




本篇介绍PawSQL优化引擎中的COUNT标量子查询重写优化,从正文可以看到,通过此重写优化,SQL性能的提升超过1000倍!
本篇属于高级SQL优化专题中的一篇,高级SQL优化系列专题介绍PawSQL优化引擎的优化算法原理及优化案例,欢迎大家订阅。
问题定义
在日常开发中,有部分开发人员使用关联标量子查询来进行`是否存在`的判定,譬如下面的SQL查询有订单的用户列表,
select * from customerwhere ( select count(*) from orderswhere c_custkey=o_custkey) > 0
这类查询有比较严重的性能问题,它需要对外表的每一条记录,进行一次聚集运算。从上面SQL的执行计划可以看到,它的执行时间为4820.015 ms.
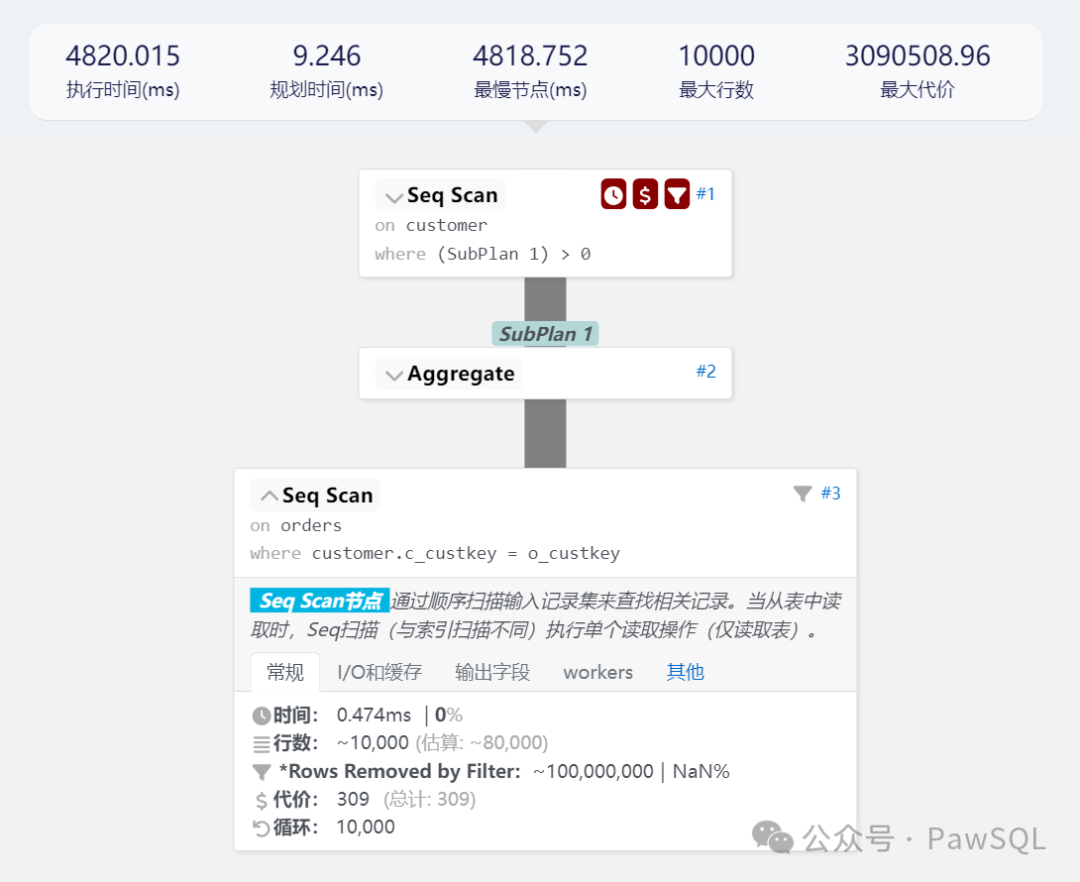
Seq Scan on customer (cost=0.00..3090818.00 rows=3333 width=181) (actual time=3.944..4819.230 rows=1251 loops=1)Filter: ((SubPlan 1) > 0)Rows Removed by Filter: 8749SubPlan 1-> Aggregate (cost=309.03..309.04 rows=1 width=8) (actual time=0.478..0.478 rows=1 loops=10000)-> Seq Scan on orders (cost=0.00..309.01 rows=8 width=0) (actual time=0.421..0.474 rows=1 loops=10000)Filter: (customer.c_custkey = o_custkey)Rows Removed by Filter: 10000Planning Time: 9.246 msExecution Time: 4820.015 ms
解决方案
更好的写法是使用EXISTS子查询,或是IN子查询,如下所示:
select * from customerwhere exists(select 1 from orderswhere c_custkey=o_custkey)
或
select * from customerwhere c_custkey in (select o_custkey from orders)
它们的执行计划是这样的:
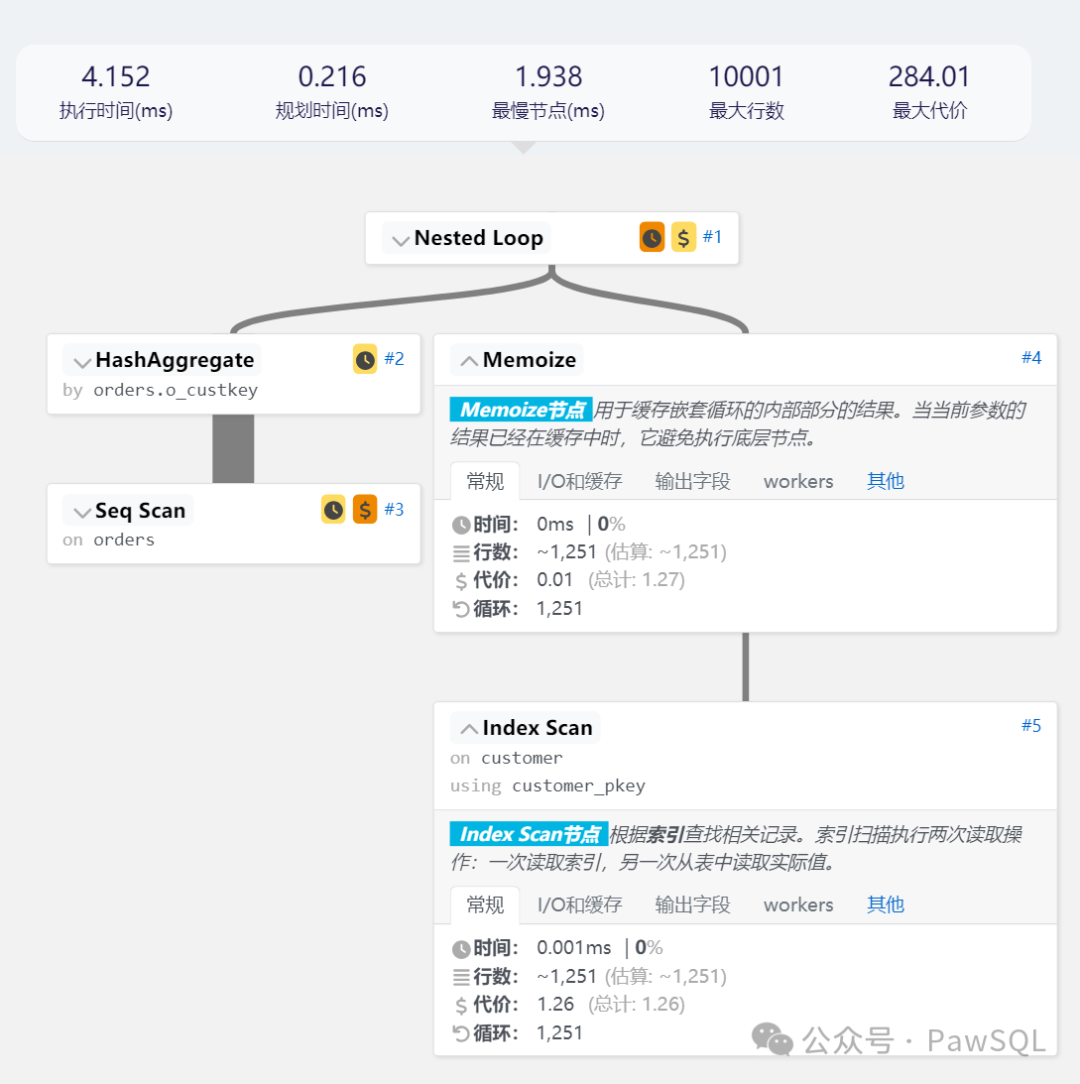
