




作者介绍
马晨阳,一位对开源充满热情的小白,目前任职于中通快递中台研发部,主要负责订单,运单域海量数据下的实时业务流程的开发工作,Apache ShardingSphere Collaborator,GithubId: TherChenYang
前言
Apache ShardingSphere 作为 Apache 顶级开源项目,拥有开放且活跃的社区,许多小伙伴想要参与到项目的贡献中,却又无从下手,本文将带大家了解如何参与到 Apache ShardingSphere 的 SQL 解析任务中,完成解析任务之前我们需要对antlr语法有一些简单的了解,笔者在完成解析任务时,参考了一些文档,想深入的学习了解的同学可以参考文末的相关文章。
安装 Antlr 插件
我们在验证Antlr的解析结果时,使用IDEA Antlr插件可以更方便快捷,这里我们首先在IDEA中搜索对应的插件并完成安装工作。
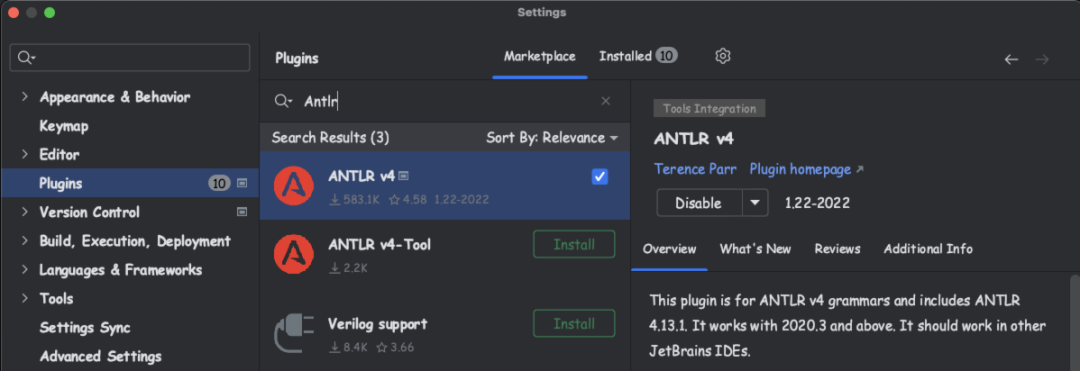
完成插件的安装之后,我们可以找到shardingsphere-parser-sql-mysql 模块下的src/main/antlr4/org/apache/shardingsphere/sql/parser/autogen/MySQLStatement.g4文件进行验证,这时候我们打开这个文件的时候发现文件有很多报错。
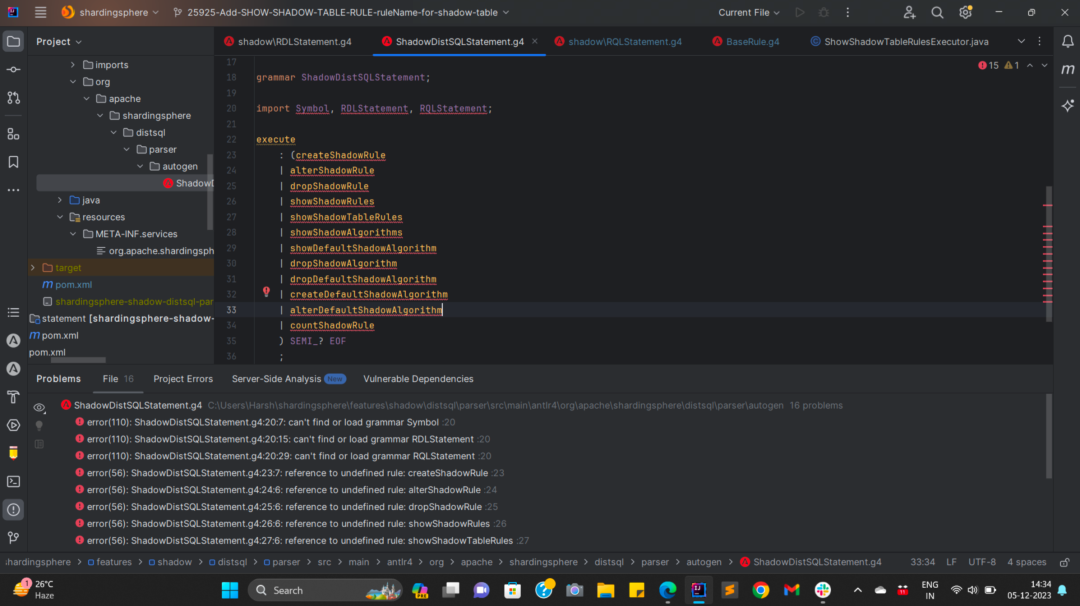
这是因为没有配置MySQLStatement的Import关系,这时候我们在MySQLStatement文件上点击鼠标右键,选择Configure ANTLR,将parser/sql/dialect/mysql/src/main/antlr4/imports/mysql目录配置在Location of imported grammars中。

这时候我们在execute中点击右键选择Test Rule execute,然后选择简单SQL进行验证,如果出现下图效果 这表示我们的配置正确,我们的安装完成,对这部分内容有问题的可以参考文末文章 IDEA 中 Antlr 的安装与使用。
认领解析 Issue
如果我们打算参与对应 Issue 的修复工作,首先我们需要在 Issue 下方留言,留言内容示例:Hi,please assign this issue to me. Thanks you.。由于 Apache ShardingSphere 是一个国际化的社区,因此我们需要通过英文进行交流。社区同学看到你的留言后,会将对应的 Issue 指派给你。可以参考如下的 issue 和 pr 进行认领和完成任务。
示例 Issue: https://github.com/apache/shardingsphere/issues/30253
示例 PR: https://github.com/apache/shardingsphere/pull/30258
