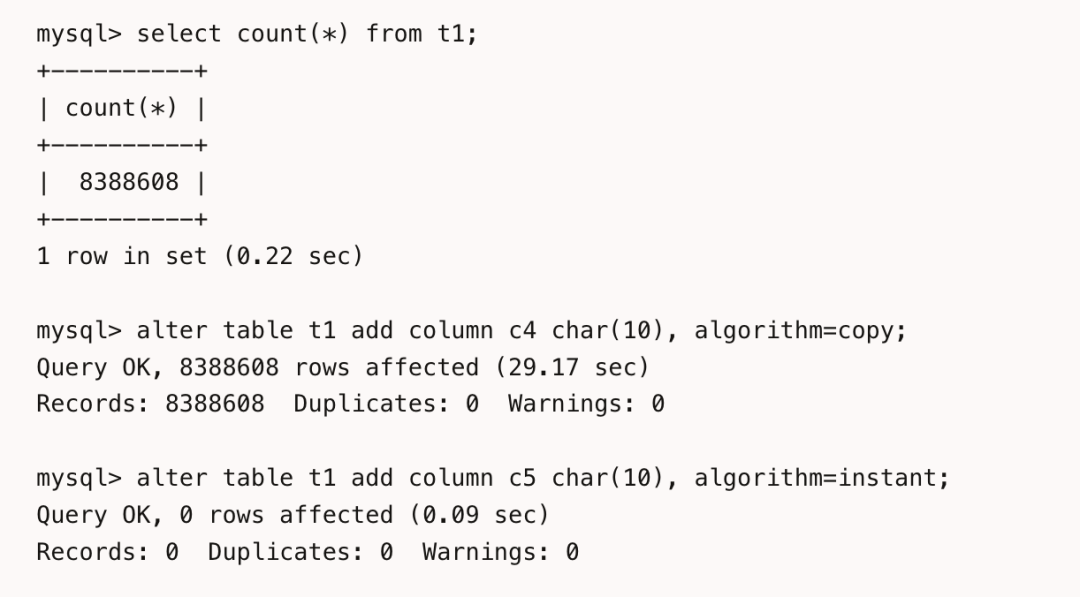
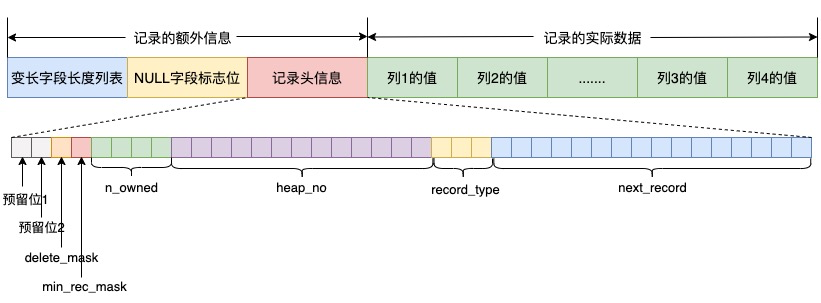
只修改数据字典信息,不拷贝和修改任何历史数据; 通过增加和设置标识位来判断新旧格式的数据行; MySQL 8.0.29后通过设置数据行的版本号来判断数据行对应的结构。 只修改数据字典信息,不拷贝和修改任何历史数据; 通过增加和设置标识位来判断新旧格式的数据行; MySQL 8.0.29后通过设置数据行的版本号来判断数据行对应的结构。
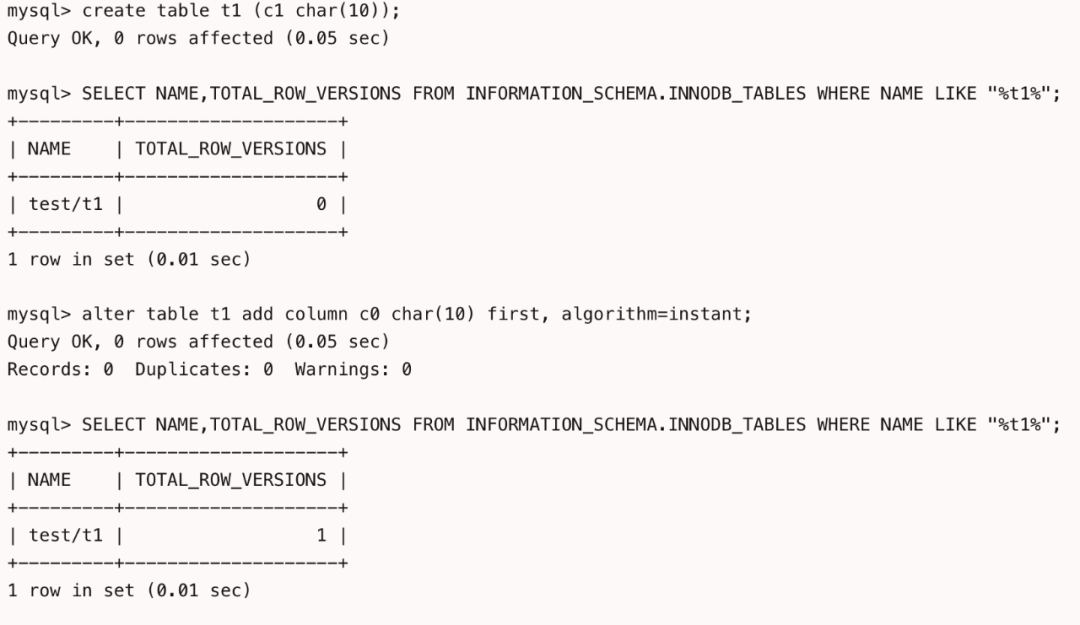
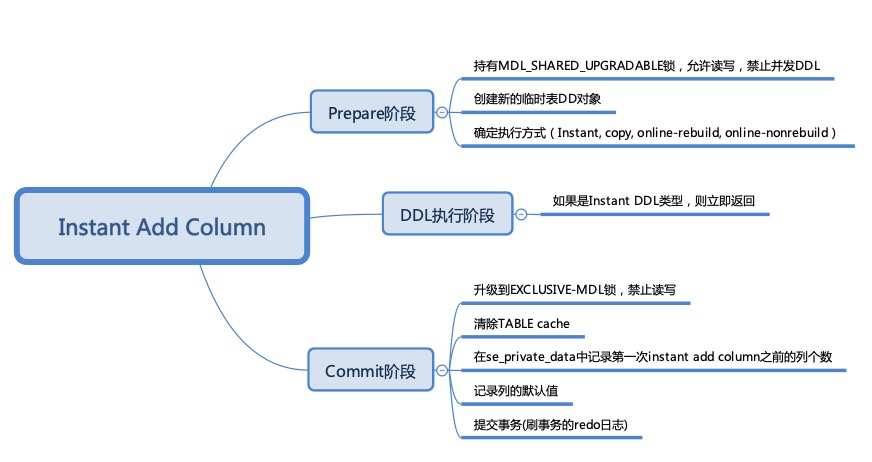
通过设置info bits的位来标识是否有新的数据格式; 通过增加字段数量信息来保存当前数据行的字段数量信息; MySQL 8.0.29后通过设置数据行的版本号来判断数据行对应的结构。
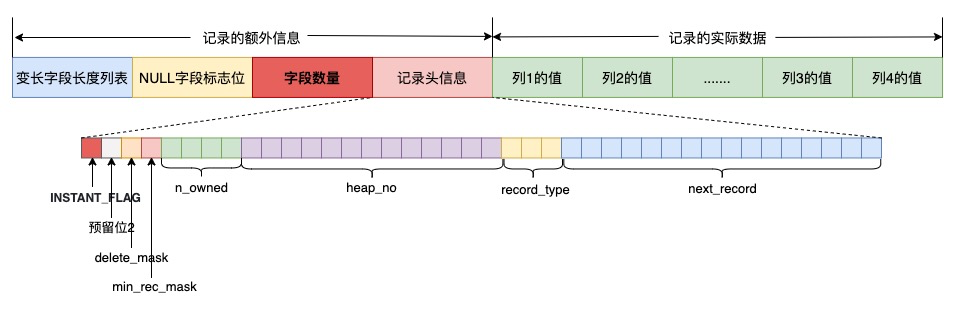