Nested Loop (cost=309.31..533.68 rows=1251 width=181) (actual time=1.588..3.615 rows=1251 loops=1)-> HashAggregate (cost=309.01..321.52 rows=1251 width=4) (actual time=1.577..1.676 rows=1251 loops=1)Group Key: orders.o_custkeyBatches: 1 Memory Usage: 129kB-> Seq Scan on orders (cost=0.00..284.01 rows=10001 width=4) (actual time=0.007..0.469 rows=10001 loops=1)-> Memoize (cost=0.30..1.27 rows=1 width=181) (actual time=0.001..0.001 rows=1 loops=1251)Cache Key: orders.o_custkeyCache Mode: logicalHits: 0 Misses: 1251 Evictions: 0 Overflows: 0 Memory Usage: 348kB-> Index Scan using customer_pkey on customer (cost=0.29..1.26 rows=1 width=181) (actual time=0.001..0.001 rows=1 loops=1251)Index Cond: (c_custkey = orders.o_custkey)Planning Time: 0.216 msExecution Time: 4.152 ms
可以看到改写之后的执行时间从4820.015ms降低到4.152ms,性能提升超过1000倍。
往期文章精选
更多关于SQL优化的文章,请订阅高级SQL优化专题。
关于PawSQL
PawSQL专注数据库性能优化的自动化和智能化,支持MySQL,PostgreSQL,Opengauss等,提供的SQL优化产品包括
PawSQL Cloud,在线自动化SQL优化工具,支持SQL审查,智能查询重写、基于代价的索引推荐,适用于数据库管理员及数据应用开发人员,
PawSQL Advisor,IntelliJ 插件, 适用于数据应用开发人员,可以IDEA/DataGrip应用市场通过名称搜索“PawSQL Advisor”安装。
关注PawSQL公众号获取更多精选内容
文章转载自PawSQL,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