验证 SQL
接下来,我们便从之前笔者已经提交的一个 Issue 作为示例为大家讲解整个流程,首先我们来看 issue 中的其中一个 SQL Case。
SELECT PersonName, FriendsFROM (SELECTPerson1.name AS PersonName,STRING_AGG(Person2.name, '->') WITHIN GROUP (GRAPH PATH) AS Friends,LAST_VALUE(Person2.name) WITHIN GROUP (GRAPH PATH) AS LastNodeFROMPerson AS Person1,friendOf FOR PATH AS fo,Person FOR PATH AS Person2WHERE MATCH(SHORTEST_PATH(Person1(-(fo)->Person2)+))AND Person1.name = 'Jacob') AS QWHERE Q.LastNode = 'Alice';
由于有些 Issue 中的 SQL Case 是从官网自动抓取而来,所以 SQL Case 本身的正确性也有待我们验证,这里我们第一步要做的就是验证该 SQL 在对应的单机数据库上是否能正常解析。在 Issue 中,一般会说明 SQL Case 的来源,大多数来源于官网,官网会给出对应的建表语句与 Insert 语句,我们完成表构建后,测试当前 SQL Case 是否能正常运行。

当我们在单机数据库验证无误后,接下来我们要做的就是验证这个 SQL 是否能被Apache ShardingSphere正确解析,我们使用Antlr插件对这条 sql 进行验证,验证结果如下:

在这里,我们发现在解析中,对sql projection的解析不正确,只解析出两个projection是明显错误的,随后我们观察到解析树中最后对STRING_AGG的解析为regularFunciton,这时候我们在 g4 文件中找到对应的regularFunction的语法定义:
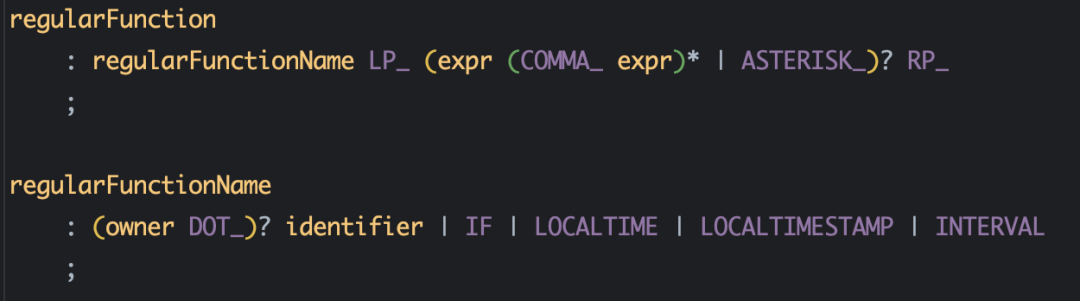
我们来分析这段语法规则,通过前言的文章对antlr语法的了解,我们不难发现,这里的定义即为,以regularFunctionName开头,括号中为多个expr表达式组合,每个expr表达式用COMMA_即逗号进行分割,这时候我们在回看case中的sql,我们发现其中一部分为:
STRING_AGG(Person2.name, '->') WITHIN GROUP (GRAPH PATH) AS Friends
就是这部分函数内容,导致我们解析失败,此时我们定位到了解析 sql 失败的问题,我们便完成了我们解析工作的第一部分内容。
纠正解析语法