插入:按照新的格式插入 查找:根据标识位判断是新或旧版本数据 更新:更新为新格式数据 删除:无变化

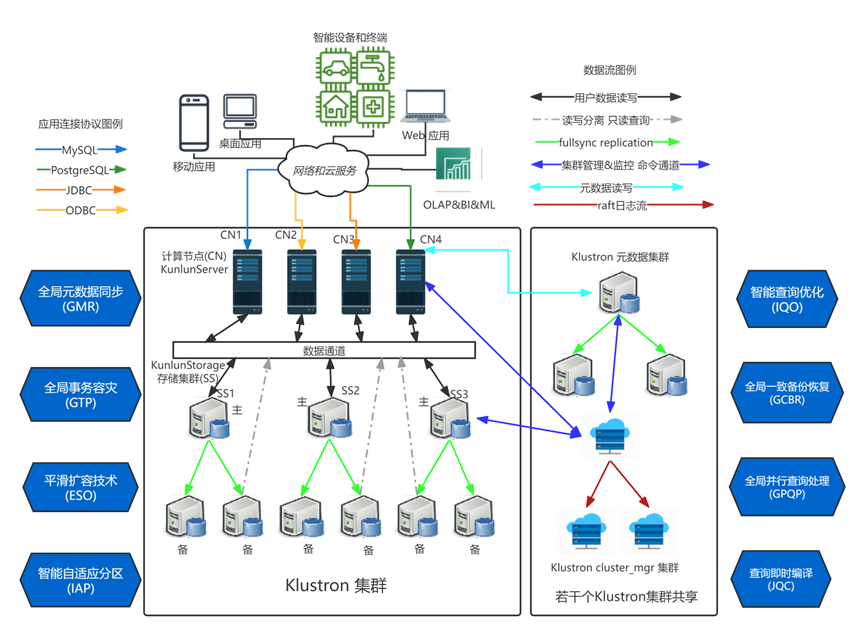
计算层(Klustron-server):多个PostgreSQL实例构成的计算节点负责接受验证应用软件端的连接请求,以及从已经建立的连接中接受SQL查询请求,执行请求,然后返回查询结果; 存储层(Klustron-storage): 三个或者更多个MySQL8.0实例构成的存储节点组成一个存储集群(storage shard,简称shard),每个shard 存储着一部分用户表或者表分区; 元数据集群存储着Klustron 集群的元数据包括拓扑结构、节点连接信息、DDL日志,commit log,和其他集群管理日志等; cluster_mgr集群负责维护正确的集群和节点状态,实现集群管理、集群逻辑备份和恢复, 集群物理备份和恢复、水平弹性伸缩等功能。
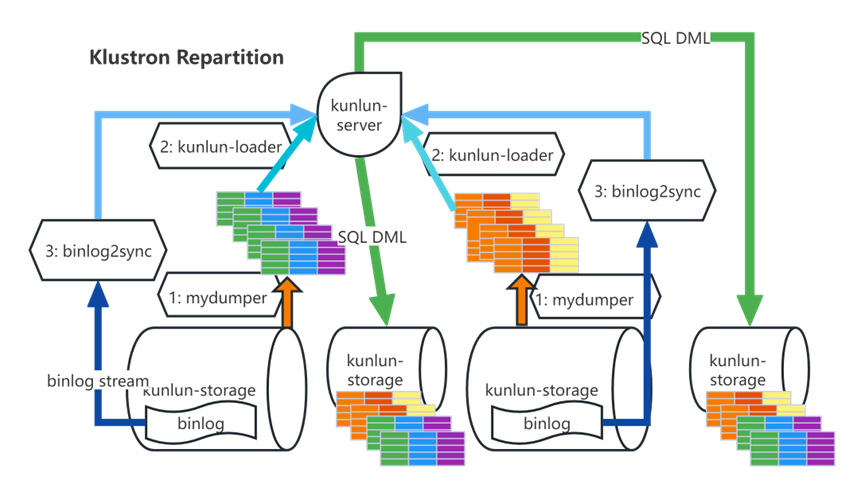
导出表全量数据:node_mgr 调用 mydumper 将源表数据 dump 出来并传输数据文件到计算节点所在服务器; 加载表全量数据:node_mgr调用kunlun_loader工具把源表dump全量数据灌入目标表中; binlog catch-up:node_mgr根据dump时各个shard上binlog起始位置记录调用binlog2sync工具,binlog2sync 工具从该位置点开始dump binlog事件; rename源表和目标表:binlog2sync工具快速将剩余的binlog同步完,然后再将目标表rename成源表名,业务恢复正常使用。
Online DDL的增强和优化(并行化实现性能优化等) Transactional DDL(实现DDL的事务性,而不仅仅是原子性) Instant DDL的增强与优化(实现更多DDL的Instant方式执行)
DDL的并行化改造

点击上方观看视频回放
往期推荐
文章转载自KunlunBase 昆仑数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