在我们定义到问题之后,我们便要对我们的g4文件进行相应的调整,位置位于 parser/sql/dialect/sqlserver 中的 antlr-4 目录下,以支持我们上述的sql case,此时我们需要在SQLServer官方文档中找到上述的定义内容,上述内容的定义链接为:https://learn.microsoft.com/zh-tw/sql/relational-databases/graphs/sql-graph-shortest-path?view=sql-server-ver16#for-path,官方文档中关于语法的定义规则可以参考 Transact-SQL 语法惯例。
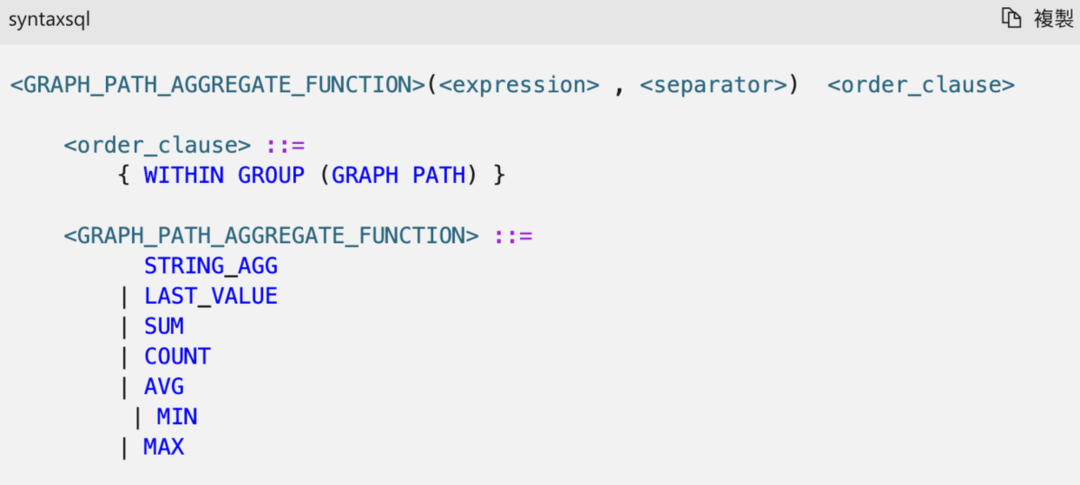
分析语法规则,我们可以得到,除了基础的functionName部分,这里还跟着order_clause部分,这就是为什么我们在g4文件中对标准函数的定义无法解析此函数,可见这个函数在SQLServer中是非标准函数,所以我们需要将此函数的定义根据官方文档的规则添加到我们的g4文件中,在g4文件中我们发现已经存在了specialFunction的语法定义,我们只需要将上述部分补充到我们的specialFunction中,相关补充内容如下(修改时需遵循 G4 开发规范):
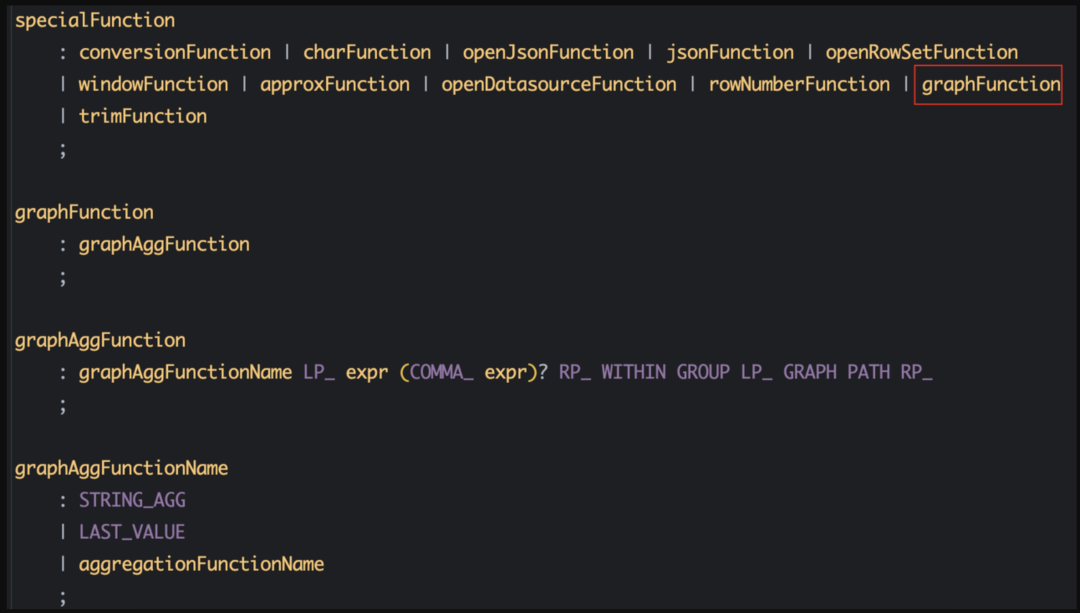
根据官方文档可以得知,这是SQLServer中独特的关于图形路径的函数,所以这里我们定义graphFunction并对方法内容进行补充,主要包含方法名graphAggFunctionName,由一些聚合函数的常量所定义,变量名expr,两个变量之间用逗号隔开,排序规则order_clause由常量WITHIN GROUP (GRAPH PATH)所定义,对语法定义完成修改后,我们重新利用插件进行测试,观察是否解析正常,这时候我们已经能看到语法树已经包含了所有的语法部分,第二部分我们就已经大功告成。
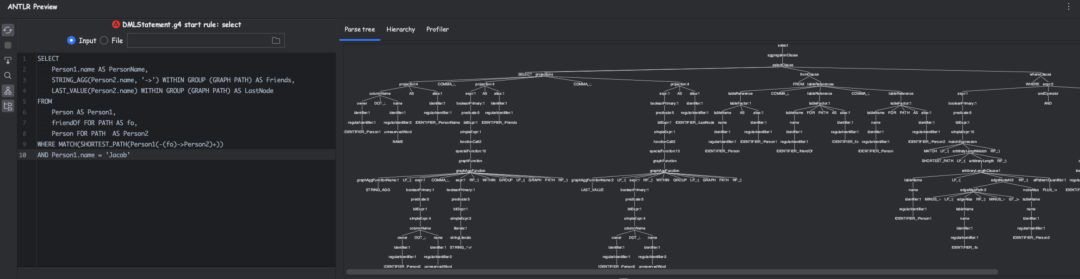
调整解析器
当我们完成语法树的调整之后,接下来,我们要做的就是保证我们的语法树可以正确的解析映射到我们预先定义的类中,了解过Antlr的朋友可以知道,Antlr中可以采用两种模式对语法树节点进行遍历,一种是访问器模式(Vistor),一种是监听器模式(Listener),这部分知识可以通过文末参考文章进行补充。
Apache ShardingSphere中采用的是访问器模式,所以接下来我们就需要调整SqlServer的访问器,位置位于 parser/sql/dialect/sqlserver 的 vistor 目录下,以保证各个访问节点能正确映射,我们首先需要找到SpecialFunction这个节点的访问方法,因为我们在语法树中对SpecialFunction进行了扩充,所以这里的访问方法我们也需要定义如何访问我们扩充的节点,在Apache ShardingSphere中,对方法的定义是FunctionSegment,所以我们要做的就是首先重写visitGraphFunction方法,并将其补充进入visitSpecialFunction,有了这个思路之后,我们的实现也比较简单,如下:
@Overridepublic final ASTNode visitSpecialFunction(final SpecialFunctionContext ctx) {if (null != ctx.conversionFunction()) {return visit(ctx.conversionFunction());}if (null != ctx.charFunction()) {return visit(ctx.charFunction());}if (null != ctx.openJsonFunction()) {return visit(ctx.openJsonFunction());}if (null != ctx.openRowSetFunction()) {return visit(ctx.openRowSetFunction());}if (null != ctx.jsonFunction()) {return visit(ctx.jsonFunction());}if (null != ctx.windowFunction()) {return visit(ctx.windowFunction());}if (null != ctx.approxFunction()) {return visit(ctx.approxFunction());}if (null != ctx.graphFunction()) {return visit(ctx.graphFunction());}if (null != ctx.trimFunction()) {return visit(ctx.trimFunction());}return new FunctionSegment(ctx.getStart().getStartIndex(), ctx.getStop().getStopIndex(), ctx.getChild(0).getChild(0).getText(), getOriginalText(ctx));}@Overridepublic ASTNode visitGraphFunction(final GraphFunctionContext ctx) {if (null != ctx.graphAggFunction()) {return visit(ctx.graphAggFunction());}return new FunctionSegment(ctx.getStart().getStartIndex(), ctx.getStop().getStopIndex(), ctx.getChild(0).getChild(0).getText(), getOriginalText(ctx));}@Overridepublic ASTNode visitGraphAggFunction(final GraphAggFunctionContext ctx) {return getFunctionSegment(ctx.getStart().getStartIndex(), ctx.getStop().getStopIndex(), ctx.graphAggFunctionName().getText(), getOriginalText(ctx), ctx.expr());}
添加测试 Case
在完成语法文件和访问器的调整后,我们的解析调整部分就已经完成了,接下来我们需要测试我们的调整对之前已存在的sql case的解析是否产生影响,以及对新的sql case是否能正确解析,Apache ShardingSphere的SQL解析无需真实的测试环境,开发者只需要定义好待测试的SQL,以及解析后的断言数据即可。
SQL 数据
开发者只需要在shardingsphere-test-it-parser模块中添加待测试的 SQL 即可,位置位于test/it/parser/src/main/resources/sql/supported/${SQL-TYPE}/*.xml
断言数据
断言的解析数据保存在 test/it/parser/src/main/resources/case/${SQL-TYPE}/*.xml 在 xml 文件中,可以针对表名,token,SQL 条件等进行断言
测试部分的内容其实还是比较复杂的,Apache ShardingSphere利用了junit5中的参数化测试,利用参数Provider读取SQL数据,然后调用访问器对SQL进行解析,解析完成后,使用SQLStatementAssert对解析结果与实现编写好的断言结果进行比较,如果解析结果中的投影,表名,文本与断言中的预设一致,表示测试通过。
这里我们还是用我们的sql case进行举例说明:
SELECT PersonName, FriendsFROM (SELECTPerson1.name AS PersonName,STRING_AGG(Person2.name, '->') WITHIN GROUP (GRAPH PATH) AS Friends,LAST_VALUE(Person2.name) WITHIN GROUP (GRAPH PATH) AS LastNodeFROMPerson AS Person1,friendOf FOR PATH AS fo,Person FOR PATH AS Person2WHERE MATCH(SHORTEST_PATH(Person1(-(fo)->Person2)+))AND Person1.name = 'Jacob') AS QWHERE Q.LastNode = 'Alice';
首先,我们添加 sql 到 test/it/parser/src/main/resources/sql/supported/dml/select.xml 文件中,这个文件中存储的都是我们需要测试解析的 sql,通过db-types标签区分不同的数据库类型的方言。
随后,我们需要在 test/it/parser/src/main/resources/case/dml/select.xml 文件中添加对应的 SQL Case 的断言,对于查询语句的断言主要包含以下几部分:
projections 标签:
▪投影,表示我们查询语句需要查询的字段,方法等:
例如column-projection表示的是字段投影,即查询的内容是表中的某个字段;
例如expression-projection表示的是表达式投影,即查询的内容可能是数据库中的某个函数。

▪上述的 SQL Case 中查询了 PersonName, Friends 字段,可以看到projections主要对字段名称,字段在 SQL 中的位置进行了断言判断。
from标签:
▪表示语句中查询的来源:
例如subquery-table表示的是我们查询的来源是子查询;
例如simple-table表示我们查询的来源是数据库中的某张表;
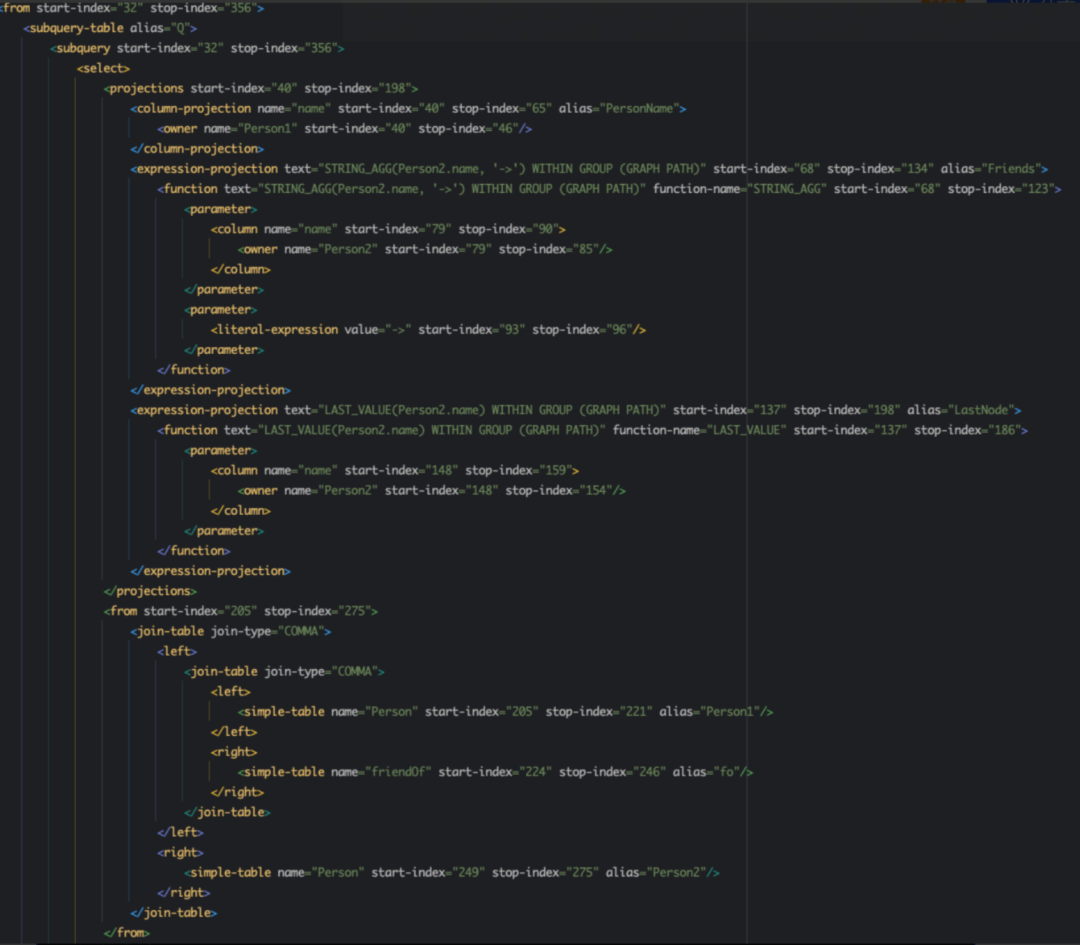
where标签:
▪表示语句中的查询条件;
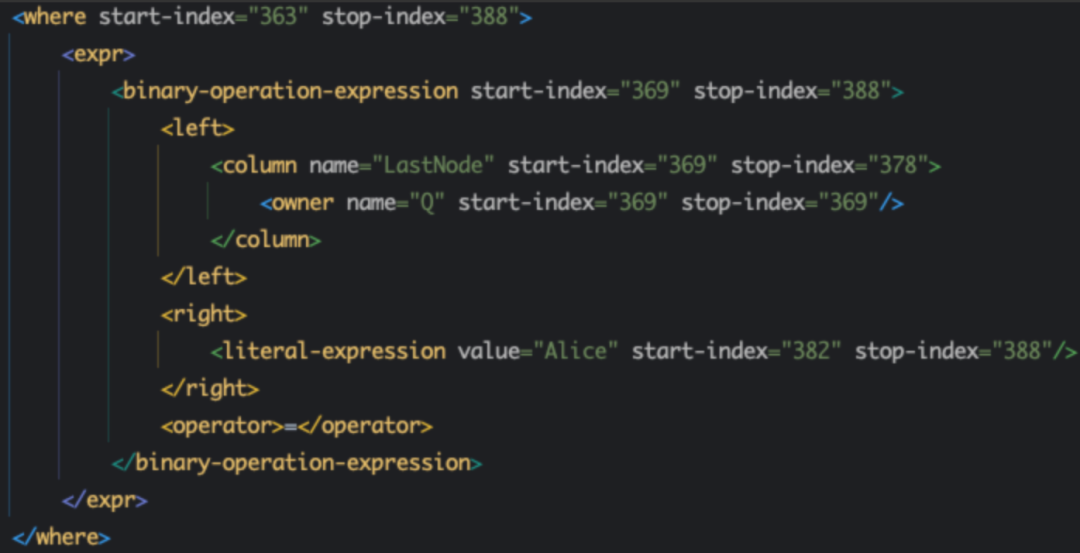
▪在上述的 SQL Case 中,Where条件是一个二元运算表达式,即Q.LastNode = 'Alice',所以我们用了expr表达式标签中的binary-operation-expression标签,并定义了表达式左右的结构。
上述标签的定义基本与相应语法下的Statement一一对应,标签的定义可以参考org/apache/shardingsphere/test/it/sql/parser/internal/asserts包;
设置好上面两类数据,开发者就可以通过 test/it/parser 下对应的测试引擎org.apache.shardingsphere.test.it.sql.parser.internal.InternalSQLParserIT#assertSupportedSQL启动 SQL 解析的测试了,如果测试通过,表示我们的定义无误。
提交 PR
当我们走到这一步的时候,就表示我们对应Issue已经被我们拿下了,我们这时候就可以提交相应PR完成对应的Issue的修复,这部分的流程可以参考贡献者指南,当你的 PR 被合并的时候,这时候,恭喜您已经成为了 Apache ShardingSphere 的官方贡献者!最后,希望大家每一个人都能真正体会到开源的快乐,让自己可以持续的快乐写自己喜欢的代码!!
目前Apache ShardingSphere项目中的解析任务正在火热进行中,了解 SQL 解析能为深入理解内核原理打好基础,欢迎对 ShardingSphere 开发感兴趣的朋友参与,未提交 PR 的 issue 都可以认领,欢迎大家加入Apache ShardingSphere这个大家庭!
参考文章
Antlr 相关
ANTLR 基础入门
https://strongduanmu.com/blog/introduction-to-antlr.html
IDEA 中 Antlr 的安装与使用
https://blog.csdn.net/qq_37771475/article/details/106387201
Antlr 基本概念解析
https://blog.csdn.net/qq_37771475/article/details/106426327
如何编写语法文件
https://blog.csdn.net/qq_37771475/article/details/106528661
监听器、访问器与语法分析树的标注
https://blog.csdn.net/qq_37771475/article/details/106546742
Antlr 实战 CSV
https://blog.csdn.net/qq_37771475/article/details/106546854
Apache ShardingSphere 官方文档
贡献指南
https://shardingsphere.apache.org/community/cn/involved/contribute/
开发规范
https://shardingsphere.apache.org/community/cn/involved/conduct/code/
SQL 解析
https://shardingsphere.apache.org/document/current/cn/dev-manual/sql-parser/
觉得文章对你有帮助,欢迎评论转发点赞~
如何加入 ShardingSphere 社区成为贡献者?
社区答疑:积极在社区中进行答疑、分享技术、帮助群内的其他开源爱好者解决问题。
代码贡献:社区整理了简单且容易上手的任务,非常适合新人做代码贡献。可以查阅新手任务列表:
https://github.com/apache/shardingsphere/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22%2Cdiscussion+no%3Aassignee
内容贡献:发布 ShardingSphere 相关的内容,比如安装部署教程、使用经验、案例实践等,形式不限,欢迎扫码投稿给社区助手。
社区布道:积极参与社区活动、成为社区志愿者、帮助社区宣传、为社区发展提供有效建议等。
官方文档贡献:发现文档的不足、优化文档,持续更新文档等方式参与社区贡献。通过文档贡献,让开发者熟悉如何提交 PR 和真正参与到社区的建设。

长按识别回复“志愿者”了解更多吧~
关于 Apache ShardingSphere
Apache ShardingSphere 是一款分布式 SQL 事务和查询引擎,可通过数据分片、弹性伸缩、加密等能力对任意数据库进行增强。
点击阅读原文了解更多~
